



Everyone Can Understand Machine Learning… and More!
Last Updated on November 10, 2021 by Editorial Team
Author(s): Towards AI Team
Some cool announcements, what is new in the AI world, and our monthly picks
If you have trouble reading this email, see it on a web browser.
Work in the AI field is moving forward very quickly. Today Papers with Code announced their partnership with arXiv, where code links are now shown on arXiv articles, and authors can submit code through arXiv, making it a great addition to avid researchers and practitioners.
NeurIPS also announced a cool challenge, the 2020 ML Reproducibility Challenge sponsored by Papers with Code, encouraging people who work with ML to participate (including enthusiasts!). If you’d like to learn more, check out their announcement, it sounds pretty neat.
In other news, if you are into reinforcement learning, we encourage you to check out MineRL — their research group just announced the extension of their competition till February 2021. So if you’d like to build some sample-efficient AI agents in Minecraft, definitely check them out!
Also, Scale AI announced that they are sponsoring students and independent researchers creating promising datasets. If you are interested, check out the announcement by Aerin Kim.
Last but not least, don’t forget that October 11 is the deadline for the 2020 Amazon Research Awards. If you like to apply or learn more, you can do so on Amazon Science.
Is your company interested in supporting Towards AI’s efforts? For sponsorship opportunities, please email us.
Now into the monthly picks! We pick these articles based on readership, fans, and views a specific piece gets. We hope you enjoy reading them as much as we did. Also, we started doing something new! We will pick our top ten performing articles, and our editors will choose one to two essays that didn’t have outstanding performance, but due to its quality — made the cut for the month.
If you can, please share our subscription link with your friends and acquaintances. We promise we won’t spam their inbox. If you have any feedback regarding our newsletter, please feel free to send us an email.
📚 Editor’s choice featured articles for the month ↓ 📚
Everyone Can Understand Machine Learning — Regression Tree Model by Christopher Tao, Ph.D.
This article is meant to explain the regression tree machine learning model without any buzzwords and scientific expressions, so you don’t need any pre-requisite knowledge or a Computer Science/Math degree to understand it.
As one of the most commonly used machine learning models, a decision tree is usually used for classification purposes. However, it can also be used to predict continuous numeric values. In this article, I am going to introduce a specific type of decision tree s — the regression tree. Don’t worry if you’re not a Data Scientist or Data Analyst, I will try my best to help you understand how regression trees are built without any formulas and equations…
[ Read More ]

Our Recommendations on the Best Data Science Books — Free and Paid by Towards AI Team
For the past year, we have looked at over 23,000 [1] data science books, and we have picked what we consider to be the best paid and free books in terms of technicality, ability to explain complex subjects, depth, and verified reviews. Over the last decade, data science has become one of the most paid and highly reputed domains for professionals in the information technology field. Nowadays, data science applications have become inevitable for most (if not all) businesses. Hence, there is a surge of proficient data science professionals…
[ Read More ]

The Beginners’ Guide to Elasticsearch — Part 1 by Chetan Ambi
If you would like to know what is Elasticsearch, why should we use Elasticsearch, what are the alternatives/competitors to Elasticsearch then you are in the right place. In this article, I will try to answer all these questions. So, let’s get started. … Elasticsearch — is a distributed, open-source search and analytics engine for all types of data, including textual, numerical, geospatial, structured, and unstructured. Elasticsearch is built on Apache Lucene…
[ Read More ]
Learning Data Science Has Never Been Easier by Benjamin Obi Tayo Ph.D.
In this article, I will discuss several resources that can help you master the foundations of data science. In the modern age of information technology, there is an enormous amount of free resources for data science self-study. As a matter of fact, you can design your own data science curriculum from the innumerable amount of available resources…
[ Read More ]

5 Tricky SQL Queries Solved by Saiteja Kura
SQL(Structured Query Language) is a very important tool in a data scientist’s toolbox. Mastering SQL is not only essential in an interview point of view, but a good understanding of SQL by being able to solve complex queries will keep us above everyone in the race. In this article, I will talk about 5 tricky questions I found and my approaches to solve them…

ROCKET: Fast and Accurate Time Series Classification by Alexandra Amidon
Most time series classification methods with state-of-the-art (SOTA) accuracy have high computational complexity and scale poorly. This means they are slow to train on smaller datasets and effectively unusable on large datasets. ROCKET (RandOM Convolutional KErnal Transform) can achieve the same level of accuracy in just a fraction of the time as competing SOTA algorithms, including convolutional neural networks. The algorithms were evaluated on the benchmark datasets in the UCR Archive…
[ Read More ]

How to Improve Data Labeling Efficiency with Auto-Labeling, Uncertainty Estimates, and Active Learning by Hyun Kim
In this post, we will be diving into the machine learning theory and techniques that were developed to evaluate our auto-labeling AI at Superb AI. More specifically, how our data platform estimates the uncertainty of auto-labeled annotations and applies it to active learning. Before jumping right in, it would be useful to have some mental buckets into which the most popular approaches can be categorized. In our experience, most works in deep learning uncertainty estimation fall under two buckets…
[ Read More ]

Survival Analysis with Python Tutorial — How, What, When, and Why by Pratik Shukla
This article covers an extensive review with step-by-step explanations and code for how to perform statistical survival analysis used to investigate the time some event takes to occur, such as patient survival during the COVID-19 pandemic, the time to failure of engineering products, or even the time to closing a sale after an initial customer contact…
[ Read More ]
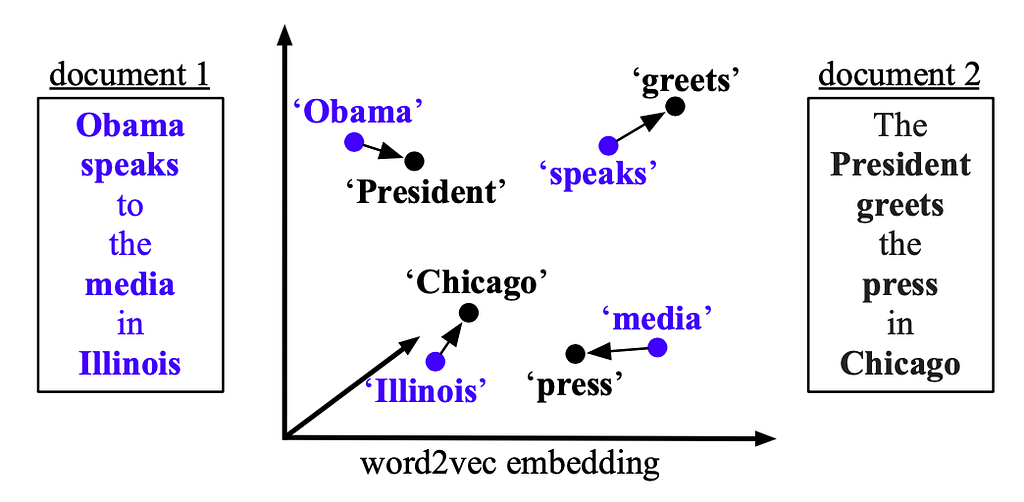
Word Mover’s Distance (WMD) Explained: An Effective Method of Document Classification by Adjacent
Document classification and document retrieval have been showing a wide range of applications. An essential part of document classification is to generate document representations properly. Matt J. Kusner et al., in 2015, presented Word Mover’s Distance (WMD) [1], where word embeddings are incorporated in computing the distance between two documents. With given pre-trained word embeddings, the dissimilarities between documents can be measured with semantical meanings by computing “the minimum amount of distance that the embedded words of one document need to ‘travel’ to reach the embedded words of another”…
[ Read More ]

What Does 2500+ Popular Article’s Historical Data Teach Us? by Shareef Shaik
A few days back when I wrote my second article on Medium, I gave it to my friends for review. One of them immediately told me that the title is very captive and that can pull the readers, I didn’t take his words seriously and thought he was just encouraging me. I finally published it on a Saturday afternoon. It reached 70 views that day. The next morning when I woke up to check if I had done any better than my first blog, my blog managed to reach 120 views. I was slightly disappointed, not because of the views but it didn’t get the attention it deserved. I stopped checking it and indulged myself in my other works. Later that day when I had a peek, I was awestruck, the article had got more than 10K views with 50% reads…
[ Read More ]

Building a Custom Image Dataset for Deep Learning projects by Dhilip Subramanian
I work predominantly in NLP for the last three months at work. It’s been a long time I work on the image data. Hence, I decided to build a unique image classifier model as part of my personal project and learning. One thing I am really missing in the current pandemic is traveling. These days I used to see a lot of travel vlogs and travel pictures on Instagram, wondering when we will go back to the normal world…
[ Read More ]

Flask Web Application with Python by Sharon Lim
ith the training of deep learning models, how can we deploy the trained model as a web application? Enters Flask — the most popular web application framework for Python. By leveraging on the functionality of Flask, we can establish a strong foundation for a full-stack application, explore new frontiers for a more extensive and feature-rich website. It enables the user to exercise full control over serving the web pages and internal data flow. We shall approach the following problem statements and explore the use of transfer learning and flask web application for deep learning projects…
[ Read More ]
🙏 Thank you for being a subscriber with Towards AI! 🙏
Follow us on social media ↓
Facebook | Twitter | Instagram | LinkedIn | Google News | Mobile Feed
Everyone Can Understand Machine Learning… and More! was originally published in Towards AI — Multidisciplinary Science Journal on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts

Recent Posts




")

