



Applied NLP, Challenges in RL, State-of-the-art Research, and more!
Last Updated on November 10, 2021 by Editorial Team
Author(s): Towards AI Team
AI news, research, updates, an exciting and free-to-attend NLP summit with top speakers, and our monthly editorial picks!
If you have trouble reading this email, see it on a web browser.
Applied natural language processing (Applied NLP) is becoming a very hot topic in the machine learning community, and for good reasons. It has emerged as an essential subdiscipline in the field of artificial intelligence (AI), and the main reason can be summed up in one sentence: We are drowning in unstructured data — texts, documents, articles, blog posts, emails, and more — and most of them are written in natural language. NLP’s objective is to build computer systems that can understand and derive meaning from human language to improve various applications. NLP has been at the core of much recent state-of-the-art research and application, and one of the best places to take a deep dive into applied NLP is the NLP Summit, presented by John Snow Labs:
Join the NLP Summit: two weeks of immersive, industry-focused content. Week one will include over 50 unique sessions, with a special track on NLP in Healthcare. Week two will feature beginner to advanced training workshops with certifications. You’ll hear from teams who are leading the NLP space at NASA, Vonage, Zillow, Merck, Amazon, Walmart Labs, Booz Allen Hamilton, Morgan Stanley, Salesforce, Roku, Zillow, and many more! For more information, including confirmed speakers, check out NLP Summit 2021. Free registration is required to secure your access to the keynotes, breakout sessions from industry leaders, Q&A with speakers, a datathon, coffee chats, and much more. Register now for free.
How do we attract and keep the best and the brightest? This post by Divyansh Kaushik and Caleb Watney dives into a fundamental problem. How to support international students and entrepreneurs in our economy to continue to have the US as an innovation powerhouse and keep attracting highly skilled immigrants.
If you are into the realms of the fascinating weak supervision and programmatic labeling approaches, we recommend you to check out “How to Use Snorkel to Build AI Applications,” where Head of Technology and Co-founder of Snorkel AI, Braden Hancock, dives into the history and state-of-the-art methods that drove Snorkel to become the giant that they are now—starting within the OSS realm and moving toward serving some of the world’s most prominent Fortune 500 enterprises.
Now, let’s face it. AI systems are often opaque, strange, and challenging to use. In the field of machine learning, this is particularly true. So if we want to make intelligent systems that people can understand and interact with — more efficiently, a crucial part of the solution is a community where people can come together, share ideas and learn from each other. That is why we created our AI community on Discord — to connect and learn with other data experts and enthusiasts.

Minecraft poses a unique environment, and the folks at MineRL have been working hard in beating Minecraft using state-of-the-art machine learning. If you haven’t yet, check out their work and how to get involved — most of their work is OSS.
One of the coolest things launched recently is Habitat by Facebook AI, aiming at helping researchers and practitioners tackle the next frontier in embodied AI by enabling agents to be trained in interactive environments at much faster speeds than their predecessors.
Also, Github recently launched Copilot, an AI application powered by OpenAI that translates natural language into code, and Codex, a natural language power source, will integrate with the app by the end of the Summer through an API. With Copilot, developers can get code suggestions for whole lines and sometimes entire functions right within the editor as you go, and while it may present biases, it’s going to be very useful for non-bias-based applications. For a more straightforward yet robust proof-of-concept similar to Copilot, check out the OSS CoderX by Carnegie Mellon Professor Graham Neubig.
Sharing is caring. Please feel free to share our newsletter or subscription link with your friends, colleagues, and acquaintances. One email per month; unsubscribe anytime! Also, if you have any feedback on how we can improve, please feel free to let us know.
Now onto the monthly picks! We pick these articles based on readers, fans, and views a specific piece gets. We hope you enjoy reading them as much as we did. Also, we started doing something new! We will pick our top-performing articles, and our editors will choose a couple of essays that didn’t have outstanding performance, but due to their quality — they made the cut for the month.
📚 Editor’s choice featured articles of the month ↓ 📚

Facebook Launches One of the Toughest Reinforcement Learning Challenges in History by Jesus Rodriguez
Reinforcement learning(RL) has been at the center of some of the most impressive achievements in artificial intelligence(AI) in the last decade. From DeepMind’s famous AlphaGo to milestones in StarCraft II, Dota 2, or Minecraft, RL remains one of the fastest-growing areas in the deep learning space. However, despite all its success, Facebook AI Research(FAIR) believes that RL needs to be pushed to new levels, and, for that, they are turning their attention to a new game: NetHack.

Best AI Communities for Artificial Intelligence (AI) Enthusiasts by Towards AI Team
Once you start exploring the field of artificial intelligence and machine learning, you will realize that there is a lot to learn. There is a variety of online groups and communities where experts share their insights on AI algorithms, problems in AI, ML, computer vision, and so on. These discussions lead to developing new ideas and solutions, which will eventually help the AI community grow more robust. This article will look at some actionable tips that help identify good online groups and communities.

How to Read More Research Papers? by Louis Bouchard
Two years ago, I had to read my first research paper ever. I remember how old it looked and how discouraging the mathematics inside was. It really did look like what the researchers worked on in movies. The paper was from the 1950s, but it hasn’t changed much since then. Fast-forward to this day, I’ve gained much experience reading them after reading a few hundred papers in the last year trying to keep up with the news in computer vision. Still, I know how overwhelming a first read can be, especially the first read of your first research paper. This is why I felt like sharing my best tips and practical tools I use daily to simplify my life and be more efficient when looking for interesting research papers and reading them.

How I Went From Being a Confused Undergrad to an Experienced Machine Learning Engineer by Arunn Thevapalan
It’s been a month at my software engineering internship, and all I wanted was to quit. Imagine this. You bag an internship at the R&D unit of one of the biggest banks in the country. You get exposure to an end-to-end software development lifecycle alongside sophisticated security protocols. Simply put, it’s one of the best experiences a computer science undergrad could ask for. My friends claimed I should be blessed and lucky. Yet, I had no clue what I was doing.
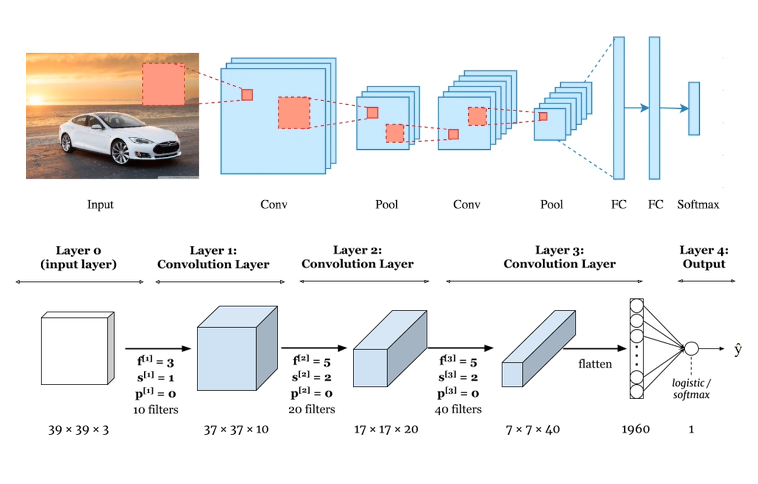
Understand CNN Basics with a Keras Example in Python by Amit Chauhan
In this article, we will try to implement the basic CNN model with the Keras framework. The benefit of the convolutional neural network is that it reduces or minimizes the dimension and parameters of images by retaining maximum information so that the training process becomes fast and takes less computation power.

The 7 Stages Of Preparing Data For Machine Learning by Abhay Parashar
You might already know that data is the key to any machine learning task. At the start, we have data that is fetching to an algorithm that finds some patterns and valuable information from the data and saves all the learning in a model. So machine learning starts with data. However, before fetching the data into machine learning algorithms, we need to take several steps to prepare the data for modeling.

Why the Artificial Intelligence World Enters Winter by Ömer Özgür
The world of Artificial Intelligence usually has two climates, spring and winter. Artificial intelligence has sometimes inevitably entered the winter, but often it has become more robust and revived. In the world of artificial intelligence, winter and early spring climates are experienced similar to the seasons. The entry into the ice ages indicates the long-term predictive failure of humans and being too sure about some issues.

A Primer on Node.js by Balakrishnakumar V
Node is a runtime environment for executing JavaScript code outside a browser. It is often used to build back-end services like APIs, which powers Web apps, Mobile apps, etc. It is also superfast and highly scalable during the production environment. Along with perks like it can be built fast, requires fewer lines of codes compared to other backend services, lesser files, can handle more requests, and provide faster response time.

How to Simulate the Most Famous Counter-Intuitive Probability Problem — using Python by Dasaradh S K
Recently I came across the counter-intuitive Monty Hall puzzle. Initially, I was surprised by the answer and wasn’t convinced. However, when I finally understood it, I was even more surprised, which changed my intuition for Probability. I hope this article will help you get a better understating of Probability and Statistics.
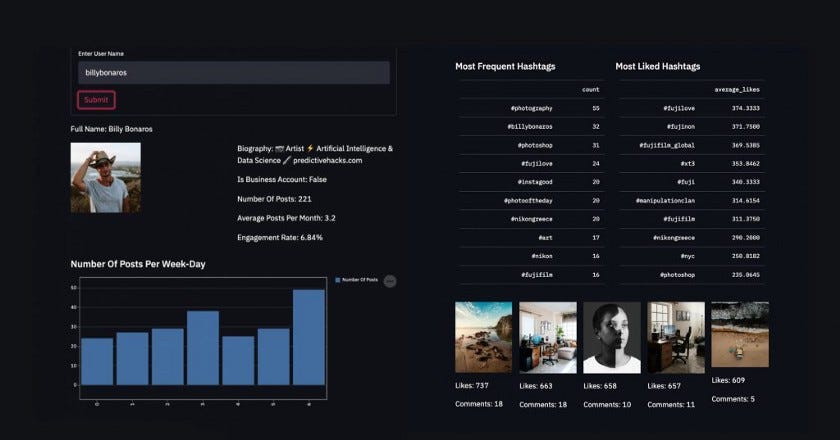
How To Create An Instagram Profile Analyzer App Using Python And Streamlit by Billy Bonaros
Streamlit is a great library that helps us create python apps with minimum effort. Not only it’s easy, but its UI is beautiful and looks pretty professional. Our Idea for this post is to create an Instagram Dashboard having some descriptive statistics about a user’s profile like most frequent hashtags, and top liked posts, engagement rate, etc. We need an application that takes as input a user name and will scrape its information from Instagram to return the final Dashboard.

Multi-Object Tracking Metrics by Amrith Coumaran
The evaluation process is one of the most important steps in build a Machine Learning Model. Especially when it comes to real-time detection plus tracking system. Computer Vision applications in tracking are becoming increasingly popular in surveillance, Sports Analytics, Autonomous vehicles, etc. So, evaluating your model would be the most challenging task before your deploy it. Today, let’s go through a set of metrics that evaluates your tracking system and gives you a better understanding of your model.

The Journey to Data Science is a Marathon, Not a Sprint by Benjamin Obi Tayo Ph.D.
I’ve seen numerous posts, books, or ads about learning data science in 4 weeks or one year. While it is possible to learn the basics (black-box knowledge) of data science within a short period of time, it takes a lot more to master data science’s theoretical and practical aspects. That being said, the journey to becoming a data scientist is analogous to a marathon, not a sprint.

Lacking Good Computer Vision Benchmark Datasets Is a Problem — Let’s Fix That! by Kristina Arezina
Data often stands between a state-of-the-art computer vision machine learning project and just another experiment. Unfortunately, there is no widely adopted industry standard for selecting the best and most relevant benchmarks.
🙏 Thank you for being a subscriber with Towards AI! 🙏
Follow us ↓
[ Facebook ] |[ Twitter ]| [ Instagram ]| [ LinkedIn ] | [ Github ] | [ Google News ]
Applied NLP, Challenges in RL, State-of-the-art Research, and more! was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts

Recent Posts






")