


Semantic Tagging: Create Meaningful Tags for your Text Data
Last Updated on March 13, 2024 by Editorial Team
Author(s): Gabriele Sgroi, PhD
Originally published on Towards AI.
Introduction
Textual information can be found in almost every area of individual and organizational activities. Handling this huge amount of data and harnessing its power requires the implementation of effective data strategies. Due to the difficulties and costs of implementing the appropriate policies, much of this valuable information is often overlooked and not effectively exploited.
Textual tags can constitute an extremely powerful tool to organize, analyze, and extract insight from vast amounts of unlabeled text information. The range of possible applications for textual tags is vast, ranging from information retrieval to topic modeling and classification. They can, for example, be used in the retrieval process of RAG systems, to extract keywords and sentiment from text corpora, to perform topic modeling, etc. One of their main advantages over other kinds of labeling or clustering is that they provide information about the content of the documents they label in a way that is easily interpretable by human users.
While creating textual tags may be a daunting and expensive task, today’s Large Language Models (LLMs) capabilities can help to automate the process. In fact, they can tag a large amount of text documents much faster and cheaper than human labelers. However, even though pre-trained general Large Language Models can easily create tags relevant to a provided input text, there is no easy way to control the criteria according to which the tags are selected.
This is where modern fine-tuning techniques come to help. Direct Preferect Optimization (DPO), introduced in the paper Direct Preference Optimization: Your Language Model is Secretly a Reward Model, is a powerful technique that makes it possible to fine-tune LLMs so that their outputs are aligned with a given set of preferences. One of its main advantages with respect to PPO-based Reinforcement Learning from Human Feedback (RLHF), another popular way of aligning LLMs with human preferences, is that it doesn’t require a separately trained reward model while being considerably simpler to implement and train. Identity Preference Optimization (IPO), proposed in A General Theoretical Paradigm to Understand Learning from Human Preferences, builds on top of the DPO framework by proposing a modified objective that alleviates the overfitting typical of DPO.
Analogously to DPO, IPO requires a text dataset of pairwise preferences, associating to each input two different generations with an expressed preference towards one of them. The model fine-tuned with IPO will produce outputs that reflect the preferences expressed in the dataset.
Collecting a preference dataset can be an expensive and time-consuming process, but again this task can be automated using a Large Language Model to annotate the preferences. This is, for example, the principle at the base of Reinforcement Learning from AI Feedback (RLAIF).
In this blog post, I will explain how to fine-tune a Large Language Model with Identity Preference Optimization (IPO) to create semantically meaningful tags for texts. In particular, the preference dataset will be created automatically by collecting pairs of generations from the pre-trained LLM for different text inputs and choosing the preferred answer based on the semantic similarity between the input text and the generated tags. Semantic similarity is estimated through the cosine similarity between the embeddings of the input text and of the generated tags obtained using an embedding model. The entire process of data creation and fine-tuning is illustrated in the picture below.
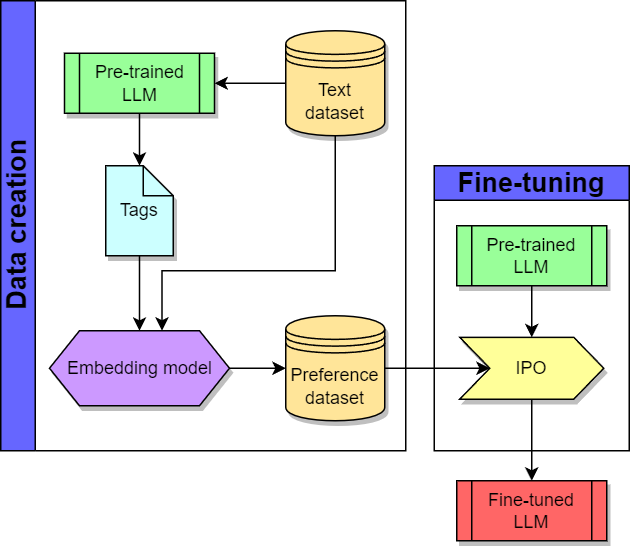
The LLM I used for the experiments presented in this post is zephyr-7b-alpha, a fine-tuned version of Mistral 7b. For the embedding model, I used gte-large, a general text embedding model introduced in the paper Towards General Text Embeddings with Multi-stage Contrastive Learning. Any equivalent generative LLM and embedding model can be used in their place.
The code I used to perform the experiments is available in this GitHub repository.
Creating the data
As mentioned in the introduction, the preference data needed to fine-tune the model using Identity Preference Optimization can be obtained automatically by the model itself, without the need for human labeling. In this section, I will go over the details of the dataset creation.
In order to fine-tune the model using IPO, the first step is to obtain pairs of tags for a dataset of input texts. In my experiments, I used the contexts of the squad_v2 dataset, introduced in SQuAD: 100,000+ Questions for Machine Comprehension of Text, as the input texts.
The tags have been created by the pre-trained LLM, using the following prompt
<U+007CsystemU+007C>
You are an expert chatbot tagging chunks of texts based on their content.
Write a maximum of three short labels representing the texts between square brackets and nothing else.
Follow this format [tag1][tag2][tag3]</s></s>
<U+007CuserU+007C>
Write labels for the following text: {text}</s>
<U+007CassistantU+007C>
The string {text} is substituted for each instance with the input text to tag. The number of tags to generate has been limited to three to reduce the generation length (and thus reduce the memory requirements) and to make the model summarize the content of the input text, capturing only the most important concepts. Otherwise, the model could easily learn to copy a large part of the text and put it into tags, as this will have a high semantic similarity to the input text. The number of tags to generate can be easily adjusted based on the length and complexity of the texts to tag. The model is asked to wrap the tags in parenthesis for an easy parsing of the answer.
In the experiments performed with zephyr-7b-alpha, a relevant number of responses generated in this way don’t have the correct desired format [tag1][tag2][tag3] specified in the prompt. This is due to several different kinds of “mistakes” in the model answer, the most frequent ones I encountered are:
- The model generates a verbose answer instead of producing the tags;
- The model generates more than 3 tags;
- The parenthesis are not open/closed correctly;
- The model adds some text before/in between/after the tags;
- The answer is truncated due to reaching the maximum number of tokens leading to inconsistent parentheses.
These are undesirable responses for a reliable tagger, but fortunately, their occurrences can be greatly limited with fine-tuning. It is then natural to include some example pairs expressing preference towards answers with the correct format in the dataset. In particular, whenever the model generates one valid response and one with the wrong format for a given prompt, the valid one is marked as the preferred response in the IPO setting. Since the main goal of the model is to create semantic similar tags, it is important not to include too many such pairs as they could otherwise shift the preference distribution leading to a fine-tuned model that only focuses on providing answers with the correct format, disregarding the tags similarity to the input text. In experiments reported in the next section, I limited the occurrences of such data points to 20% of the total data. Furthermore, to reduce the computational cost associated with the generation of the tags, when it was possible to extract some valid tags from an answer with the wrong format, I automatically extracted them (capping their number to three) and recreated an answer with the correct format.
When the model produces pairs of answers with the correct format, preference is computed by comparing the semantic similarity of the tags with the reference text. Semantic similarity is estimated with the help of an embedding model, which produces embeddings for both the text and the tags and evaluates their cosine similarity. The generation with the higher similarity with the text embeddings is preferred over the other.
In my experiments, I created tags for some distinct contexts extracted from the squad_v2 dataset, a popular question-answering dataset. In total, I collected a dataset of 7526 preference pairs. Around 20% of the dataset consists of preferences based on the correct/incorrect format of the answers, as explained previously. This is a relatively small dataset, and the performance of the model can probably be easily increased by creating more data. The embeddings of the tags are obtained by combining the extracted tags into a single string, separated by commas, before feeding them to the gte-large model.
Fine-tuning the model
Once the preference dataset has been created, the model can be fine-tuned using IPO directly on the preferences without the need to create a reward model.
The IPO objective aims to increase the probabilities the model assigns to the preferred choices with respect to the probabilities assigned to the dispreferred choices, with a regularization that keeps them not too far from a reference policy, typically the pre-trained LLM itself. The regularization is important to preserve the language capabilities acquired by the pre-trained model, as they could otherwise be easily forgotten during fine-tuning, as well as to reduce overfitting.
The IPO algorithm minimizes the following objective:
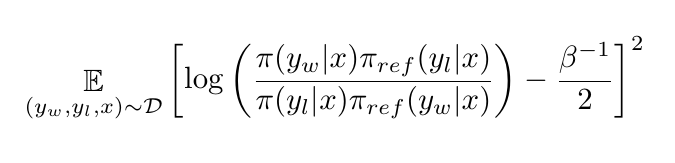
In particular, IPO fine-tunes the model by regressing the log-likelihood ratio between the preferred completion and the dispreferred completion of the model policy to the same log-likelihood ratio for the reference policy increased by half the inverse of the regularization parameter beta. Thus, the smaller the beta parameter, the more the fine-tuned model will assign higher probabilities to the preferred completions compared to the reference model. On the other hand, a larger beta parameter will have a stronger regularization effect, discouraging the fine-tuned model from differing too much from the pre-trained model. In fact, a large deviation would move the difference between the log-likelihood ratios of the fine-tuned model and the reference model policies far from half of the inverse of beta. In my experiments, I set the parameter beta to 0.1.
The IPO algorithm can be combined with techniques for performance-efficient fine-tuning, such as quantization and LoRA, to reduce the memory footprint. These techniques can be combined seamlessly thanks to the Hugging Face libraries peft and trl. In particular, the latter provides the class DPOTrainer (which performs IPO fine-tuning specifying loss_type= ‘ipo’) that can accept a peft configuration (or directly a peft model) to perform fine-tuning using LoRA.
In the experiments reported in this post, I fine-tuned zephyr-7b-alpha with 4-bit quantization and LoRA with rank 16. This configuration fits on a free T4 Colab GPU.
Results
In this section, I will present the results of some experiments on the model fine-tuned with IPO over 7526 preference pairs obtained from the train split of the squad_v2 dataset as explained in the previous sections. I have tested the model over a random sample of 1000 distinct contexts of the “validation” split of the squad_v2 dataset. This split has not been used during training (not even for validation), so these examples have never been encountered by the fine-tuned model.
For the first test, I compared the fraction of answers generated by the model with the correct format before and after IPO fine-tuning. As specified in previous sections, the model has been prompted asking it to generate, for each input text, an answer that has the form [tag1][tag2][tag3] followed possibly by stop tokens </s> and with at most 3 tags per text. When checking if an answer has the correct format, I ignore white spaces and stop tokens, asking only that it consists of at most 3 tags inside square brackets. Limiting the maximum number of generated tokens to 32, before fine-tuning zephyr-7b-alpha returned an answer with the correct format for 85% of the data in the test set. After fine-tuning with IPO on the dataset created as specified in previous sections, the percentage of generation with the correct format reached 99.1%. This is a considerable improvement from the performance of the base model, especially considering that only 20% of the training data (around 1500 examples) consisted of correct/wrong format pairs.
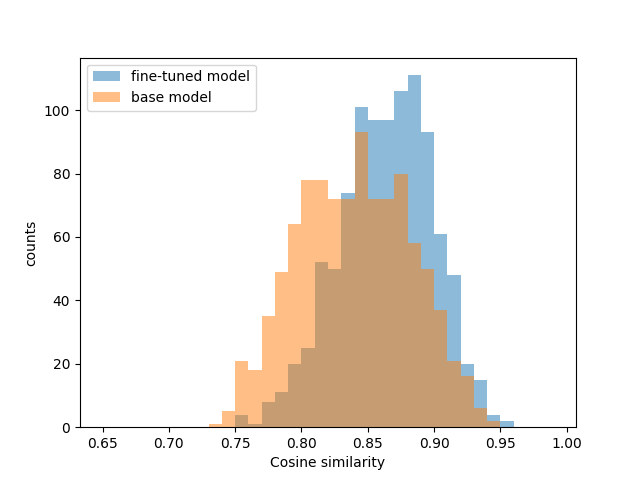
As a second test, I compared the semantic similarity of the generated tags to the test texts. The tags are extracted from the model answers and put into the format ‘tag1, tag2, tag3’. Similarity to the texts has been computed using cosine similarity between the embeddings of the reference texts and those of the tags. The embeddings have been obtained using the gte-large model, the same embedding model used to create the preferences for the training data. The tags created with zephyr-7b-alpha before fine-tuning had an average cosine similarity with the reference texts of 0.840±0.001 and a standard deviation of 0.042. After fine-tuning with IPO, the average similarity increased to 0.863±0.001 with a standard deviation of 0.035.
Below is a histogram showing the number of examples grouped by cosine similarity between the tags and the reference texts.
Let us now visualize some illustrative examples of the completions generated by the model before and after fine-tuning for a qualitative comparison.
Example 1
Victorian schools are either publicly or privately funded. Public schools,
also known as state or government schools, are funded and run directly by the
Victoria Department of Education . Students do not pay tuition fees, but some
extra costs are levied. Private fee-paying schools include parish schools run
by the Roman Catholic Church and independent schools similar to British public
schools. Independent schools are usually affiliated with Protestant churches.
Victoria also has several private Jewish and Islamic primary and secondary
schools. Private schools also receive some public funding. All schools must
comply with government-set curriculum standards. In addition, Victoria has four
government selective schools, Melbourne High School for boys, MacRobertson
Girls' High School for girls, the coeducational schools John Monash Science
School, Nossal High School and Suzanne Cory High School, and The Victorian
College of the Arts Secondary School. Students at these schools are exclusively
admitted on the basis of an academic selective entry test.
Base model: [education][funding][private-schools]
[public-schools][government-funded][Victoria]
[private
Fine-tuned model: [Victorian education][Public and private schools]
[Selective schools]</s>
In this case, we can see a failure of the pre-trained model to comply with the instruction to furnish at most 3 tags before fine-tuning. The answer was truncated after reaching the maximum number of tokens set for the completion and it contains more than 3 tags. The fine-tuned model correctly provides 3 relevant tags keeping its answer concise.
Example 2
The centrifugal governor was adopted by James Watt for use on a steam engine in
1788 after Watt’s partner Boulton saw one at a flour mill Boulton & Watt were
building. The governor could not actually hold a set speed, because it would
assume a new constant speed in response to load changes. The governor was able
to handle smaller variations such as those caused by fluctuating heat load to
the boiler. Also, there was a tendency for oscillation whenever there was a
speed change. As a consequence, engines equipped only with this governor were
not suitable for operations requiring constant speed, such as cotton spinning.
The governor was improved over time and coupled with variable steam cut off,
good speed control in response to changes in load was attainable near the end
of the 19th century.
Base model: [technology][history][engineering]</s>
Fine-tuned model: [steam engine][governor][improvement]</s>
In this instance, the base pre-trained model is able to follow the instructions provided and furnish 3 correctly formatted tags, listing some generic categories for the context provided. We can see how the tags produced by the fine-tuned model are much more specific and closer to the content of the input text. This reflects the fact that the model has been fine-tuned to improve the semantic similarity between the generated tags and the input text.
Example 3
Many questions regarding prime numbers remain open, such as Goldbach's
conjecture (that every even integer greater than 2 can be expressed as the sum
of two primes), and the twin prime conjecture (that there are infinitely many
pairs of primes whose difference is 2). Such questions spurred the development
of various branches of number theory, focusing on analytic or algebraic aspects
of numbers. Primes are used in several routines in information technology, such
as public-key cryptography, which makes use of properties such as the
difficulty of factoring large numbers into their prime factors. Prime numbers
give rise to various generalizations in other mathematical domains, mainly
algebra, such as prime elements and prime ideals.
Base model: [math][number theory][cryptography]</s>
Fine-tuned model: [number theory][prime numbers][cryptography]</s>
In this example, we see that the texts generated by the model before and after fine-tuning are very similar to each other, although the fine-tuned model answer exchanges the tag [math] with [prime numbers], which is more specific and reflects better the content of the text. The fact that the fine-tuned model answers don’t deviate much in some cases is expected as IPO explicitly includes a regularization factor that prevents the fine-tuned model from deviating too much from the base model. In some other cases, in fact, the model answers before and after fine-tuning are the same.
Conclusion
This blog post covered the basic steps necessary for the fine-tuning of a Large Language Model using Identity Preference Optimization to create textual tags with improved semantic similarity to the reference texts.
The process of creating the preference dataset necessary to perform IPO can be completely automatized by generating tags with the pre-trained model and scoring them using the embedding model. This makes it possible to scale the size of the preference dataset effortlessly by exploiting the capabilities of the pre-trained Large Language Model paired with a sufficient amount of computing power.
In the experiments presented in the post, fine-tuning even on a relatively small dataset is sufficient to increase both the accuracy of the format of the model answers and their semantic similarity to the reference texts. Interestingly, the base model employed (zephyr-7b-alpha) can generate relevant tags with a good semantic similarity to the reference texts even before fine-tuning, although it often doesn't respect the required output format and provides quite generic tags. After fine-tuning, the accuracy of the output format is greatly increased, and the tags are more specific and more closely reflecting the content of the reference texts. This result is supported both by quantitative (accuracy of the answer format, average cosine similarity of the tags) and qualitative evaluations.
The performance of the fine-tuned model presented in the experiment can be easily improved by scaling up the size and diversity of the dataset used to generate the preference tags. Furthermore, it may be beneficial, when creating the preference dataset, to generate more than two tags for each input text and balance the dataset so that the model is trained both on instances in which the difference of semantic similarity between the preferred and dispreferred generations is small and on instances with a larger difference. On this note, it could be even more interesting to experiment with methods such as Listwise Preference Optimization that optimize the model from a ranked list of preferences instead of pairwise preferences.
You can check the code used to perform the experiments in this post in this GitHub repository.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Related posts


Popular posts

 for 2021")



Updates

Recent Posts



