



The NLP Cypher | 11.29.20
Last Updated on July 24, 2023 by Editorial Team
Author(s): Quantum Stat
NATURAL LANGUAGE PROCESSING (NLP) WEEKLY NEWSLETTER
Hand of God
Hey, welcome back, just returned from the holidays. And Happy Thanksgiving for those celebrating. It’s been a slow week given the holiday break so the newsletter will be a bit shorter than usual, but that doesn’t mean we can’t discuss alien monoliths…
If you haven’t heard, in a national park in Utah, an unknown monolith was discovered. At the moment, no one knows where it came from.

And it didn’t take long for someone to loot it ?.

Software Updates
TF
Release TensorFlow 2.4.0-rc3 · tensorflow/tensorflow
&
You can now parallelize models on the Transformers library!
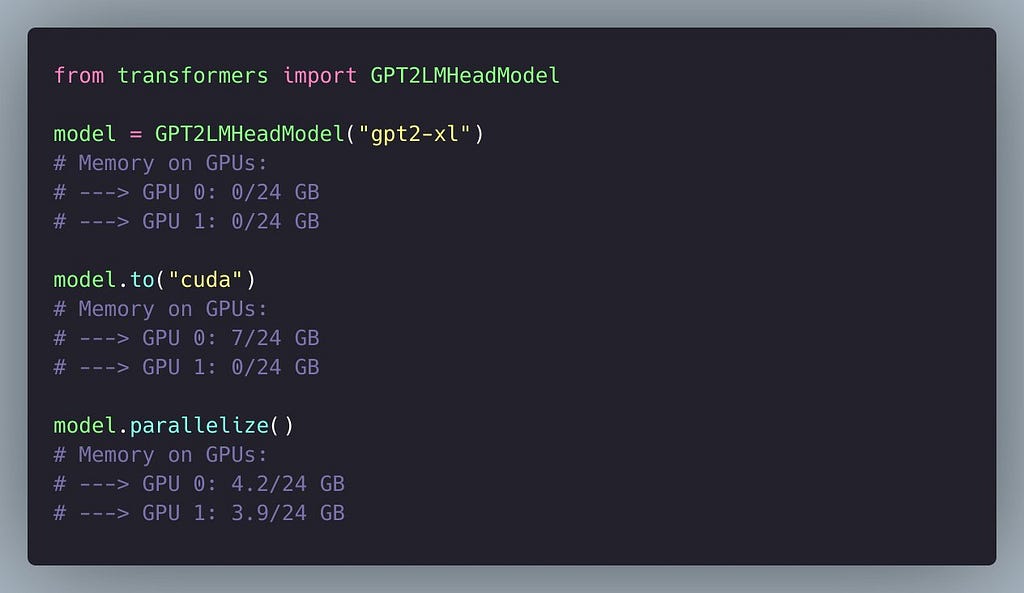
Oh and by the way, earlier this week we added 50 new datasets to the Big Bad NLP Database: highlights include the IndoNLU benchmark and several datasets from EMNLP, thank you to Ulrich Schäfer and Neea Rusch for contributing!
P.S. If you enjoy today’s article, don’t hesitate to give a ??! Thank you!
GNN Book
Hey want a an awesome introduction to graph neural networks? Found this pre pub version of William Hamilton’s “Graph Representation Learning” book.
It is very well written and illustrates this burgeoning topic in machine learning with elegant simplicity.
ToC
- Chapter 1: Introduction and Motivations [Draft. Updated September 2020.]
- Chapter 2: Background and Traditional Approaches [Draft. Updated September 2020.]
Part I: Node Embeddings
- Chapter 3: Neighborhood Reconstruction Methods [Draft. Updated September 2020.]
- Chapter 4: Multi-Relational Data and Knowledge Graphs [Draft. Updated September 2020.]
Part II: Graph Neural Networks
- Chapter 5: The Graph Neural Network Model [Draft. Updated September 2020.]
- Chapter 6: Graph Neural Networks in Practice [Draft. Updated September 2020.]
- Chapter 7: Theoretical Motivations [Draft. Updated September 2020.]
Part III: Generative Graph Models
- Chapter 8: Traditional Graph Generation Approaches [Draft. Updated September 2020.]
- Chapter 9: Deep Generative Models [Draft. Updated September 2020.]
Graph Representation Learning Book
PDF Graph Representation Learning
Language Explanations
Can language help us to train models better?
“In the same way that we might take an input x, and extract features (e.g. the presence of certain words) to train a model, we can use explanations to provide additional features.”
In a new blog post from Stanford AI, they discuss the problem on why it’s so hard to teach models knowledge via language, and possible solutions from an NLP perspective(i.e. they discuss their ExpBERT paper from earlier this year), and computer vision perspective (i.e. their visual perceptions paper)
Learning from Language Explanations
ExpBERT’s GitHub discussed in the blog:
DataLoader PyTorch
Interesting blog post from PaperSpace discussing the DataLoader Class in PyTorch. They summarize this handy class in PyTorch if you are interested in using preexisting datasets or even using your own custom dataset on numerical or text data. ToC:
- Working on Datasets
- Data Loading in PyTorch
- Looking at the MNIST Dataset in-Depth
- Transforms and Rescaling the Data
- Creating Custom Datasets in PyTorch
Blog:
Complete Guide to the DataLoader Class in PyTorch | Paperspace Blog
Repo Cypher ??
A collection of recent released repos that caught our ?
Neural Acoustic
A library for modeling English speech data with varied accents using Transformers.
Bartelds/neural-acoustic-distance
RELVM
Repo used for training a latent variable generative model on pairs of entities and contexts (i.e. sentences) in which the entities occur. Their model can be used to perform both mention-level and pair-level classification.
GLGE Benchmark
A new natural language generation (NLG) benchmark composing of 8 language generation tasks, including Abstractive Text Summarization (CNN/DailyMail, Gigaword, XSUM, MSNews), Answer-aware Question Generation (SQuAD 1.1, MSQG), Conversational Question Answering (CoQA), and Personalizing Dialogue (Personachat).
In addition,
Microsoft highlights a new pre-trained language model called ProphetNet used in sequence-to-sequence learning with a novel self-supervised objective called future n-gram prediction.
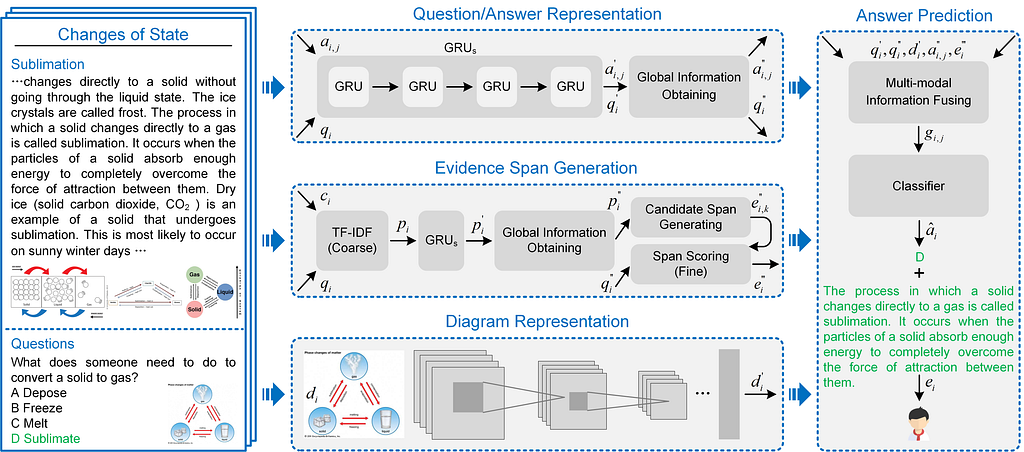
OpenTQA
OPENTQA is a open framework of the textbook question answering task. Textbook Question Answering (TQA) is where one should answer a diagram/non-diagram question given a large multi-modal context consisting of abundant essays and diagrams.
Dataset of the Week: Question Answering for Artificial Intelligence (QuAIL)
What is it?
QuAIL contains 15K multiple-choice questions in texts 300–350 tokens long across 4 domains (news, user stories, fiction, blogs).
Sample

Where is it?

Every Sunday we do a weekly round-up of NLP news and code drops from researchers around the world.
For complete coverage, follow our Twitter: @Quantum_Stat

The NLP Cypher | 11.29.20 was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts

Recent Posts




")

