



Pyspark Handle Dataset With Columns Separator in Data
Last Updated on January 11, 2021 by Editorial Team
Author(s): Vivek Chaudhary
Programming
The objective of this blog is to handle a special scenario where the column separator or delimiter is present in the dataset. Handling such a type of dataset can be sometimes a headache for Pyspark Developers but anyhow it has to be handled. In my blog, I will share my approach to handling the challenge, I am open to learning so please share your approach as well.
Dataset basically looks like below:
#first line is the header
NAME|AGE|DEP
Vivek|Chaudhary|32|BSC
John|Morgan|30|BE
Ashwin|Rao|30|BE
The dataset contains three columns “Name”, “AGE”, ”DEP” separated by delimiter ‘|’. And if we pay focus on the data set it also contains ‘|’ for the column name.
Let’s see further how to proceed with the same:
Step1. Read the dataset using read.csv() method of spark:
#create spark session
import pyspark
from pyspark.sql import SparkSession
spark=SparkSession.builder.appName(‘delimit’).getOrCreate()
The above command helps us to connect to the spark environment and lets us read the dataset using spark.read.csv()
#create dataframe
df=spark.read.option(‘delimiter’,’|’).csv(r’<path>\delimit_data.txt’,inferSchema=True,header=True)
df.show()
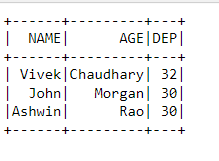
After reading from the file and pulling data into memory this is how it looks like. But wait, where is the last column data, column AGE must have an integer data type but we witnessed something else. This is not what we expected. A mess a complete mismatch isn’t this? The answer is Yes it’s a mess. Reminds me of Bebe Rexha song “I’m a Mess” 😂😂
Now, let's learn how we can fix this.
Step2. Read the data again but this time use read.text() method:
df=spark.read.text(r’C:\Users\lenovo\Python_Pyspark_Corp_Training\delimit_data.txt’)
df.show(truncate=0)

#extract first row as this is our header
head=df.first()[0]
schema=[‘fname’,’lname’,’age’,’dep’]
print(schema)
Output: ['fname', 'lname', 'age', 'dep']
The next step is to split the dataset on basis of column separator:
#filter the header, separate the columns and apply the schema
df_new=df.filter(df[‘value’]!=head).rdd.map(lambda x:x[0].split(‘|’)).toDF(schema)
df_new.show()
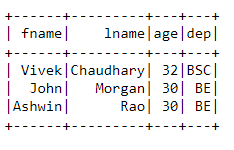
Now, we have successfully separated the strain. Wait what Strain? No Dude it’s not Corona Virus it’s only textual data. Keep it, simple buddy. 😜😜
We have successfully separated the pipe ‘|’ delimited column (‘name’) data into two columns. Now the data is more cleaned to be played with ease.
Next, concat the columns “fname” and “lname” :
from pyspark.sql.functions import concat, col, lit
df1=df_new.withColumn(‘fullname’,concat(col(‘fname’),lit(“|”),col(‘lname’)))
df1.show()

To validate the data transformation we will write the transformed dataset to a CSV file and then read it using read.csv() method.
df1.write.option(‘sep’,’|’).mode(‘overwrite’).option(‘header’,’true’).csv(r’<file_path>\cust_sep.csv’)
The next step is Data Validation:
df=spark.read.option(‘delimiter’,’|’).csv(r<filepath>,inferSchema=True,header=True)
df.show()

Data looks in shape now and the way we wanted.
A small exercise, try with some different delimiter and let me know if you find any anomaly. That’s it with this blog. Will come up with a different scenario next time.
Thanks to all for reading my blog. Do share your views or feedback.
Pyspark Handle Dataset With Columns Separator in Data was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.




Recent Posts
")



")


