



Hadoop YARN Architecture
Last Updated on June 13, 2020 by Editorial Team
Author(s): Vivek Chaudhary
Programming
YARN stands for Yet Another Resource Negotiator. YARN became part of Hadoop ecosystem with the advent of Hadoop 2.x, and with it came the major architectural changes in Hadoop.
YARN manages resources in the cluster environment. That’s it? Didn’t we had any resource manager before Hadoop 2.x? Of course, we had a resource manager before Hadoop 2.x and it was called Job Tracker.
So what is Job Tracker?
JobTracker (JT) use to manage both cluster resources and perform MapR or MapReduce job execution which means Data processing. JT configures and monitors every running task. If a task fails, it reallocates a new slot for the task to start again. On completion of tasks, it releases resources and cleans up the memory.
JT uses to perform a lot of tasks and this approach had some drawbacks as well. I haven’t worked on Hadoop 1.x but tried to list some of them below.
Drawbacks of the above approach:
- It has a single component: JobTracker to perform many activities like Resource Management, Job Scheduling, Job Monitoring, Re-scheduling Jobs, etc, which puts lots of pressure on a single component.
- JobTracker is the single point of failure, which makes JT highly available resource, so if a JT fails then all tasks will be rebooted.
- Static Resource Allocation, since map and reduce slots are predefined and reserved, they cant be used for other applications even if slots are sitting idle.
Above are some of the major drawbacks of the Hadoop 1.x way of working.
So the next question that arrives in mind is, how does YARN solve the purpose? YARN separates the Resource Management Layer and Data Processing components layer.
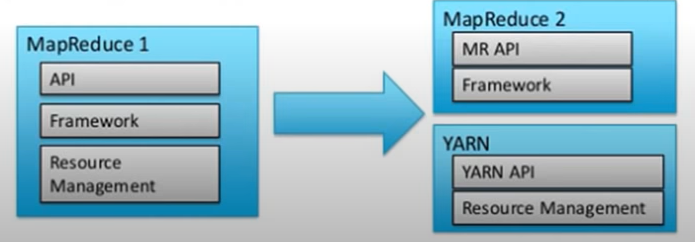
In MapR1 all the task of Resource Management and Processing was done by JobTracker but with the release of Hadoop 2.x, both of the layers have been divided and for Resource Management layer we have YARN. Now Hadoop 2.x says, for Data Processing use MapR, Spark, Tez, and other available Data Processing Framework, whereas YARN takes care of Resource negotiation.
Hadoop 2.x has decoupled the MapR component into different components and eventually increased the capabilities of the whole ecosystem, resulting in Higher Availablity, and Higher Scalability.
YARN and its components
YARN comprises of two components: Resource Manager and Node Manager.
Detailed Architecture:
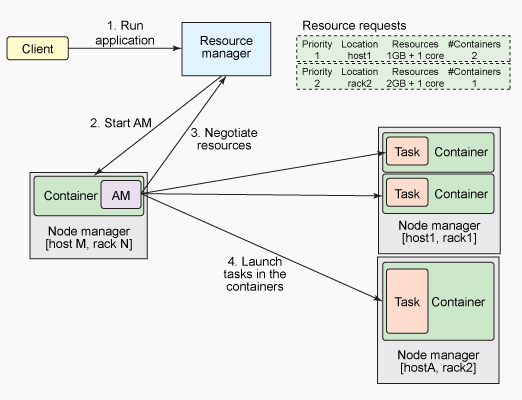
Let’s understand the different components:
Resource Manager
Spark works on Master-Slave architecture and Resource Manager is present at the Master Node. RM is the prime authority and helps in managing resources such as RAM, CPU usage, Network Bandwidth, etc. across different jobs. Resource Manager maintains the list of applications running and list of available resources.
Resource Manager has two components: Scheduler and Application Manager.
- Scheduler:
The scheduler takes care of the resource allocation part on behalf of the resource manager. It allocates resources to the various MapR or Spark applications subjected to the availability of resources.
Scheduler purely takes care of Resource allocation and doesn’t involve in any other activity like monitoring or tracking status of job etc.
2. Application Manager:
Application Manager launches application-specific Application Master in slave node.
Note: Application Manager and Application master are different components
Application Manager negotiates for the container to launch Application Master and helps in relaunching during failure.
In nutshell, when Resource Manager accepts a new MapR or Spark application submission, one of the initial decisions Scheduler takes is to select a container to launch Application Master for that particular application and the Application manager takes care of launching the same.
Node Manager
Before Hadoop 2.x, there use to be a fixed number of slots to execute Map and Reduce jobs, but after the Hadoop 2.x concept of slots is replaced by dynamic creation/allocation of resource containers.
A container refers to the collection of resources such as CPU, RAM, DISK or Hard disk, and network IO, similar to a server.
A Node Manager is the per-machine framework agent responsible to hold containers, monitor their resource usage (CPU, RAM, DISK, etc.) and reports it back to Scheduler present in Resource Manager. Node Manager is present on slave systems.
Node Manager performs Health Check of resources on a scheduled basis, if any health check fails Node Manager marks that node as unhealthy and reports it back to Resource Manager.
Resource Manager + Node Manager = Computation Framework
Application Master
Application master is application-specific or per-application and is launched by the Application manager.
Application Master negotiates resources from Resource Manager and works with Node Manager to execute and monitor tasks. Application Master is responsible for the whole lifecycle of the application.
Application Master sends a resource request to the Resource Manager and asks for containers to run application tasks. After receiving a request from the application master, the resource manager validates the resource requirements and checks for the availability of resources and grants a container to suffice the resource request.
After the container is granted, the application master will request Node Manager to utilize the resources and launch the application-specific tasks.
Application Master monitors the progress of an application and its tasks. If a failure happens then it asks for a new container to launch the task and reports the failure.
After the execution of the application is completed, Application Master shuts itself down and releases its container. Hence marks the execution completion.
That’s all with the YARN and its various components.
Summary:
· What is YARN
· Hadoop pre-2.x and post 2.x comparison
· How Yarn fixed the pre 2.x issues
· Components such as Resource Manager, Node Manager, Application Master, and their functionality
· How Application Master works
Hadoop YARN Architecture was originally published in Towards AI — Multidisciplinary Science Journal on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Take our 90+ lesson From Beginner to Advanced LLM Developer Certification: From choosing a project to deploying a working product this is the most comprehensive and practical LLM course out there!
Towards AI has published Building LLMs for Production—our 470+ page guide to mastering LLMs with practical projects and expert insights!

Discover Your Dream AI Career at Towards AI Jobs
Towards AI has built a jobs board tailored specifically to Machine Learning and Data Science Jobs and Skills. Our software searches for live AI jobs each hour, labels and categorises them and makes them easily searchable. Explore over 40,000 live jobs today with Towards AI Jobs!
Note: Content contains the views of the contributing authors and not Towards AI.




Popular posts

 for 2021")



Updates

Recent Posts



