



StyleGAN Generated Face Classification with ResNexts
Last Updated on July 20, 2023 by Editorial Team
Author(s): Luka Chkhetiani
Originally published on Towards AI.
Using ResNexts with StyleGAN U+007C Towards AI
A week or two back a team released a dataset of 100K images of generated faces, based on StyleGAN [Karras et al. and NVIDIA] (see paper).
We’ve seen similar tech open for public interaction a while ago on https://www.thispersondoesnotexist.com, which basically generates an entirely new face for every visit on the website.
The network is robust, and the work impressive, that’s for sure. And, to be completely honest, us, people in the field of ML/DL, especially if you’ve played with GANs, are familiar with Computer Vision, can somehow detect the fakeness.
Anyway, let me share a couple of red flags that generated images have in most cases:
1. Pixel Perturbation
Many of almost-perfect generated images have mutilated pixels, that look like
‘holes’.
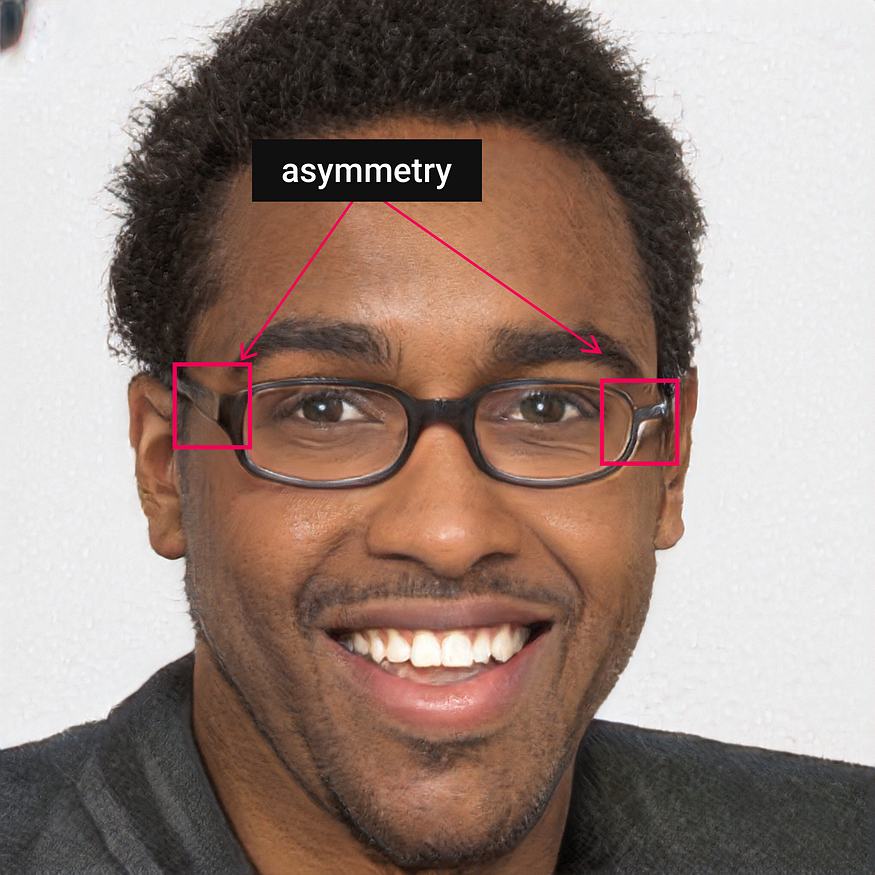
2. Asymmetry
Objects are asymmetrical. In this case, both sides of the glasses are different.
3. Weird side-object, asymmetrical teeth.
In case there’s another object present on image, we’ve destructed the idea of it. In this image, we see the idea of a person, but it seems to be weird.

4. Asymmetrical teeth, weird side-object
Again asymmetry and weird objects, but in this case asymmetry of teeth are much clearly illustrated, and the object gives us feeling like we know what it is, but can’t describe it.

5. Synthetic Skin
Skin in generated images is not well structured. Transitions, highlights, and sharpness are easy to spot.

6. Hair
Hair is messy in most of the cases, and are mixed with different objects, skin or background.

An obligation of data-usage
Well, when you see a royalty-free data, available publicly, it’s hard to not try it out. The generated images are free to use for commercial and research purposes ‘’just for a link back to them’’, as described in terms of use.
Speaking of Google Colab dependent person, it was really challenging to get the data altogether for a couple of reasons, such as a. having not total access while adding to my drive. b. well, there are 100K images, and Colab is really slow in case of reading/writing (moving, copying) media files.
And, I chose to use CelebA images for the “True” class.
So: Real Images: True, Generated Images: False
While analyzing the dataset, I’ve noticed a couple of differences, and similarities:
- Well, — quality. CelebA aligned images are pixelated, and have low quality, whereas StyleGAN generated images have Super Resolution (1024×1024)
- Background diversity — There are various backgrounds presented in CelebA images, such as banners, fields, cars, etc. But, we have an almost identical background in the case of generated ones.
- Brightness — CelebA images are naturally highlighted, whereas stylegan images have generated synthetic lights.

In this case, model will easily overfit on the data, for sure.
To make it clearer — I’m not building an optimal fake-face detector, just trying to classify the generated images of these specifications. So, a little bit overfitting is not a big issue.
I do my work in PyTorch, and I’ve incorporated two additional augmentations besides horizontal/vertical flipping and color jittering:
Clache filtering (histogram equalization algorithm):
We are taking 3 channels (LAB) where (L) channel denotes whiteness intensity on the image,
and is calculated between Black (0) and White(100).
A Channel — between Green (-) and Red (+)
B Channel — between Blue (-) and Yellow (+)

And, the histogram equalization for image g will be represented by
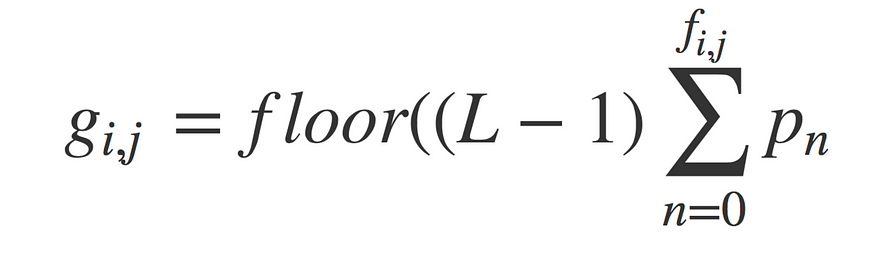
Brightness and contrast normalization

Pre-processed images by applying brightness and contrast normalization and CLACHE seems to distinguish the abnormalities of the images and make it as clear as possible.
The images are resized to 299×299.
ResNeXt
Idea is to use torchvision pre-trained ResNeXt-101 model by accomplishing the next steps:
- Training only network heads [lr=1e-3, SGD]
- Training Layer4 and up [lr=1e-3, SGD]
- Training the whole network [lr=1e-4, SGD]
Training and Results
Epoch 1 Train loss: 0.452.. Test loss: 0.495.. Test accuracy: 0.795 Epoch 1 Train loss: 0.363.. Test loss: 0.400.. Test accuracy: 0.827 Epoch 2 Train loss: 0.302.. Test loss: 0.331.. Test accuracy: 0.843 Epoch 2 Train loss: 0.166.. Test loss: 0.271.. Test accuracy: 0.880 Epoch 3 Train loss: 0.015.. Test loss: 0.252.. Test accuracy: 0.909 Epoch 3 Train loss: 0.062.. Test loss: 0.194.. Test accuracy: 0.911 Epoch 4 Train loss: 0.108.. Test loss: 0.183.. Test accuracy: 0.936 Epoch 4 Train loss: 0.029.. Test loss: 0.142.. Test accuracy: 0.964 Epoch 5 Train loss: 0.279.. Test loss: 0.135.. Test accuracy: 0.968 Epoch 5 Train loss: 0.119.. Test loss: 0.110.. Test accuracy: 0.973
The model has shown really promising results on the test set.
And, as long as in most cases models don’t perform the same way they show in the test set, and that happens because of many reasons: poor tuning, not normalizing data, etc., I always try to manually test them on unseen data.
By choosing 100 True and 100 False images for manual validation, I’ve ended up having only 3 errors, but the model was completely confused while doing prediction my social media profile picture after the validation procedure.
The idea of the whole writing was to encourage people to test their own ideas, try different approaches for the detection of fake-generated data, even though you might not have too much time for fine-tuning the model for research purposes in the different field than yours. Because, your work could be an inspiration for others, and we can really see the possible risks of impressive GANs usage for illegal purposes.
Link for tuned model:
ResNext101 – Google Drive
Edit description
drive.google.com
You can use it by simply loading with torch.load() function, and declaring classes = [‘generated’,’groundtruth’].
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts


")



