Logo:
Logo:  Areas Served:
Areas Served: NLP News Cypher | 06.21.20
Last Updated on July 27, 2023 by Editorial Team
Author(s): Ricky Costa
Originally published on Towards AI.
NATURAL LANGUAGE PROCESSING (NLP) WEEKLY NEWSLETTER
NLP News Cypher U+007C 06.21.20
Bravehearts
When it comes to cyber hacks, NSA is the 3-letter agency to keep your eye on. And if you are wondering how they hack our emails, well, it involves clocks, prime numbers, and elliptic curves U+1F92F. In the video below, you will be introduced to the math used for creating random number generation used by cybersecurity algorithms for every-day encryption as used by credit cards or emails.
The reason why security software is efficacious is due to their encrypted “random” number sequences, which makes them unpredictable and hence, secure. But what if there is a backdoor to these random number generations so they become predictable? In essence, this is what the NSA figured out. To see how they did it, let’s go down the rabbit hole:
This Week:
MMF Multi-Modal Framework
IR From Structured Documents
SpaCy Update
Intro to Knowledge Graphs
Long Form Question Answering
Model Quantization in TF Lite
Deep Learning in Production
Dataset of the Week: TVQA
MMF Multi-Modal Framework
Hey Now! Facebook, more specifically PyTorch, have released their Multi-Modal Framework! It comes with…
“state-of-the-art vision and language pretrained models, a number of out-of-the-box standard datasets, common layers and model components, and training + inference utilities.”
You can use MMF for several different multi-modal tasks: VQA, image captioning, visual dialog, hate detection and others.

List of current available models:
- M4C Iterative Answer Prediction with Pointer-Augmented Multimodal Transformers for TextVQA [arXiv] [project]
- ViLBERT ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks [arXiv] [project]
- VisualBert Visualbert: A simple and performant baseline for vision and language [arXiv] [project]
- LoRRA Towards VQA Models That Can Read [arXiv] [project]
- M4C Captioner TextCaps: a Dataset for Image Captioning with Reading Comprehension [arXiv] [project]
- Pythia Pythia v0. 1: the winning entry to the vqa challenge 2018 [arXiv] [project]
- BUTD Bottom-up and top-down attention for image captioning and visual question answering [arXiv] [project]
- MMBT Supervised Multimodal Bitransformers for Classifying Images and Text [arXiv] [project]
- BAN Bilinear Attention Networks [arXiv] [project]
Blog:
Bootstrapping a multimodal project using MMF, a PyTorch powered MultiModal Framework
A solid foundation for your next vision and language research/production project
medium.com
GitHub:
facebookresearch/mmf
MMF is a modular framework for vision and language multimodal research from Facebook AI Research. MMF contains…
github.com
IR From Structured Documents
Remember OCR U+1F9D0? Some technologies never die, well Google has created a model for extracting information from structured documents. The architecture uses OCR to extract text from documents such as PDFs or scanned docs, afterward it uses a candidate generator to match fields from a target schema. In the end, fields are given a likelihood score to rank the extraction to the expected target.
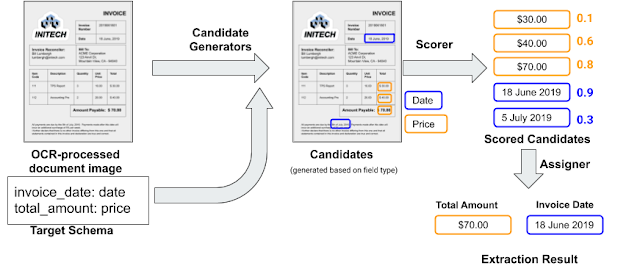
Blog:
Extracting Structured Data from Templatic Documents
Templatic documents, such as receipts, bills, insurance quotes, and others, are extremely common and critical in a…
ai.googleblog.com
SpaCy Update
SpaCy has a brand new update to its library highlighting new languages and tutorials (and more!). They added 5 new languages: Chinese, Japanese, Danish, Polish, and Romanian. In addition to new languages, SpaCy also improved model loading time and new online courses found here:
Tutorials:
Advanced NLP with spaCy · A free online course
spaCy is a modern Python library for industrial-strength Natural Language Processing. In this free and interactive…
course.spacy.io
Updates Summary:
Introducing spaCy v2.3 · Explosion
spaCy now speaks Chinese, Japanese, Danish, Polish and Romanian! Version 2.3 of the spaCy Natural Language Processing…
explosion.ai
Intro to Knowledge Graphs
A nice intro to knowledge graph embeddings which briefly discusses Amazon’s knowledge graph library DGL-KE built on top of the Deep Graph Library (DGL).
Blog:
Introduction to Knowledge Graph Embedding with DGL-KE
Author: Cyrus Vahid, Principal Solutions Engineer, AWS AI
towardsdatascience.com
DGL-KE GitHub:
awslabs/dgl-ke
Documentation Knowledge graphs (KGs) are data structures that store information about different entities (nodes) and…
github.com
Long-Form Question Answering
Hugging Face recently released a demo for long form question answering which takes in a question, fetches passages from Wikipedia, and writes a multi-sentence explanation to the question. Meaning, this is not extractive QA like SQuAD-like models. Instead, it uses a sparse model (Elasticsearch) to retrieve top wiki passages that loosely link to the question and then use a dense model (Faiss) which embeds questions/answers trained on the ELI-5 dataset. In the end, they use BART for generating answers. Pretty cool and efficient!
Blog/Notebook:
Long_Form_Question_Answering_with_ELI5_and_Wikipedia
Imagine that you are taken with a sudden desire to understand how the fruit of a tropical tree gets transformed into…
yjernite.github.io
Demo:
Streamlit
Edit description
huggingface.co
Model Quantization in TF Lite
Great blog post from Sayak Paul on model quantization to be used for edge devices like mobile. It gives a lucid introduction to quantization (post-training quantization & quantization-aware training) and how it can fit with TensorFlow Lite.
Blog:
A Tale of Model Quantization in TF Lite
Model optimization strategies and quantization techniques to help deploy machine learning models in resource…
app.wandb.ai
GitHub:
sayakpaul/Adventures-in-TensorFlow-Lite
This repository contains notebooks that show the usage of TensorFlow Lite for quantizing deep neural networks in…
github.com
Deep Learning in Production
Some sobering stats for AI models used in production such as “the majority of companies (59%) are not optimizing their machine learning models in production”(they should read the previous post on quantizationU+1F9D0) . If you enjoy anxiety, then check out these new survey results to see how enterprise developers are sweating bullets on the daily. FYI, TensorFlow is still popular in production.
Companies Lack Resources to Get Deep Learning Models into Production [Survey] – Neural Magic
How many deep learning models do companies typically have in production? A lot fewer than you'd think. 84% of companies…
neuralmagic.com
Dataset of the Week: TVQA
What is it?
Dataset is used for video question answering and consists of 152,545 QA pairs from 21,793 clips, spanning over 460 hours of video.
Sample:

Where is it?
TVQA Dataset
Download link: tvqa_qa_release.tar.gz [15MB] md5sum: 7f751d611848d0756ee4b760446ef7cf file contains 3 JSON Line files…
tvqa.cs.unc.edu
Every Sunday we do a weekly round-up of NLP news and code drops from researchers around the world.
If you enjoyed this article, help us out and share with friends!
For complete coverage, follow our Twitter: @Quantum_Stat
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Related posts
Popular posts

 for 2021")



Updates

Recent Posts