


 — Don’t ask how, ask what… and More!")
Exploratory Data Analysis (EDA) — Don’t ask how, ask what… and More!
Last Updated on November 10, 2021 by Editorial Team
Author(s): Towards AI Team
What is new at Towards AI, what is changing, an exciting free event, our editor’s monthly picks, and more!
If you have trouble reading this email, see it on a web browser.
It’s been a busy month for Towards AI. We surpassed over 115k followers across our social media networks, and now we have over 11k subscribers, all thanks to you! Our avid readers who continue to engage with us, whether by sharing, commenting, or engaging with our pieces. On our end, we promise we will continue to work hard to provide you with high-quality content.
📅 [Free] Ray Summit Sep 30-Oct 1: Scalable Python & ML for everyone See how Ray, the open-source Python framework, is used for building distributed apps and libraries, including backend infrastructures and ML platforms. Ray is growing fast and hundreds of companies are now using it because of its flexibility, scalability, and efficiency. Join Ray Summit by livestream or access the sessions on-demand, all completely free — register here. 📅
Now into the monthly picks! We pick these articles based on readership, fans, and views a specific piece gets. We hope you enjoy reading them as much as we did. Also, we started doing something new! We will pick our top ten performing articles, and our editors will choose one to two essays that didn’t have outstanding performance, but due to its quality — made the cut for the month.
If you can, please share our subscription link with your friends and acquaintances. We promise we won’t spam their inbox. If you have any feedback regarding our newsletter, please feel free to shoot us an email.
📚 Editor’s choice featured articles for the month ↓ 📚

Exploratory Data Analysis (EDA) — Don’t ask how, ask What by Itamar Chinn
The first step in any data science project is EDA. This article will explain why each step in the EDA is important and why we should care about what we learn from our data. EDA or Exploratory Data Analysis is the process of understanding what data we have in our dataset before we start finding solutions to our problem. In other words — it is the act of analyzing the data without biased assumptions in order to effectively preprocess the dataset for modeling…
Monte Carlo Simulation An In-depth Tutorial with Python by Pratik Shukla, Roberto Iriondo
A Monte Carlo method is a technique that uses random numbers and probability to solve complex problems. The Monte Carlo simulation, or probability simulation, is a technique used to understand the impact of risk and uncertainty in financial sectors, project management, costs, and other forecasting machine learning models…

Observer Pattern vs. Pub-Sub Pattern by Munish Goyal
Don’t get confused with these two similar but different patterns, and know which one to use when. This difference is important to not just generic Software Engineers, but also to Data Engineers and is the basis for the understanding event-driven architectures for data pipelines. Let’s look at both of them individually before we eventually list-out the differences…
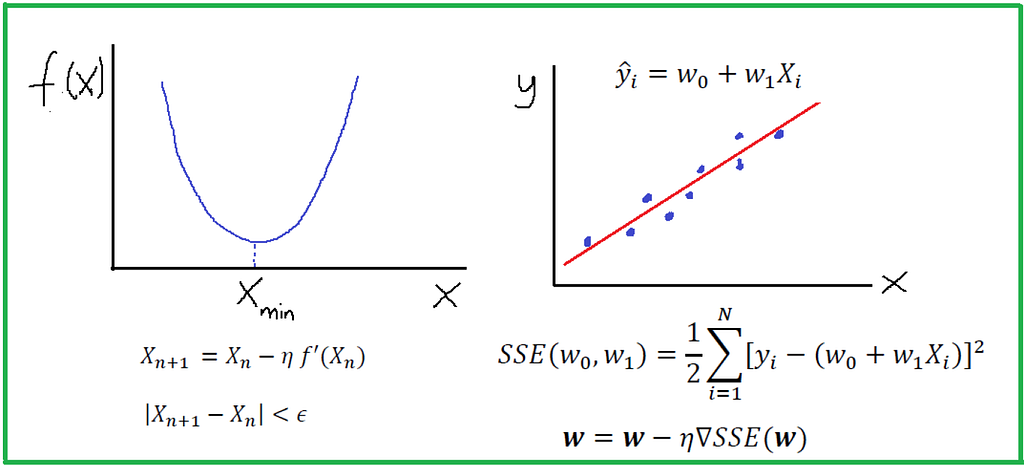
Calculus in Machine Learning by Benjamin Obi Tayo, Ph.D.
A machine learning algorithm (such as classification, clustering, or regression) uses a training dataset to determine weight factors that can be applied to unseen data for predictive purposes. Behind every machine learning model is an optimization algorithm that relies heavily on calculus. In this article, we discuss one such optimization algorithm, namely, the Gradient Descent Approximation (GDA), and we’ll show how it can be used to build a simple regression estimator…

A Comprehensive Guide To Optimize Your Pandas Code by Eyal Trabelsi
In this to guide, I am going to show you some of the most common pitfalls that can cause otherwise perfectly good Pandas code to be too slow for any time-sensitive applications, and walk through a set of tips and tricks to avoid them.
Let’s remind ourselves what is pandas, apart from a cute animal 🐼. Its a widely used library for data analysis and manipulation that load all the data into RAM.

Data Validation Framework in Apache Spark for Big Data Migration Workloads by Karthikeyan Siva Baskaran
Quality Assurance Testing is one of the key areas in Bigdata. Data quality issues may ruin the success of many Big Data, data lake, ETL projects. Whether the data is big or small, the need for data quality doesn’t change. High-quality data is the absolute driver to get insights from it. The quality of data is measured based on whether it satisfies the business by deriving the necessary insights…

Build a Neural Network From Scratch in Python by Rashida Nasrin Sucky
The Neural Network has been developed to mimic a human brain. Though we are not there yet, neural networks are very efficient in machine learning. It was popular in the 1980s and 1990s. Recently it has become more popular. Computers are fast enough to run a large neural network in a reasonable time. In this article, I will discuss how to implement a neural network.

Create Your Own Harry Potter Short Story Using RNNs and TensorFlow by Amisha Jodhani
Still waiting for your Hogwarts letter?
Want to enjoy the feast in the Great Hall?
Explore the secret passages in Hogwarts?
Buy your first wand from Ollivander’s?
*sigh* You are not alone.
I have (after all this time?) always been obsessed with Harry Potter, and I recently started learning neural networks. It’s fascinating to see how creative you can get with Deep Learning, so I thought, why not brew them up?
This article runs you through the entire code I wrote to implement it.
But for all the Hermione’s out there, you can directly find the GitHub code here and run it yourself!
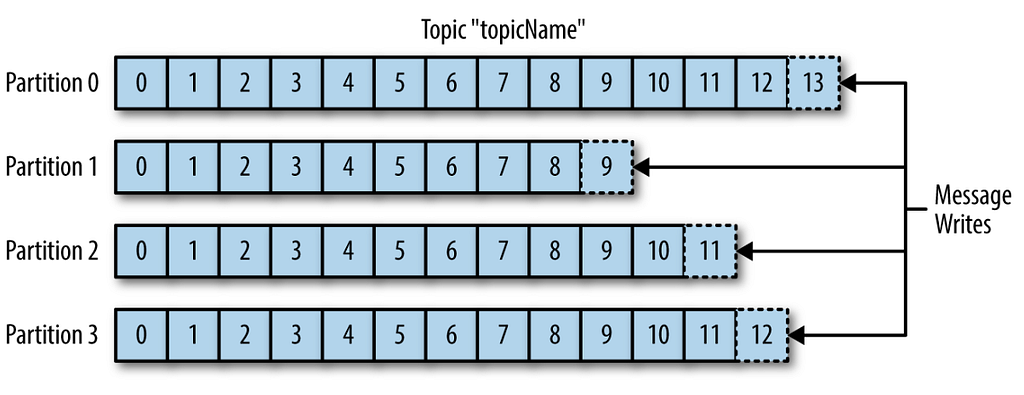
Diving Deep into Kafka by Vivek Chaudhary
The objective of this post is to build some more understanding of Apache Kafka concepts such as Topics, Partitions, Consumer, and Consumer Groups. Kafka’s basic concepts have been covered in my previous article. As we know, messages in Kafka are categorized or stored inside Topics. In simple terms, Topic can be construed as a Database table. Kafka Topics inside is broken down into partitions…

Unlocking the Power of Text Analytics with Natural Language Processing by Sharon Lim
Natural language is a language that is used for everyday communication between humans. It is highly unstructured in nature for both text and speech, thus making it difficult to parse and comprehend by machines. Natural language processing (“NLP”) is concerned with the interaction between natural human language and computers. It is an intersection between the fields of linguistics, computer science, and artificial intelligence.

The NLP Model Forge by Quantum Stat
Streamlining an inference pipeline on the latest fine-tuned NLP model is a must for fast prototyping. However, with the plethora of diverse model architectures and NLP libraries to choose from, it can make prototyping a time-consuming task. As such, we’ve created The NLP Model Forge. A database/code generator for 1,400 fine-tuned models that were carefully curated from top NLP research companies such as Hugging Face, Facebook (ParlAI), DeepPavlov, and AI2.

How to Publish a Jupyter Notebook as a Medium Blogpost by Chetan Ambi
I have recently started writing about Data Science and Python on Medium. One of the time taking activity when writing any technical articles is to provide the reproducible supporting code. I have been using GitHub Gist and sometimes a screenshot of the code from Jupyter Notebook or other Python editor. But it all takes time as we need to toggle between Medium editor and Gist or other Python editor…
🙏 Thank you for being a subscriber with Towards AI! 🙏
🤖 Follow Towards AI on social media ↓🤖
Facebook | Twitter | Instagram | LinkedIn | Google News | Flipboard | Mobile Feed
Exploratory Data Analysis (EDA) — Don’t ask how, ask what… and More! was originally published in Towards AI — Multidisciplinary Science Journal on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts

Recent Posts




")

