



Testing Data-driven Microservices
Last Updated on November 2, 2020 by Editorial Team
Author(s): Oryan Omer
Programming
Testing always opens a lot of questions, which cases to test? what are the edge cases? Which testing platform to use..etc.
There isn’t a single answer to any of those questions.
But when it comes to testing microservices, the level of complexity is raised up a notch. As they often cater to massive batches of data that are very varied in their nature. Besides, microservices architecture requires the data to be passed around between components (MQ, DataBase…), which can cause erosion and damages that are hard to detect — i.e.: when the data streams into MQ between microservices and gets rounded, or casting error occurs which causes “silent” issues. In this sense, the integrity of the data is another challenge to be added to the ones of velocity and diversity.
What’s more, data services are commonly performing a lot of computational functions, i.e.: Min, Max, Chi-Square, Log loss, Std,…While working with massive batches and calculating those computational functions, errors start to appear on granular parts of the data.
Moreover, While working in microservices architecture we want to ensure our application integrity. Working with microservices required to pass the data between a lot of components(MQ, DataBase…), which cause sometimes data damages without we even know.
An example of it could be when data stream into MQ between microservices and data gets rounded or casting error which causes uncaught issues.
Altogether, these errors are so hard to find that selecting the right edge cases at the testing stage becomes a mission (almost) impossible. This is what I want to address, and attempt to simplify here.
Let’s talk about an amazing tool using by most data science teams today called Jupyter Notebook. The tool offers an efficient interface for data analysis and exploration through interactive visualization. While working with this tool and implementing all the computational functions inside the Jupyter Notebook, I have found it much easier to select edge cases as they are clear, and almost effortlessly visible.
A concrete example of the use of Jupyter Notebook for testing
In the example selected below, we are going to review for testing the data microservices based on Jupyter Notebook. In this instance, we calculated all the computational functions inside the Notebook and compared them to the microservices results stored in the DataBase, making it easy to detect and fix any discrepancies in the results.
After writing the testing notebooks, the testing notebook should be integrated with the CI, to avoid running the tests manually on a daily basis.
One cool framework to run the notebook as a part of the CI part is “Papermill”, a great tool for parameterizing and executing Jupyter Notebooks.
It allows you to run a notebook using CLI and save the notebooks outputs for diagnosing it later.
Last, we can configure the testing notebooks to send notifications if there are some gaps in the results of the notebooks to our slack channel and we made this testing pipe fully automated.
Diagram of the whole pipeline:
In the graph, one can see that Jenkins triggers the CI to start the Papermill tool, which runs all the testing Jupyter notebooks. Once the notebooks are done running, their outputs are stored in AWS S3, and the notebook's results (passed or failed) are sent to Slack.
After understanding the whole architecture, let mark the benefits of testing using the Jupyter notebook:
V Runs over a massive batch of data.
V Runs as part of the CI and ensures application integrity.
V Supports prompt diagnoses and data explore exploration.
V Gives clearly visible insights on errors and edge cases.
V Easy for debugging.
Now, Let’s perform a simple “getting started” task for testing using Jupyter Notebook and Papermill.
Let assume that we are calculating a precision metric on daily basis and we use it for later analysis and performance measuring.
We want to ensure that the precision stored in the application DB is correct since it can affect our business decisions.
So let’s create testing for it.
The first step is to create a notebook, which gets the raw data from the application.
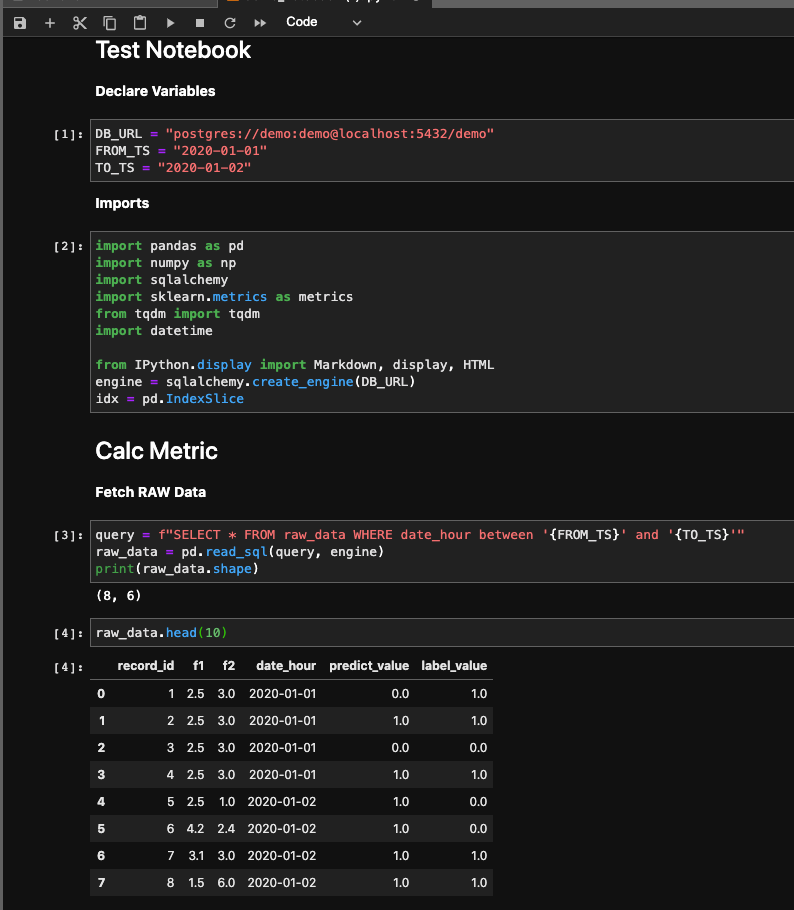
The raw data includes records of predictions and the real values cross 2 dates (‘2020–01–01’ and ‘2020–01–02’).
After creating the first phase of the notebook, we should calc the precision metric according to the raw data, this will be the ground truth precision we want to compare our production data to.

Here we can see that on ‘2020–01–1’ the precision value was 1.0 (that a great statistic !) and on ‘2020–01–02’ it was 0.5.
Finally, we have to fetch our precision results from the production DB and compare them to the ground truth results (notebook results).
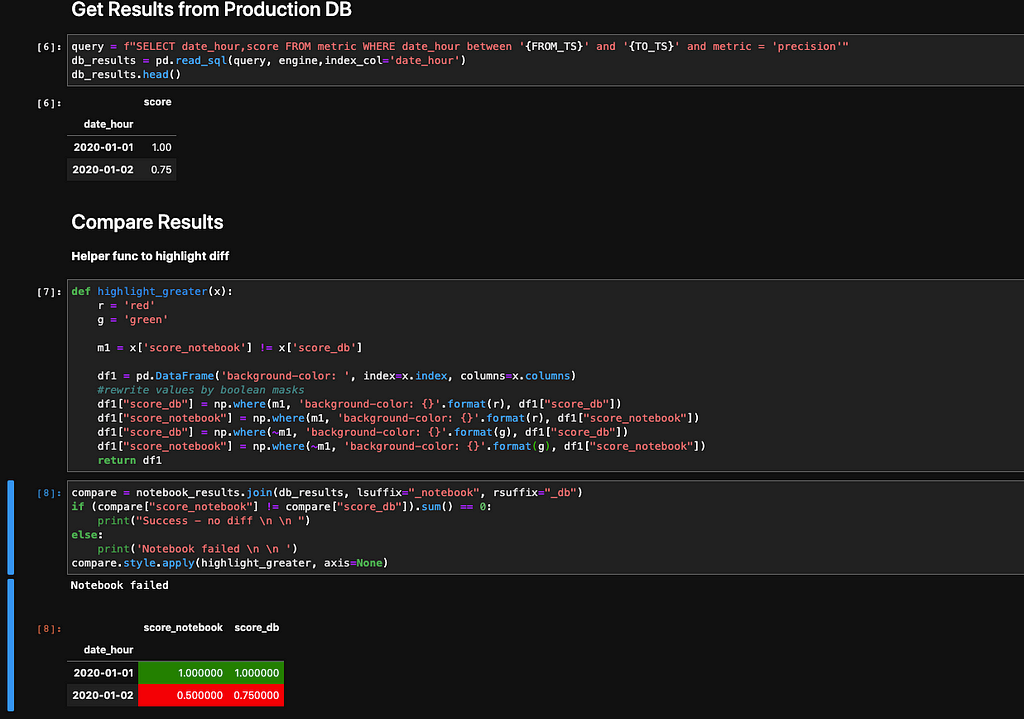
In the last cell, we can see that in the ‘2020–01–02’, the results between the notebook results and the production DB results are different, and they are colored in red- making it easy to recognize and fix.
So now, we got a testing notebook that validates our precision correctness for every time frame we need, and if there are some gaps, they are easy to detect and fix.
There is another extra thing to do with the created notebook. We can integrate the notebook to be part of our CI for it could be run nightly (or in another schedule) using the Papermill tool.
To install Papermill run the command:
$ pip install papermill
To run Papermill and store the results on AWS S3 (could be anywhere else) and pass timeframe parameters:
$ papermill local/metric_calc.ipynb s3://notebooks/nightly/results/metric_calc_output.ipynb -p FROM_TS 2020-01-01 -p TO_TS 2020-01-02
Now, we can see the results in the morning, see if there are some errors in our system, and ensure that our application works right!
Another worthy tip is to integrate the notebook to send notifications to a Slack channel if there are gaps in the results.
Note:
- You can integrate papermill results to other cloud providers.
References:
- https://github.com/nteract/papermill.
- https://github.com/keitakurita/jupyter-slack-notify.
- https://jupyter.org/documentation.
Link to the demo notebook: notebook.
Author: Oryan Omer — superwise.ai
Testing Data-driven Microservices was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.




Recent Posts




")

