



Why Choose Random Forest and Not Decision Trees
Last Updated on January 6, 2023 by Editorial Team
Last Updated on November 17, 2020 by Editorial Team
Author(s): Daksh Trehan
A concise guide to Decision Trees and Random Forest.
Decision trees belong to the family of the supervised classification algorithm. They perform quite well on classification problems, the decisional path is relatively easy to interpret, and the algorithm is fast and simple.
The ensemble version of the Decision Trees is the Random Forest.
Table of Content
- Decision Trees
- Introduction to Decision Trees.
- How does the Decision Tree work?
- Decision Trees Implementation from scratch.
- Pros & Cons of Decision Trees.
2. Random Forest
- Introduction to Random Forest
- How does Random Forest Works?
- Sci-kit implementation for Random Forest
- Pros & Cons of Random Forest.
Decision Trees
Introduction to Decision Trees
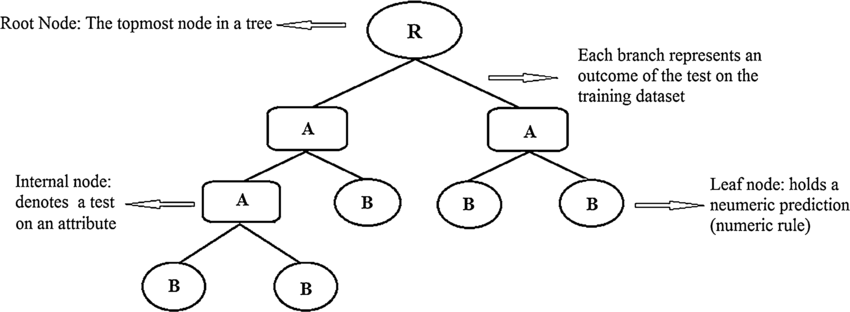
A decision tree is a simple tree-like structure constituting nodes and branches. Data is split based on any of the input features at each node, generating two or more branches as output. This iterative process increases the number of generated branches and partitions the original data. This continues until a node is generated where all or almost all of the data belong to the same class, and further splits — or branched — are no longer possible.
This whole process generates a tree-like structure. The first splitting node is called the root node. The end nodes are called leaves and are associated with a class label. The paths from the root to the leaf produce the classification rules.
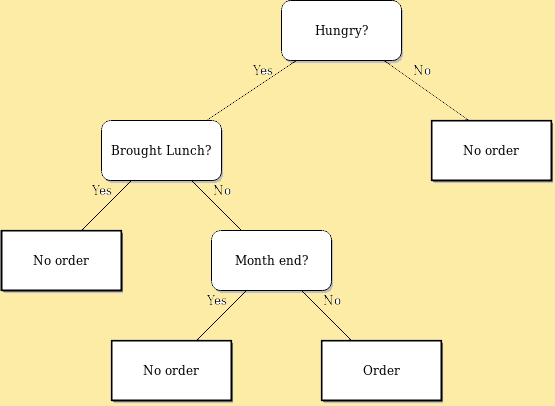
Suppose you’re an employee and you want to eat processed food.
Your course of action will depend on several circumstances.
If you aren’t hungry, you won’t spend money on junkies. But if you are hungry, then the choices are changed. Your next move depends on your next circumstance, i.e., have you bought lunch or not?
Now, if you don’t have lunch, your action will solely depend on your next pick, i.e., is it month-end or not? If it is the last few days of the month, you will consider skipping the meal; otherwise, you won’t take it as a preference.
Decision Trees come into play when there are several choices involved to arrive at any decision. Now you must choose accordingly to get a favorable outcome.
Tree-based learning algorithms are considered to be one of the best and mostly used supervised learning methods. Tree-based methods legitimize predictive models with better accuracy, stability, and ease of interpretation. Unlike contemporaries, they work well on non-linear relationships as well. Decision Tree algorithms are referred to as CART (Classification and Regression Trees).
How do Decision Trees work?
There are two components of Decision Trees:
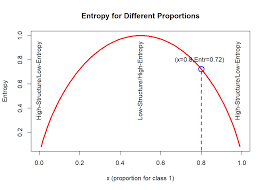
- Entropy — It is regarded as the randomness of the system. It is a measure of node purity or impurity.

Entropy is maximum when p = 0.5, i.e., both outcome has the same favor.
- Information gain — It is a reduction in entropy. It is the difference between the starting node’s uncertainty and the weighted impurity of the two child nodes.
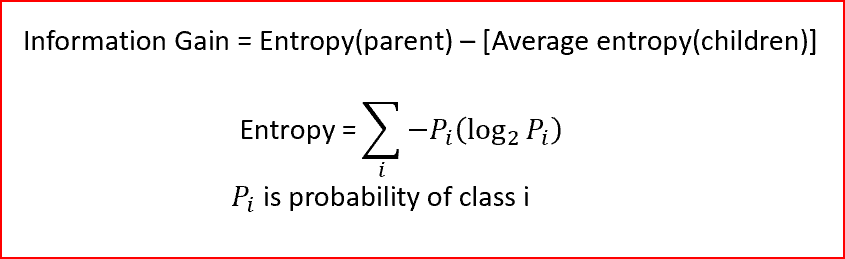
It helps us find the root node for our decision tree; the node with maximum Information Gain is regarded as the root node as it has maximum uncertainty.
We will first split the feature with the highest information gain. This is a recursive process until all child nodes are pure or until the information gain is zero.
Goal of Decision Tree: Maximize Information Gain and Minimize Entropy
Let’s say we have a sample of 60 students with three variables Gender (Boy/ Girl), Class (XI/ XII), and Weight (50 to 100 kg). 15 out of these 60 play football in their leisure time. Now, we want to create a model to predict who will play football during free time? In this problem, we need to divide students who play football in their leisure time based on a highly significant input variable among all three.
This is where the decision tree comes into play. It will classify the students based on all three variables’ values and identify the variable, which creates the best homogeneous sets of students.

Using a Decision Tree, we can easily solve our problem and classify students based on traits that whether they will prefer playing football in their leisure time or not?
Decision Trees Implementation from scratch
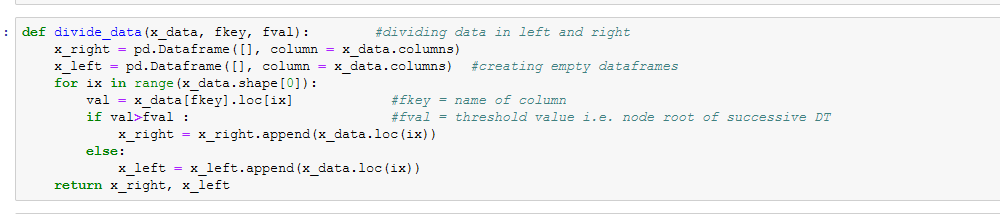

Sci-kit Learn implementation

Visualizing your Decision Tree

Pros & Cons of Decision Trees
Pros
- Easy to interpret
- Handles both categorical and continuous data well.
- Works well on a large dataset.
- Not sensitive to outliers.
- Non-parametric in nature.
Cons
- These are prone to overfitting.
- It can be quite large, thus making pruning necessary.
- It can’t guarantee optimal trees.
- It gives low prediction accuracy for a dataset as compared to other machine learning algorithms.
- Calculations can become complex when there are many class variables.
- High Variance(Model is going to change quickly with a change in training data)
Random Forest
Introduction to Random Forest
Random forest is yet another powerful and most used supervised learning algorithm. It allows quick identification of significant information from vast datasets. The biggest advantage of Random forest is that it relies on collecting various decision trees to arrive at any solution.
This is an ensemble algorithm that considers the results of more than one algorithms of the same or different kind of classification.
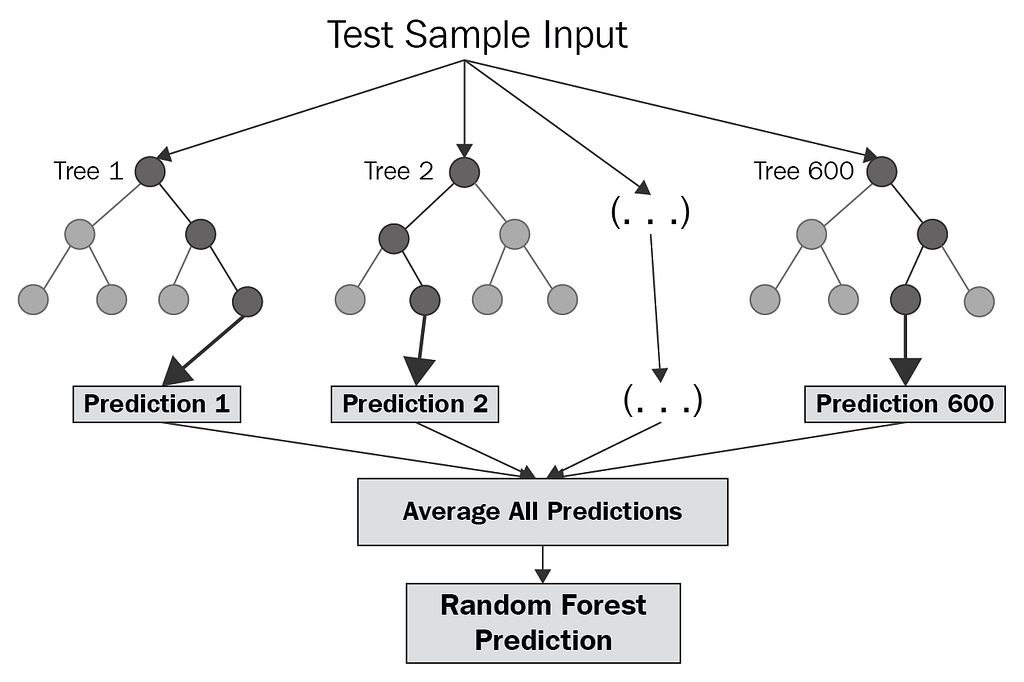

Suppose you want to go for a vacation but are baffled about the destination. So you decide to ask your friend Lakshay for advice. Lakshay will ask you about your last vacation and whether you liked it or not, what did you do there. To get precise results, he might even inquire about your preferences, and based on your remark, and he will provide you a recommendation. Here, Lakshay is using the Decision Tree technique to provide you feedback that is based on your response.
But you think Lakshay’s advice is a bit biased, and you asked Meghna(your other friend) the same question. She, too, came up with a recommendation, but you again considered it a dicey choice. You iterated this process and asked “n” friends the same question. Now you’re up to some common places recommended by your friends. You collect all the votes and aggregate them. You decide to go to the place with the most votes. Here, you are using a random forest technique.
The deeper you go, the more prone to overfitting you’re as you are more specified about your dataset in Decision Tree. So Random Forest tackles this by presenting you, the product of Decision Tree’s simplicity and Accuracy through Randomness.
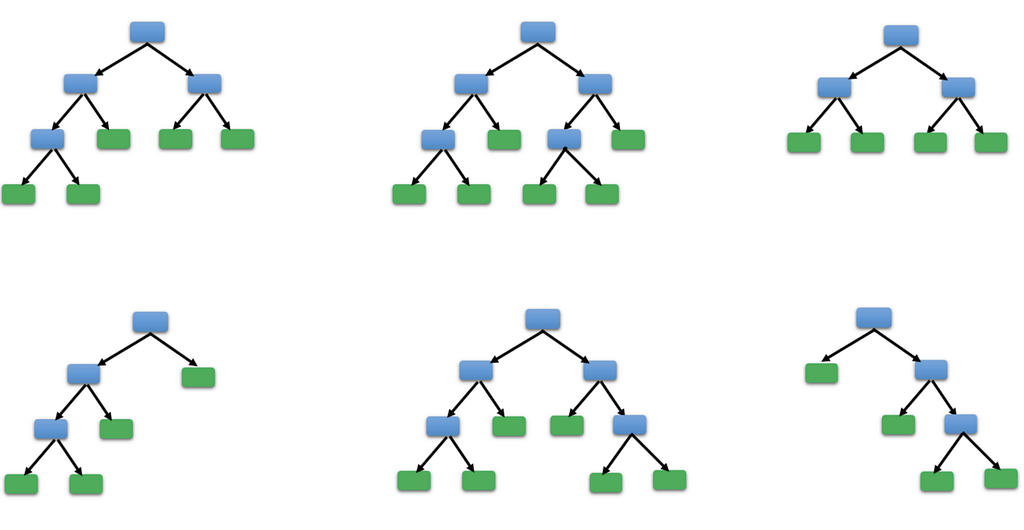
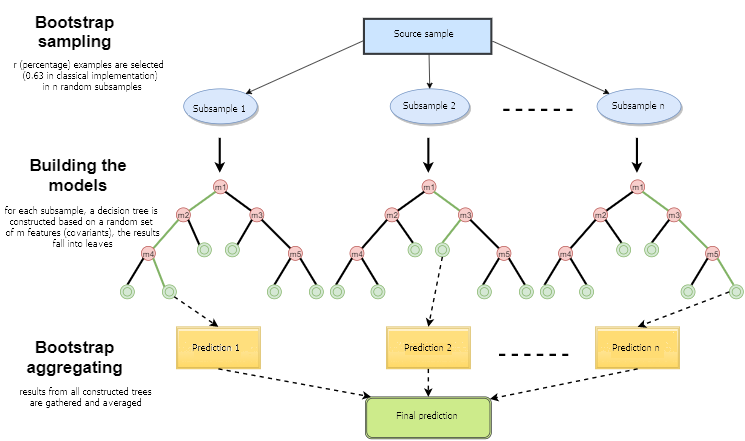
How does Random Forest Works?
Assume “m” features in our dataset:
- Randomly chose “k” features satisfying condition k < m.
- Among the k features, calculate the root node by choosing a node with the highest Information gain.
- Split the node into child nodes.
- Repeat the previous steps n times.
- You end up with a forest constituting n trees.
- Perform Bootstrapping, i.e., combining the results of all Decision Trees.
Sci-kit implementation for Random Forest
Pros & Cons of Random Forest
Pros:
- Robust to outliers.
- Works well with non-linear data.
- Lower risk of overfitting.
- Runs efficiently on a large dataset.
- Better accuracy than other classification algorithms.
Cons:
- Random forests are found to be biased while dealing with categorical variables.
- Slow Training.
- Not suitable for linear methods with a lot of sparse features
Conclusion
Hopefully, this article will help you understand Decision Trees and Random Forest in the best possible way and assist you in its practical usage.
As always, thanks so much for reading, and please share this article if you found it useful!
Feel free to connect:
LinkedIn ~ https://www.linkedin.com/in/dakshtrehan/
Instagram ~ https://www.instagram.com/_daksh_trehan_/
Github ~ https://github.com/dakshtrehan
Follow for further Machine Learning/ Deep Learning blogs.
Medium ~ https://medium.com/@dakshtrehan
Want to learn more?
Detecting COVID-19 Using Deep Learning
The Inescapable AI Algorithm: TikTok
Why are YOU responsible for George Floyd’s Murder and Delhi Communal Riots?
Clustering: What is it? When to use it?
Start off your ML Journey with k-Nearest Neighbors
Activation Functions Explained
Parameter Optimization Explained
Determining Perfect Fit for your ML Model
Cheers!
Why Choose Random Forest and Not Decision Trees was originally published in Towards AI — Multidisciplinary Science Journal on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Take our 90+ lesson From Beginner to Advanced LLM Developer Certification: From choosing a project to deploying a working product this is the most comprehensive and practical LLM course out there!
Towards AI has published Building LLMs for Production—our 470+ page guide to mastering LLMs with practical projects and expert insights!

Discover Your Dream AI Career at Towards AI Jobs
Towards AI has built a jobs board tailored specifically to Machine Learning and Data Science Jobs and Skills. Our software searches for live AI jobs each hour, labels and categorises them and makes them easily searchable. Explore over 40,000 live jobs today with Towards AI Jobs!
Note: Content contains the views of the contributing authors and not Towards AI.
Related posts


Popular posts

 for 2021")



Updates

Recent Posts



