



PySpark AWS S3 Read Write Operations
Last Updated on February 2, 2021 by Editorial Team
Author(s): Vivek Chaudhary
Cloud Computing
The objective of this article is to build an understanding of basic Read and Write operations on Amazon Web Storage Service S3. To be more specific, perform read and write operations on AWS S3 using Apache Spark Python API PySpark.
- Setting up Spark session on Spark Standalone cluster
import findspark
findspark.init()
import pyspark
from pyspark.sql import SparkSession
from pyspark import SparkContext, SparkConf
import os
os.environ['PYSPARK_SUBMIT_ARGS'] = '-- packages com.amazonaws:aws-java-sdk:1.7.4,org.apache.hadoop:hadoop-aws:2.7.3 pyspark-shell'
Set Spark properties Connect to Spark Session:
#spark configuration
conf = SparkConf().set(‘spark.executor.extraJavaOptions’,’-Dcom.amazonaws.services.s3.enableV4=true’). \
set(‘spark.driver.extraJavaOptions’,’-Dcom.amazonaws.services.s3.enableV4=true’). \
setAppName(‘pyspark_aws’).setMaster(‘local[*]’)
sc=SparkContext(conf=conf)
sc.setSystemProperty(‘com.amazonaws.services.s3.enableV4’, ‘true’)
print(‘modules imported’)
Set Spark Hadoop properties for all worker nodes as below:
accessKeyId=’xxxxxxxxxx’
secretAccessKey=’xxxxxxxxxxxxxxx’
hadoopConf = sc._jsc.hadoopConfiguration()
hadoopConf.set(‘fs.s3a.access.key’, accessKeyId)
hadoopConf.set(‘fs.s3a.secret.key’, secretAccessKey)
hadoopConf.set(‘fs.s3a.endpoint’, ‘s3-us-east-2.amazonaws.com’)
hadoopConf.set(‘fs.s3a.impl’, ‘org.apache.hadoop.fs.s3a.S3AFileSystem’)
spark=SparkSession(sc)
s3a to write: Currently, there are three ways one can read or write files: s3, s3n and s3a. In this post, we would be dealing with s3a only as it is the fastest. Please note that s3 would not be available in future releases.
v4 authentication: AWS S3 supports two versions of authentication — v2 and v4. For more details consult the following link: Authenticating Requests (AWS Signature Version 4) — Amazon Simple Storage Service
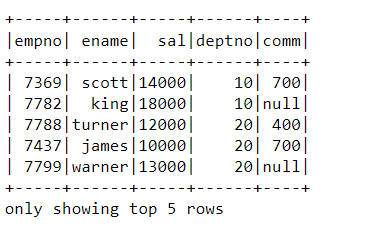
2. Read the dataset present on local system
emp_df=spark.read.csv(‘D:\python_coding\GitLearn\python_ETL\emp.dat’,header=True,inferSchema=True)
emp_df.show(5)
3. PySpark Dataframe to AWS S3 Storage
emp_df.write.format('csv').option('header','true').save('s3a://pysparkcsvs3/pysparks3/emp_csv/emp.csv',mode='overwrite')
Verify the dataset in S3 bucket as below:
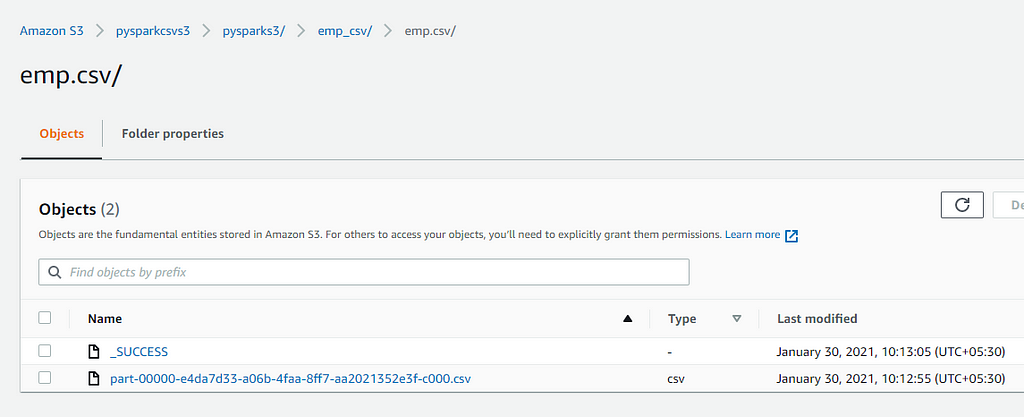
We have successfully written Spark Dataset to AWS S3 bucket “pysparkcsvs3”.
4. Read Data from AWS S3 into PySpark Dataframe
s3_df=spark.read.csv(‘s3a://pysparkcsvs3/pysparks3/emp_csv/emp.csv/’,header=True,inferSchema=True)
s3_df.show(5)
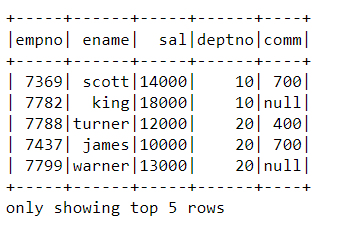
We have successfully written and retrieved the data to and from AWS S3 storage with the help of PySpark.
5. Issue I faced
While writing the PySpark Dataframe to S3, the process got failed multiple times, throwing below error.
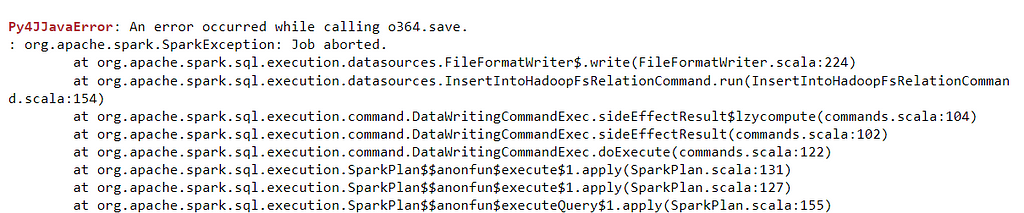
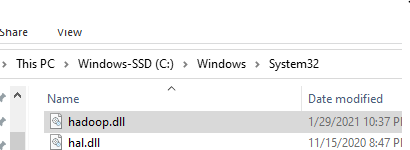
Solution: Download the hadoop.dll file from https://github.com/cdarlint/winutils/tree/master/hadoop-3.2.1/bin and place the same under C:\Windows\System32 directory path.
That’s all with the blog. Thanks to all for reading my blog. Do share your views/feedback, they matter a lot.
PySpark AWS S3 Read Write Operations was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.




Recent Posts




")

