



SAM: A Image Segmentation Foundation Model
Last Updated on May 18, 2023 by Editorial Team
Author(s): Poojatambe
Originally published on Towards AI.
Segment Anything Model by Facebook’s Meta AI Research
With new advances in Generative AI, large-scale models called foundation models are developed. The foundation models are trained on a massive amount of unannotated data and can adapt to a wide range of downstream tasks.
In natural language processing, these foundation models (large language models) are pre-trained on web-scale datasets. With zero-shot and few-shot learning, these models can adapt to new datasets and tasks like translation and summarization. This is implemented with prompt engineering.
On the same grounds, SAM (Segment Anything Model) is built as a foundation model for image segmentation in computer vision. It reduces task-specific annotation, training, and modeling for image segmentation.
A SAM is based on three components task, model, and data. The task defined is a promptable segmentation task to return a valid segmentation mask for any prompt.
- A prompt can be any information indicating what to segment in an image. There are 2 types of prompts:
- Sparse Prompt: Foreground/ background points, bounding boxes, and text.
- Dense Prompt: Masks.
- A valid mask means that even when a prompt is ambiguous and could refer to multiple objects (for example, a point on a shirt may indicate either the shirt or the person wearing it), the output should be a reasonable mask for one of those objects.
Architecture
The promptable segmentation requires a model that supports flexible prompting and computes masks in real-time to allow interactive use and must be ambiguity aware. Hence, SAM (Segment Anything Model) has proposed that contains 3 components, image encoder, prompt encoder, and mask decoder.
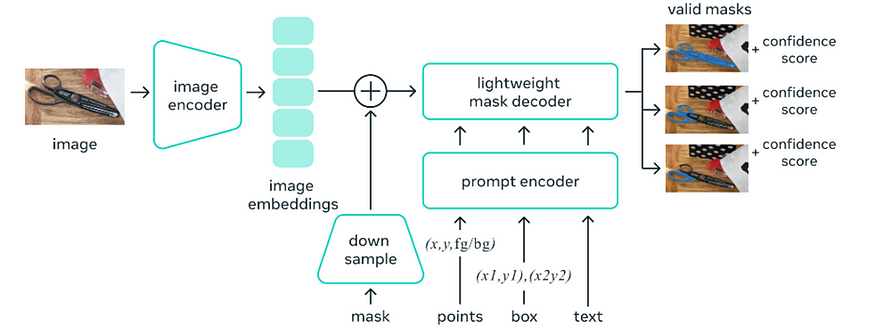
- Image Encoder:· It uses MAE pre-trained Vision Transformer (ViT). A heavyweight Image encoder on the server side computes image embeddings once per image that can be used any number of times with different prompts to avoid computational overheads. The image encoder has 632M parameters.
- Prompt Encoder: Sparse prompts like points, and boxes are embedded using positional encoding, and text uses CLIP embeddings. These learned embeddings are summed up. Dense prompts like masks are embedded using convolutions summed element-wise with image embeddings. The prompt encoder and mask decoder has 4M parameters.
- Mask Decoder: The mask decoder efficiently maps the image embedding, prompt embeddings, and an output token to a mask. It uses a modified Transformer decoder followed by a dynamic mask prediction head.
- If the given prompt is ambiguous, at output 3 masks are generated (whole, part, and subpart) for a single prompt with a corresponding confidence score to resolve ambiguity.
- With precomputed image embeddings lightweight mask decoder and prompt encoder take ~55 ms on a web browser without GPU for implementation.
- For training, a linear combination of focal loss and dice loss is used to supervise mask prediction.
Data Engine
To train the SAM model, the segmentation masks are not abundant on the internet, hence data engine is created to collect a 1.1 Billion mask, SA-1B dataset. It has 3 stages:
- Assisted manual stage: The model is trained with public segmentation dataset. The output masks are corrected manually and after gathering sufficient corrected data model is re-trained. The model is trained 6 times.
- Semi-automatic stage: Additional unlabeled images are annotated in much more detail to improve diversity. The periodic retraining takes place 5 times.
- Fully automatic stage: As the model was able to predict valid masks in ambiguous cases, it is prompted with a 32 X 32 grid of points. For each point set of masks predicted, including valid objects. The confident and stable masks are selected and NMS is applied to remove duplicates. To improve the quality of small masks, overlapping zoomed-in image crops are processed.
Dataset (SA-1B)
It contains 11 M diverse images (3300×4950 pixels resolution and downsampled to 1500 pixels for storage challenges) and 1.1 B masks (99.1% of masks are fully automatically generated).
Zero-shot Transfer Experiments
By engineering appropriate prompts SAM can resolve downstream tasks. In addition to automatic labeling, SAM performs segmenting an object from a single foreground point, a low-level task of edge detection, a mid-level task of object proposal generation, a high-level task of instance segmentation, and a higher-level task of segmenting objects from the free-form text as a proof-of-concept.
Let’s check instance segmentation with SAM.
For high-level tasks of instance segmentation, SAM can be used as a segmentation module. For this, we need to first run the object detector and the output of the object detector passes as a prompt to a SAM module.
- Here, yolov8 is taken as an object detector trained on the food dataset to detect classes: croissants, cookies, and cupcakes.

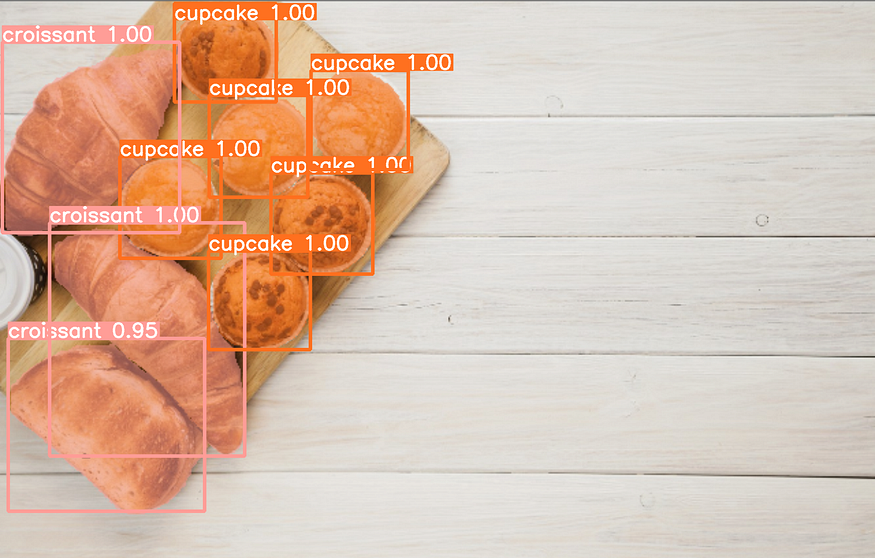
2. The output bounding boxes are fed as a prompt to a SAM module to do zero-shot segmentation. Refer code on the Github repo.

Summary
- A SAM can segment objects by clicking points to include and exclude the object. It also uses a bounding box as a prompt,
- To avoid ambiguity, multiple valid masks are generated when the prompt provided is ambiguous.
- It can automatically detect all objects from the image and mask them.
- As image embeddings are precomputed, SAM can generate masks for any prompt in real time.
- SAM can be prompted with gaze points detected by a wearable device, enabling new applications. It can become a powerful component in domains such as AR/VR, content creation, scientific domains, and more general AI systems.
Reference
- https://ai.facebook.com/blog/segment-anything-foundation-model-image-segmentation/
- https://arxiv.org/pdf/2304.02643.pdf
- https://github.com/facebookresearch/segment-anything
- https://www.youtube.com/watch?v=qa3uK3Ewd9Q
- https://github.com/ultralytics/ultralytics
Happy Learning!!!
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts



")


