



MLOps Demystified…
Last Updated on October 10, 2020 by Editorial Team
Author(s): Shubham Saboo
Machine Learning
MLOps is modeled on the existing discipline of DevOps, the modern practice of efficiently building, deploying, and running enterprise-grade applications to shorten the systems development life cycle and provide continuous delivery/deployment on the go with tested high-quality software.
As Machine Learning at an organization matures from research to applied enterprise solutions, there comes the need for automated Machine Learning operations that can efficiently handle the end-to-end ML Lifecycle.
In the initial phase of the evolving technological industry, the DevOps process paved the way for efficient management of the software development life-cycle. As the adoption of AI-first solutions is becoming mainstream for the world’s largest enterprises, ML-Ops turns out to be the need of the hour.
After this brief context, you might be wondering that we already have tried and tested DevOps practices in place then why do we need MLOps?
MLOps is about innovatively applying the existing DevOps practices to automate the building, testing, and deployment of large scale machine learning systems. The Continuous Delivery Foundation’s SIG-MLOps defines MLOps as “the extension of the DevOps methodology to include Machine Learning and Data Science assets as the first-class citizens within the DevOps ecology”.
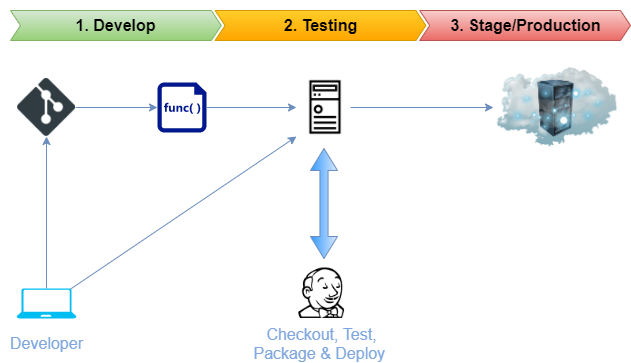
Git is the global standard for the source-code version control systems. It is used to track changes in source code over time and support different versions of source code. Support for version control is a prerequisite for continuous integration (CI) solutions as it enables reproducible provisioning of any environment in a fully automated fashion. In most of the standard DevOps setup, Jenkins is used in collaboration with git to efficiently build, test, and deploy versioned code in a controlled environment.
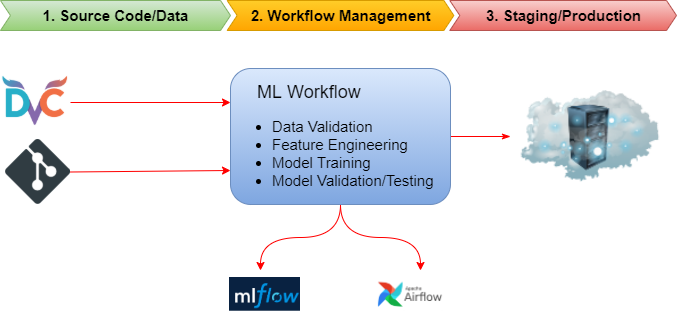
In the case of MLOps, the CI/CD workflows get triggered either by a change in source code or data. It introduced the idea of Data Version Control (DVC) for which there aren’t any standard systems like git, but many data organizations and open source communities are coming up with various solutions.
Why DVC is challenging?
While code is carefully crafted in a controlled development environment and can be easily managed through Version control systems like git, data is a constantly evolving parameter that comes from the unending source of entropy known as the “real world”. It is constantly changing, with no way to predict what shape it will take in the future. A useful way to think of the relationship between data and code is that both of them live in separate planes totally independent of each other but still share the time dimension.
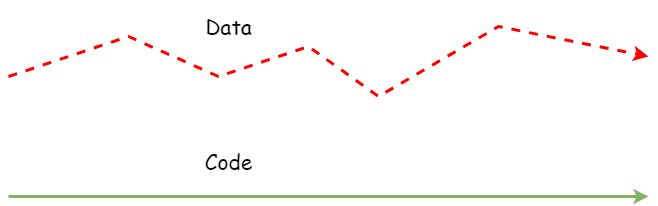
The key difference between DevOps and MLOps is the requirement of data versioning along with the source code in ML systems.
MLOps Level 0: Manual Processes
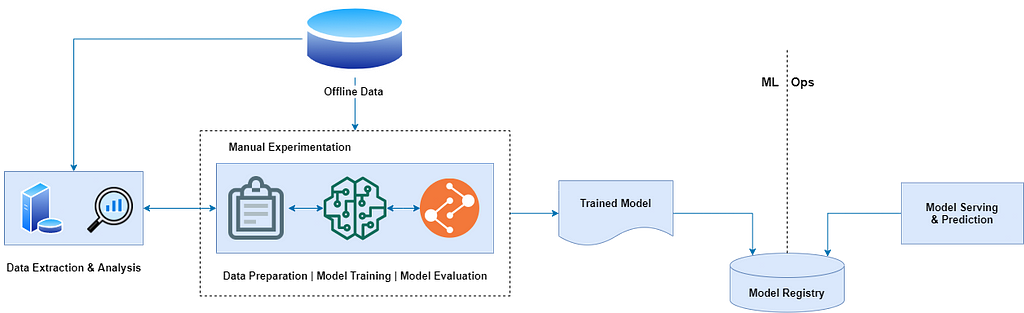
Many organizations today have data scientists and ML researchers who can build state-of-the-art machine learning models but their process for building and deploying ML models is entirely manual. This is considered as a basic level of maturity or level-0. Following are the characteristic challenges with manual machine learning or MLOps level-0:
- It involves manual, script-driven execution of each step with a constant requirement of human touch (Far from the goal of becoming zero-touch).
- There is a huge discontinuity between ML development and operations. It creates an added dependency by separating the data scientists from the engineers who serve the model as a prediction service. The handoff between the two parties can lead to training-serving skew.
- The manual process wasn’t designed to incorporate frequent release iterations due to model retraining or change in data. It was assumed that a model once trained will serve the purpose for years.
- It doesn’t take into account the tracking and logging of model predictions and metrics for each prediction which results in a lack of collaboration and in turn transparency within data teams.
MLOps Level 1: Automated ML Life Cycle
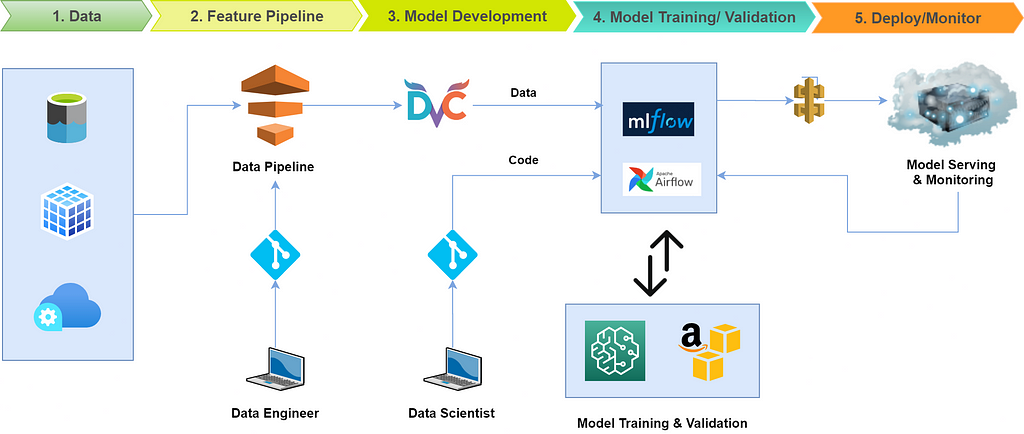
The goal of level 1 MLOps is to perform continuous training of the model by automating the entire machine learning pipeline which in turn leads to continuous delivery of prediction service. The underlying concept which empowers the continuous model training is the ability to do data version control along with efficient tracking of training/evaluation events. Following are the characteristic features of MLOps level-1 which empower the entire machine learning life-cycle:
- It provides us with the capability to perform rapid experimentation by efficiently orchestrating all the steps in machine learning workflow. The transition between steps is completely automated, which leads to the rapid iteration of experiments and better readiness to move the entire pipeline to production.
- It provides us with the convenience to automatically retrain the model in production on the new data thereby making the system more robust and accurate with the predictions.
- It provides us with the symmetry between the development and the production environment, making the transition smooth from development to production for data teams.
- It allows us to create an ML pipeline capable of continuously delivering prediction services latest to the new models trained on the new data.
Tools of the Trade
As per the latest industry standards, some of the most frequently used MLOps tools today are as follows:
1. KubeFlow
KubeFlow is built on top of kubernetes and is dedicated to making deployments of machine learning workflows on Kubernetes simple, portable, and scalable. It provides a straightforward way to deploy best-of-breed open-source systems for ML to diverse infrastructures. Anywhere you are running Kubernetes, you should be able to run Kubeflow. Following are the services provided by KubeFlow:
- Notebooks: Kubeflow includes services to create and manage interactive notebooks in the Jupyter environment. It allows you to customize the notebook deployment and the computing resources to suit your organization’s data science needs. It allows you to experiment with your workflows locally, and then deploy them to a cloud when you’re ready.
- TensorFlow Model Training: Kubeflow provides us with a custom TensorFlow training job operator that can be used to train the ML model. In particular, Kubeflow’s job operator is capable of handling distributed TensorFlow training jobs with a configurable training controller to use CPUs or GPUs and to suit various cluster sizes.
- Model Serving: Kubeflow supports a TensorFlow Serving container to export trained TensorFlow models to Kubernetes. It is also integrated with Seldon Core, an open-source platform for deploying machine learning models on Kubernetes, and NVIDIA Triton Inference Server for maximized GPU utilization when deploying ML/DL models at scale.
- Pipelines: Kubeflow Pipelines is a comprehensive solution for deploying and managing end-to-end ML workflows. It can be used for rapid and reliable experimentation. It allows us to schedule and compare runs, and examine detailed reports on each run.
2. MLflow
MLflow is an open-source platform to manage the ML lifecycle, including experimentation, reproducibility, deployment, and a central model registry. Following are the services provided by MLflow:
- MLflow Tracking: The MLflow Tracking component is an API that provides a user interface for logging parameters, code versions, metrics, and output files when running the machine learning code and for later visualizing the results. MLflow Tracking also allows logging and querying experiments using Python, REST, R API, and Java API APIs.
- MLflow Projects: An MLflow Project is a format for packaging data science code in a reusable and reproducible way, based primarily on conventions. In addition, the Projects component includes an API and command-line tools for running projects, making it possible to chain together projects into workflows.
- MLflow Models: An MLflow Model is a standard format for packaging machine learning models that can be used in a variety of downstream tools — for example, real-time serving through a REST API or batch inference on Apache Spark.
- MLflow Registry: The MLflow Model Registry component is a centralized model store, set of APIs, and a user interface to collaboratively manage the full lifecycle of an MLflow Model. It provides model lineage, model versioning, stage transitions, and annotations.
3. Comet
Comet provides us with a self-hosted and cloud-based meta machine learning platform that allows data teams to track, compare, explain, and optimize experiments and models.
- Fast Integration: Just by adding a single line of code in your notebook or script will allow you to track experiments on the go. It works wherever you run your code, with any machine learning library, and for any machine learning task.
# import comet_ml in the top of your file
from comet_ml import Experiment
# Add the following code anywhere in your machine learning file
experiment = Experiment(project_name="my-project", workspace="my-workspace")
- Experiments Comparision: It provides us with the capability to easily compare experiments i.e code, hyperparameters, metrics, predictions, dependencies, system metrics, and more to understand differences in model performance and choose the best model.
- Model Debugging: It allows us to view, analyze, and gain insights from your model predictions. It can easily visualize samples with dedicated modules for vision, audio, text and tabular data to detect over-fitting and easily identify issues with your dataset.
- Meta ML: It assists data teams in building better models faster by using state-of-the-art hyperparameter optimizations techniques and supervised early stopping.
If you would like to learn more or want to me write more on this subject, feel free to reach out…
My social links: LinkedIn| Twitter | Github
If you liked this post or found it helpful, please take a minute to press the clap button, it increases the post visibility for other medium users.
MLOps Demystified… was originally published in Towards AI — Multidisciplinary Science Journal on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

