



Manipulating Time Series Data In Python
Last Updated on January 6, 2023 by Editorial Team
Last Updated on May 24, 2022 by Editorial Team
Author(s): Youssef Hosni
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
A practical guide for time series data manipulation in Python Pandas
Time series data is one of the most common data types in the industry and you will probably be working with it in your career. Therefore understanding how to work with it and how to apply analytical and forecasting techniques are critical for every aspiring data scientist. In this series of articles, I will go through the basic techniques to work with time-series data, starting from data manipulation, analysis, visualization to understand your data and prepare it for and then using statistical, machine, and deep learning techniques for forecasting and classification. It will be more of a practical guide in which I will be applying each discussed and explained concept on real data.
This series will consist of 8 articles:
- Manipulating Time Series Data In Python Pandas [A Practical Guide] (You are here!)
- Time Series Analysis in Python Pandas [A Practical Guide]
- Visualizing Time Series Data in Python [A practical Guide]
- Arima Models in Python [A practical Guide]
- Machine Learning for Time Series Data [A practical Guide]
- Deep Learning for Time Series Data [A practical Guide]
- Time Series Forecasting project using statistical analysis, machine learning & deep learning.
- Time Series Classification using statistical analysis, machine learning & deep learning.
Table of content:
- Working with Time Series in Pandas
- Basic Time Series Metrics & Resampling
- Window Functions: Rolling & Expanding Metrics
- Building a value-weighted index
All the codes and data used can be found in this respiratory.
1. Working with Time Series in Pandas
This section lays the foundations to leverage the powerful time-series functionality made available by how Pandas represents dates, in particular by the DateTimeIndex. You will learn how to create and manipulate date information and time series, and how to do calculations with time-aware DataFrames to shift your data in time or create period-specific returns.
1.1. How to use data and times with pandas
The basic building block of creating a time series data in python using Pandas time stamp (pd.Timestamp) which is shown in the example below:
The timestamp object has many attributes that can be used to retrieve specific time information of your data such as year, weekday. In the example below the year of the data is retrieved.
The second building block is the period object. The period object has a freq attribute to store the frequency information. The default is monthly freq and you can convert from freq to another as shown in the example below.
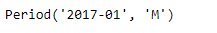
The output shows that the default freq is monthly freq. You can convert it into a daily freq using the code below.
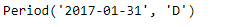
You can also convert period to timestamp and vice versa. This is shown in the example below.
You can do basic data arithmetic operations, for example starting with a period object for January 2017 at a monthly frequency, just add the number 2 to get a monthly period for March 2017. This is shown in the example below.
The output is shown in the image below:
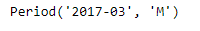
To create a time series you will need to create a sequence of dates. To create a sequence of Timestamps, use the pandas' function date_range. You need to specify a start date, and/or end date, or a number of periods. The default is daily frequency. The function returns the sequence of dates as a DateTimeindex with frequency information. You will recognize the first element as a pandas Timestamp.
This is shown in the example below and the output is shown in the figure below:

1.2. Indexing & resampling time series
The basic transformations include parsing dates provided as strings and converting the result into the matching Pandas data type called datetime64. They also include selecting subperiods of your time series, and setting or changing the frequency of the DateTimeIndex. You can change the frequency to a higher or lower value: upsampling involves increasing the time-frequency, which requires generating new data. Downsampling means decreasing the time frequency, which requires aggregating data.
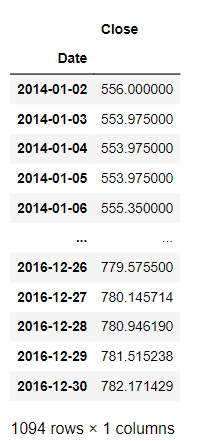
To understand more about the transformations we will apply this to the google stock prices data. First, if you check the type of the date column it is an object, so we would like to convert it into date type by the following code.
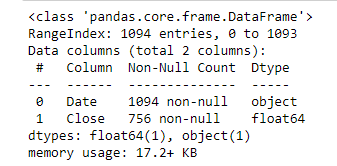
The date information is converted from a string (object) into a datetime64 and also we will set the Date column as an index for the data frame as it makes it easier after that to deal with the data from using the following code:
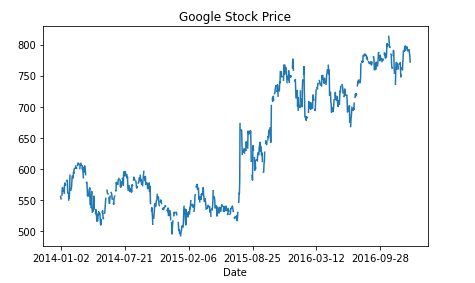
To have a better intuition on what the data looks like, let's plot the prices with time using the code below:
You can also partial indexing the data using the date index as the following example:
You may have noticed that our DateTimeIndex did not have frequency information. You can set the frequency information using dot-asfreq. The alias ‘D’ stands for calendar day frequency. As a result, the DateTimeIndex now contains many dates where the stock wasn’t bought or sold.
The example below shows converting DateTimeIndex of the google stock data into calendar day frequency:
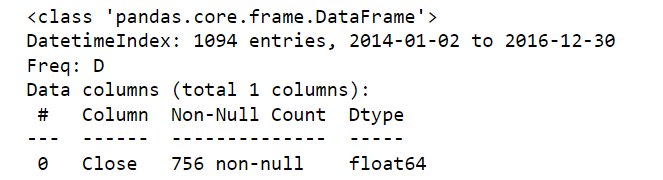
The number of instances has increased to 756 due to this daily sampling. The code below prints the first five rows of the daily resampled data:
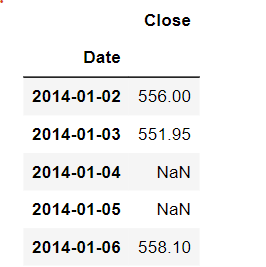
We can see that there are some NaN values that are missing new data due to this daily resampling.
We can also set the DateTimeIndex to business day frequency using the same method but changing ‘D’ into ‘B’ in the .asfreq() method. This is shown in the example below:
If we print the first five rows it will be as shown in the figure below:
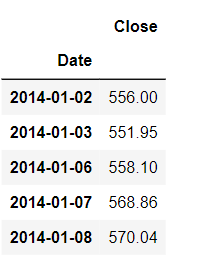
Now the data available is only the working day's data.
1.3. Lags, changes, and returns for stock price series
Shift or lag values back or forward back in time. shift(): Moving data between past & future. The default is one period into the future, but you can change it, by giving the periods variable the desired shift value.
An example of the shift method is shown below:
The output is shown in the figure below:
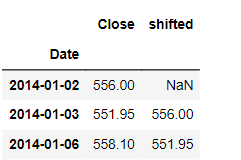
To move the data into the past you can use periods=-1 as shown in the figure below:
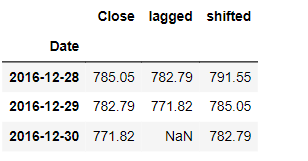
One of the important properties of the stock prices data and in general in the time series data is the percentage change. It’s formula is : ((X(t)/X(t-1))-1)*100.
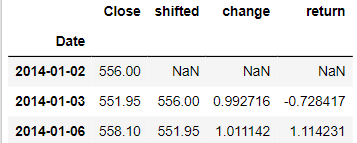
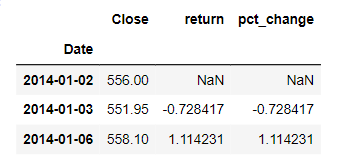
There are two ways to calculate it, we can use the built-in function df.pct_change() or using the functions df.div.sub().mul() and both will give the same results as shown in the example below:
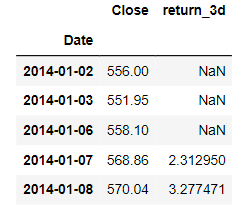
We can also get multiperiod returns using the periods variable in the df.pct_change() method as shown in the following example.
2. Basic Time Series Metrics & Resampling
In this section, we will dive deeper into the essential time-series functionality made available through the pandas DataTimeIndex. we will introduce resampling and how to compare different time series by normalizing their start points.
2.1. Resampling
We will start with resampling which is changing the frequency of the time series data. This is a very common operation because you often need to convert two-time series to a common frequency to analyze them together. When you upsample by converting the data to a higher frequency, you create new rows and need to tell pandas how to fill or interpolate the missing values in these rows. When you downsample, you reduce the number of rows and need to tell pandas how to aggregate existing data.
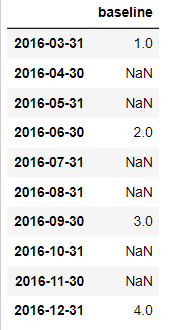
To illustrate what happens when you up-sample your data, let’s create a Series at a relatively low quarterly frequency for the year 2016 with the integer values 1–4. When you choose a quarterly frequency, pandas default to December for the end of the fourth quarter, which you could modify by using a different month with the quarter alias.
Next, let’s see what happens when you up-sample your time series by converting the frequency from quarterly to monthly using dot-asfreq(). Pandas add new month-end dates to the DateTimeIndex between the existing dates. As a result, there are now several months with missing data between March and December.
The output is shown below:
Let’s compare three ways that pandas offer to fill missing values when upsampling. The first two options involve choosing a fill method, either forward fill or backfill. The third option is to provide full value.
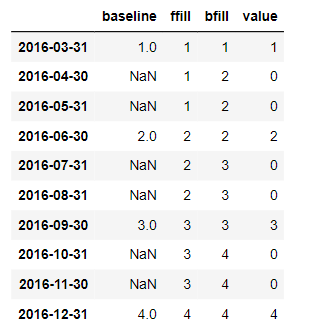
If you compare the results, you see that forward fill propagates any value into the future if the future contains missing values. Backfill does the same for the past, and fill_value just substitutes missing values.
If you want a monthly DateTimeIndex that covers the full year, you can use dot-reindex. Pandas align existing data with the new monthly values and produce missing values elsewhere. You can use the exact same fill options for dot-reindex as you just did for dot-asfreq.
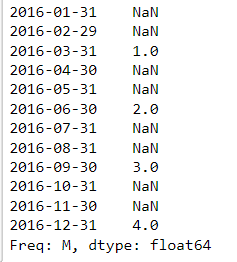
2.2. Upsampling & interpolation
The resample method follows a logic similar to dot-groupby: It groups data within a resampling period and applies a method to this group. It takes the value that results from this method and assigns a new date within the resampling period. The new date is determined by a so-called offset, and for instance, can be at the beginning or end of the period or a custom location. You will use resample to apply methods that either fill or interpolate missing dates when up-sampling, or that aggregate when down-sampling.
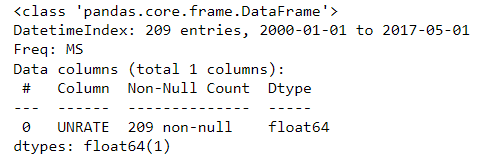
We will apply the resample method to the monthly unemployment rate. First, we will upload it and spare it using the DATE column and make it an index.
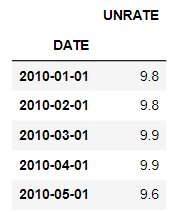
The 85 data points imported using read_csv since 2010 have no frequency information. An inspection of the first rows shows that the data are reported for the first of each calendar month. So let's resample it by the starting of each calendar month using both dot-resample and dot-asfreq methods.

Both of the methods are the same. When looking at resampling by month, we have so far focused on month-end frequency. In other words, after resampling, new data will be assigned the last calendar day for each month. There are, however, quite a few alternatives as shown in the table below:

Depending on your context, you can resample to the beginning or end of either the calendar or business month.
Resampling implements the following logic: When up-sampling, there will be more resampling periods than data points. Each resampling period will have a given date offset, for instance, month-end frequency. You then need to decide how to create data for the new resampling periods. The new data points will be assigned to the date offsets. In contrast, when down-sampling, there are more data points than resampling periods. Hence, you need to decide how to aggregate your data to obtain a single value for each date offset.
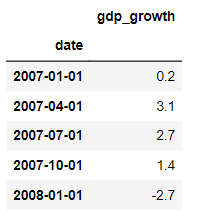
Let’s now use a quarterly series, real GDP growth. You see that there is again no frequency info, but the first few rows confirm that the data are reported for the first day of each quarter.
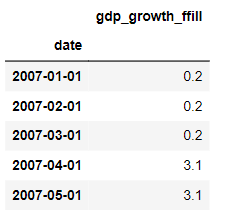
We can use dot-resample to convert this series to month start frequency, and then forward fill logic to fill the gaps. We’re using dot-add_suffix to distinguish the column label from the variation that we’ll produce next.
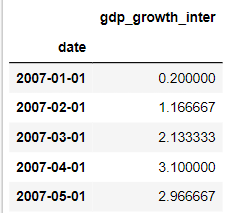
Resample also lets you interpolate the missing values, that is, fill in the values that lie on a straight line between existing quarterly growth rates. A look at the first few rows shows how to interpolate the average's existing values.
We’ll now combine the two series using the pandas dot-concat function to concatenate the two data frames. Using axis=1 makes pandas concatenate the DataFrames horizontally, aligning the row index. A plot of the data for the last two years visualizes how the new data points lie on the line between the existing points, whereas forward filling creates a step-like pattern.
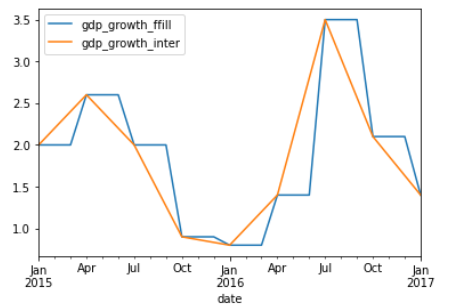
After resampling GDP growth, you can plot the unemployment and GDP series based on their common frequency.
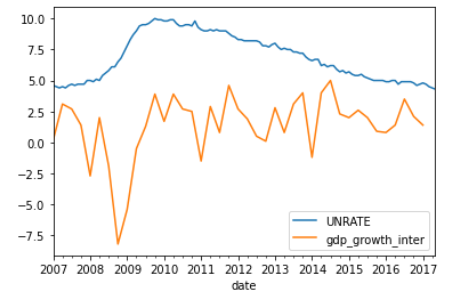
2.3. Downsampling & aggregation
So far, we have focused on up-sampling, that is, increasing the frequency of a time series, and how to fill or interpolate any missing values. Downsampling is the opposite, is how to reduce the frequency of the time series data. This includes, for instance, converting hourly data to daily data, or daily data to monthly data. In this case, you need to decide how to summarize the existing data as 24 hours becomes a single day. Your options are familiar aggregation metrics like the mean or median, or simply the last value and your choice will depend on the context.
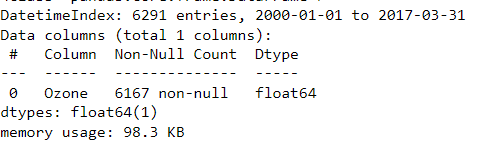
Let’s first use read_csv to import air quality data from the Environmental Protection Agency. It contains the average daily ozone concentration for New York City starting in 2000. Since the imported DateTimeIndex has no frequency, let’s first assign calendar day frequency using dot-resample. The resulting DateTimeIndex has additional entries, as well as the expected frequency information.
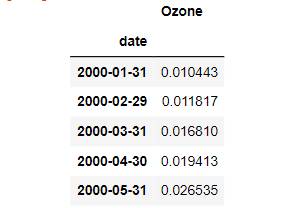
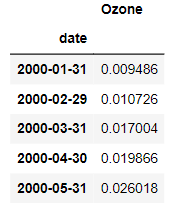
To convert daily ozone data to monthly frequency, just apply the resample method with the new sampling period and offset. We are choosing monthly frequency with default month-end offset. Next, apply the mean method to aggregate the daily data to a single monthly value. You can see that the monthly average has been assigned to the last day of the calendar month.
You can apply the median in the exact same fashion.
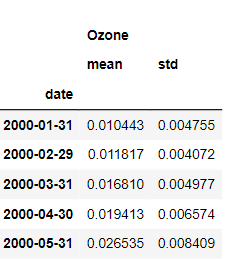
Similar to the groupby method, you can also apply multiple aggregations at once.
Let’s visualize the resampled, aggregated Series relative to the original data at calendar-daily frequency. We’ll plot the data starting from 2016 so you can see more detail. Matplotlib allows you to plot several times on the same object by referencing the axes object that contains the plot.
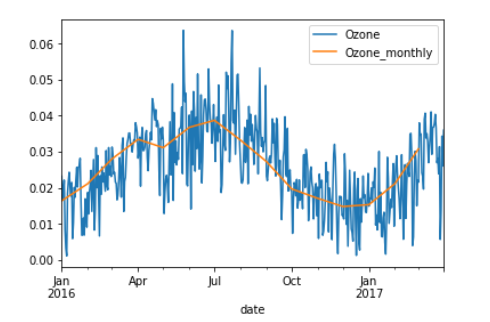
The first plot is the original series, and the second plot contains the resampled series with a suffix so that the legend reflects the difference. You see that the resampled data are much smoother since the monthly volatility has been averaged out. Let’s also take a look at how to resample several series.
3. Window Functions: Rolling & Expanding Metrics
In this section, we will show you how to use the window function to calculate time series metrics for both rolling and expanding windows.
3.1. Window functions with pandas
Window functions are useful because they allow you to operate on sub-periods of your time series. In particular, window functions calculate metrics for the data inside the window. Then, the result of this calculation forms a new time series, where each data point represents a summary of several data points of the original time series. We will discuss two main types of windows: Rolling windows maintain the same size while they slide over the time series, so each new data point is the result of a given number of observations. Expanding windows grow with the time series so that the calculation that produces a new data point is the result of all previous data points.
Let’s calculate a simple moving average to see how this works in practice. We will again use google stock price data for the last several years. We will see two ways to define the rolling window:
First, we apply rolling with an integer window size of 30. This means that the window will contain the previous 30 observations or trading days. When you choose an integer-based window size, pandas will only calculate the mean if the window has no missing values. You can change this default by setting the min_periods parameter to a value smaller than the window size of 30.
You can also create windows based on a date offset. If you choose 30D, for instance, the window will contain the days when stocks were traded during the last 30 calendar days. While the window is fixed in terms of period length, the number of observations will vary. Let’s take a look at what the rolling mean looks like.
You can also calculate a 90 calendar day rolling mean, and join it to the stock price. The join method allows you to concatenate a Series or DataFrame along axis 1, that is, horizontally. It’s just a different way of using the dot-concat function you’ve seen before. You can see how the new time series is much smoother because every data point is now the average of the preceding 90 calendar days.
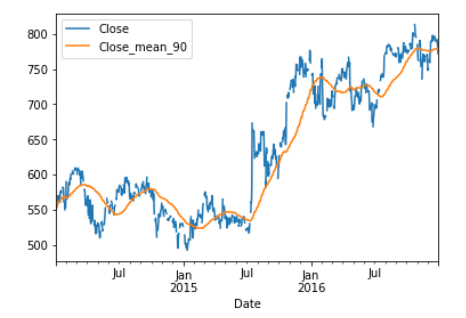
To see how extending the time horizon affects the moving average, let’s add the 360 calendar day moving average.
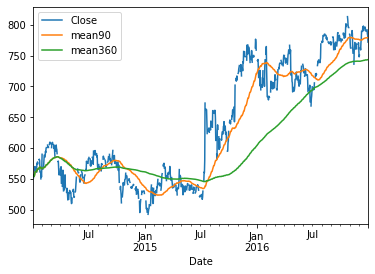
The series now appears smoother still, and you can more clearly see when short-term trends deviate from longer-term trends, for instance when the 90-day average dips below the 360-day average in 2015.
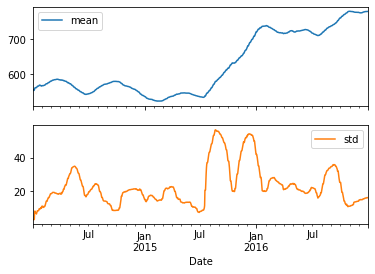
Similar to dot-groupby, you can also calculate multiple metrics at the same time, using the dot-agg method. With a 90-day moving average and standard deviation, you can easily discern periods of heightened volatility.
Finally, let’s display a 360 calendar day rolling median, or 50 percent quantile, alongside the 10 and 90 percent quantiles. Again you can see how the ranges for the stock price have evolved over time, with some periods more volatile than others.
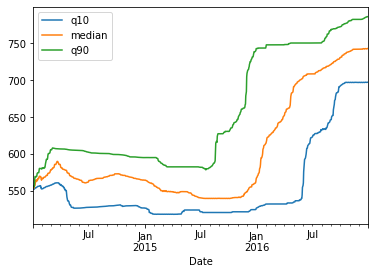
3.2. Expanding window functions with pandas
We will move from rolling to expanding windows. You will now calculate metrics for groups that get larger to exclude all data up to the current date. Each data point of the resulting time series reflects all historical values up to that point. Expanding windows are useful to calculate for instance a cumulative rate of return, or a running maximum or minimum. In pandas, you can use either the method expanding, which works just like rolling, or in a few cases shorthand methods for the cumulative sum, product, min, and max.
We will use the S&P500 data for the last ten years in the practical examples in this section. Let’s first take a look at how to calculate returns: The simple period return is just the current price divided by the last price minus 1. The return over several periods is the product of all period returns after adding 1 and then subtracting 1 from the product.
So for more clarification, the period return is: r(t) = (p(t)/p(t-1)) -1 and the multi-period return is: R(T) = (1+r(1))(1+r(2))……..(1+r(T)) — 1.
Pandas makes these calculations easy ‘ you have already seen the methods for percent change(.pct_change) and basic math (.diff(), .div(), .mul()), and now you’ll learn about the cumulative product.
To get the cumulative or running rate of return on the SP500, just follow the steps described above: Calculate the period return with percent change, and add 1 Calculate the cumulative product, and subtract one. You can multiply the result by 100, and plot the result in percentage terms. The code for this is shown below:
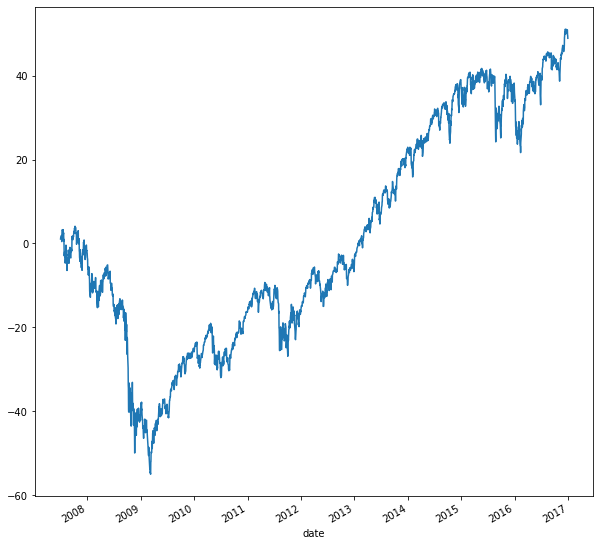
From the plot, we can see that the SP500 is up 60% since 2007, despite being down 60% in 2009. You can also easily calculate the running min and max of a time series: Just apply the expanding method and the respective aggregation method.
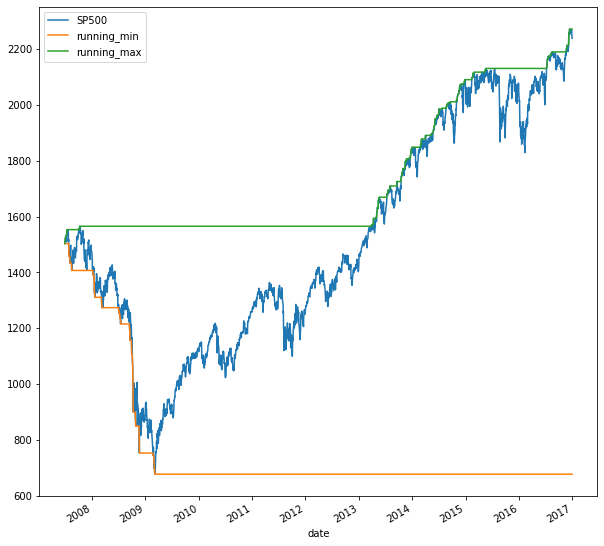
The orange and green lines outline the min and max up to the current date for each day. You can also combine the concept of a rolling window with a cumulative calculation. Let’s calculate the rolling annual rate of return, that is, the cumulative return for all 360 calendar day periods over the ten-year period covered by the data. This cumulative calculation is not available as a built-in method. But no problem just define your own multiperiod function, and use apply it to run it on the data in the rolling window. The data in the rolling window is available to your multi_period_return function as a numpy array. Add 1 to increment all returns, apply the numpy product function, and subtract one to implement the formula from above. Just pass this function to apply after creating a 360 calendar day window for the daily returns. Multiply the rolling 1-year return by 100 to show them in percentage terms, and plot alongside the index using subplots equals True.
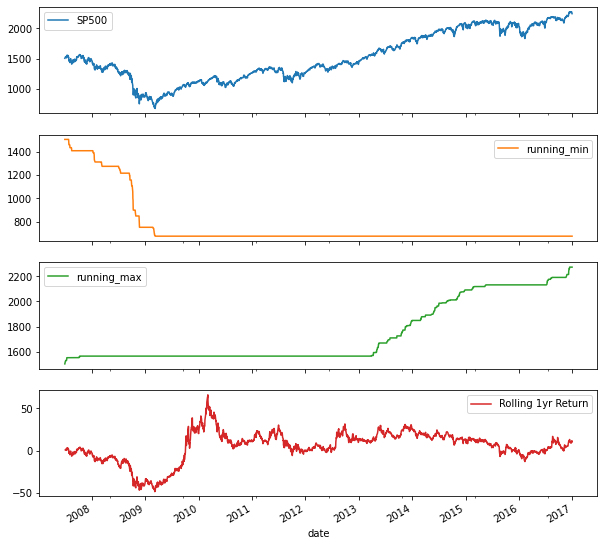
The result shows the large annual return swings following the 2008 crisis.
3.4. Random walk and simulations
Daily stock returns are notoriously hard to predict, and models often assume they follow a random walk. We will use NumPy to generate random numbers, in a time series context. You’ll also use the cumulative product again to create a series of prices from a series of returns.
In the first example, we will generate random numbers from the bell-shaped normal distribution. This means that values around the average are more likely than extremes, as tends to be the case with stock returns. In the second example, you will randomly select actual S&P 500 returns to then simulate S&P 500 prices.
To generate random numbers, first import the normal distribution and the seed functions from numpy’s module random. Also, import the norm package from scipy to compare the normal distribution alongside your random samples. Generate 1000 random returns from numpy’s normal function, and divide by 100 to scale the values appropriately. Let’s plot the distribution of the 1,000 random returns, and fit a normal distribution to your sample. You can see that the sample closely matches the shape of the normal distribution.
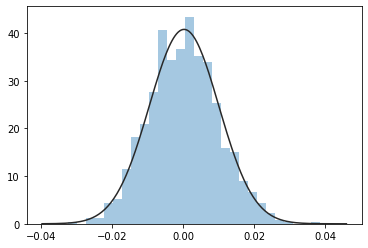
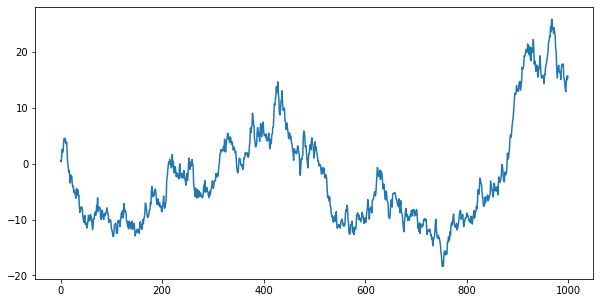
To create a random price path from your random returns, we will follow the procedure from the subsection, after converting the numpy array to a pandas Series. Add 1 to the period returns, calculate the cumulative product, and subtract 1. Plot the cumulative returns, multiplied by 100, and you see the resulting prices.
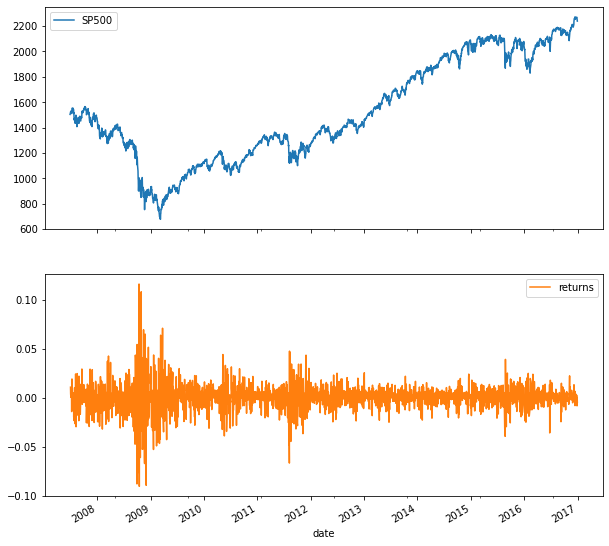
Let’s now simulate the SP500 using a random expanding walk. Import the last 10 years of the index, drop missing values and add the daily returns as a new column to the DataFrame. A plot of the index and return series shows the typical daily return range between +/2–3 percent, as well as a few outliers during the 2008 crisis.
A comparison of the S&P 500 return distribution to the normal distribution shows that the shapes don’t match very well. This is a typical finding ‘ daily stock returns tend to have outliers more often than the normal distribution would suggest.
Now let’s randomly select from the actual S&P 500 returns. You’ll be using the choice function from Numpy’s random module. It returns a NumPy array with a random sample from a list of numbers ‘ in our case, the S&P 500 returns. Just provide the return sample and the number of observations you want to the choice function. Next, convert the NumPy array to a pandas series, and set the index to the dates of the S&P 500 returns. Your random walk will start at the first S&P 500 price.
Use the ‘first’ method with calendar day offset to select the first S&P 500 price. Then add 1 to the random returns, and append the return series to the start value. Now you are ready to calculate the cumulative return given the actual S&P 500 start value. Add 1, calculate the cumulative product, and subtract one. The result is a random walk for the SP500 based on random samples from actual returns.
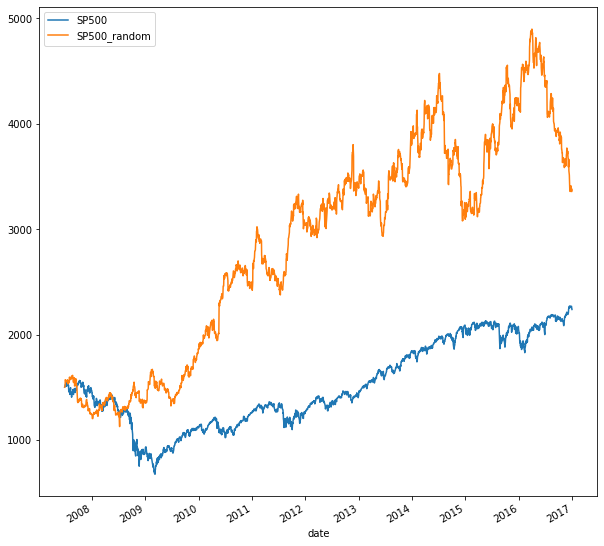
3.4. Correlation between time series
Correlation is the key measure of linear relationships between two variables. In financial markets, correlations between asset returns are important for predictive models and risk management, for instance. Pandas and seaborn have various tools to help you compute and visualize these relationships.
The correlation coefficient looks at pairwise relations between variables and measures the similarity of the pairwise movements of two variables around their respective means. This pairwise co-movement is called covariance. The correlation coefficient divides this measure by the product of the standard deviations for each variable. As a result, the coefficient varies between -1 and +1. The closer the correlation coefficient to plus or 1 or minus 1, the more does a plot of the pairs of the two series resembles a straight line. The sign of the coefficient implies a positive or negative relationship. A positive relationship means that when one variable is above its mean, the other is likely also above its mean, and vice versa for a negative relationship. There are, however, numerous types of non-linear relationships that the correlation coefficient does not capture.
we will use this price series for five assets to analyze their relationships in this section. You now have 10 years' worth of data for two stock indices, a bond index, oil, and gold.
Seaborn has a joint plot that makes it very easy to display the distribution of each variable together with the scatter plot that shows the joint distribution. We’ll use the daily returns for our analysis. The joint plot takes a DataFrame, and then two column labels for each axis. The S&P 500 and the bond index for example have low correlation given the more diffuse point cloud and negative correlation as suggested by the slight downward trend of the data points.
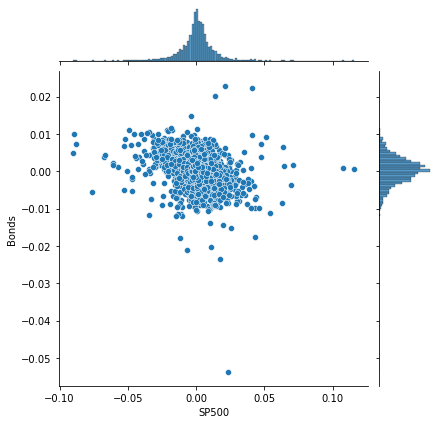
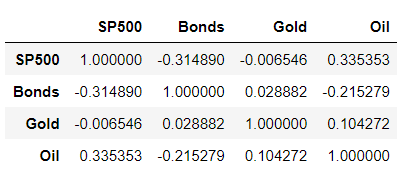
Pandas allow you to calculate all pairwise correlation coefficients with a single method called dot-corr. Apply it to the returns DataFrame, and you get a new DataFrame with the pairwise coefficients. The data are naturally symmetric around the diagonal, which contains only values of 1 because the correlation of a variable with itself is of course 1.
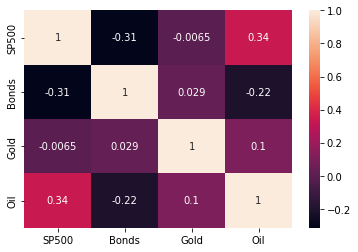
Seaborn again offers a neat tool to visualize pairwise correlation coefficients. The heatmap takes the DataFrame with the correlation coefficients as inputs and visualizes each value on a color scale that reflects the range of relevant values. The parameter annot equals True ensures that the values of the correlation coefficients are displayed as well. You can see that the correlations of daily returns among the various asset classes vary quite a bit.
4. Putting it all together: Building a value-weighted index
This chapter combines the previous concepts by teaching you how to create a value-weighted index. This index uses market-cap data contained in the stock exchange listings to calculate weights and 2016 stock price information. Index performance is then compared against benchmarks to evaluate the performance of the index you created.
To build a value-based index, you will take several steps: You will select the largest company from each sector using actual stock exchange data as index components. Then, you’ll calculate the number of shares for each company, and select the matching stock price series from a file. Next, you’ll compute the weights for each company, and based on these the index for each period. You will also evaluate and compare the index performance.
4.1 Select index components & import data
First, let’s import company data using pandas’ read_excel function. You will import this worksheet with listing info from a particular exchange while making sure missing values are properly recognized.
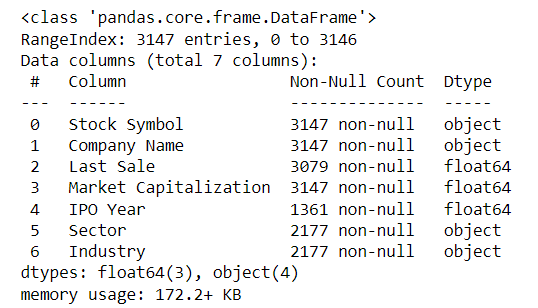
Next, move the stock ticker into the index. Since you’ll select the largest company from each sector, remove companies without sector information. You can use the ‘subset’ keyword to identify one or several columns to filter out missing values. You have already seen the keyword ‘inplace’ to avoid creating a copy of the DataFrame. Finally, divide the market capitalization by 1 million to express the values in million USD. The results are 2177 companies from the NYSE stock exchange.
To pick the largest company in each sector, group these companies by sector, select the column market capitalization, and apply the method nlargest with parameter 1. The result is a Series with the market cap in millions with a MultiIndex.
The first index level contains the sector, and the second is the stock ticker. To select the tickers from the second index level, select the series index, and apply the method ‘get_level_values’ with the name of the index ‘Stock Symbol’. You can also use the value 1 to select the second index level. Print the tickers, and you see that the result is a single DataFrame index. Use the method dot-tolist to obtain the result as a list.
Finally, use the ticker list to select your stocks from a broader set of recent price time series imported using read_csv.
4.2 Build a market-cap weighted index
To construct the market-cap weighted index, you need to calculate the number of shares using both market capitalization and the latest stock price, because the market capitalization is just the product of the number of shares and the price of each share. Next, you’ll use the historical stock prices to convert them into a series of market values. Then convert it to an index by normalizing the series to start at 100. You’ll also take a look at the index return and the contribution of each component to the result.
To calculate the number of shares, just divide the market capitalization by the last price. Since we are measuring market cap in million USD, you obtain the shares in millions as well. You can now multiply your historical stock price series by the number of shares.
The result is a time series of the market capitalization, ie, the stock market value of each company. By selecting the first and the last day from this series, you can compare how each company’s market value has evolved over the year.
Now you almost have your index: just get the market value for all companies per period using the sum method with the parameter axis equals 1 to sum each row.
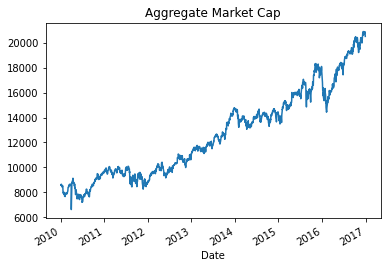
Now you just need to normalize this series to start at 1 by dividing the series by its first value, which you get using dot-iloc. Multiply the result by 100 and you get the convenient start value of 100 where differences from the start values are changes in percentage terms.
4.3. Evaluate index performance
Now that you have built a weighted index, you can analyze its performance. Important elements of your analysis will be: First, take a look at the index return, and the contribution of each component to the result. Next, compare the performance of your index to a benchmark like the S&P 500, which covers the wider market, and is also value-weighted. You can compare the overall performance or rolling returns for sub-periods.
First, let’s look at the contribution of each stock to the total value-added over the year. Subtract the last value of the aggregate market cap from the first to see that the companies in the index added 315 billion dollars in market cap. To see how much each company contributed to the total change, apply the diff method to the last and first value of the series of market capitalization per company and period. The last row now contains the total change in market cap since the first day. You can select the last row using dot-loc and the date pertaining to the last row, or iloc with the parameter -1.
To compute the contribution of each component to the index return, let’s first calculate the component weights. Select the market capitalization for the index components. Calculate the component weights by dividing their market cap by the sum of the market cap of all components. As you can see, the weights vary between 2 and 13%. Now calculate the total index return by dividing the last index value by the first value, subtracting 1, and multiplying by 100.
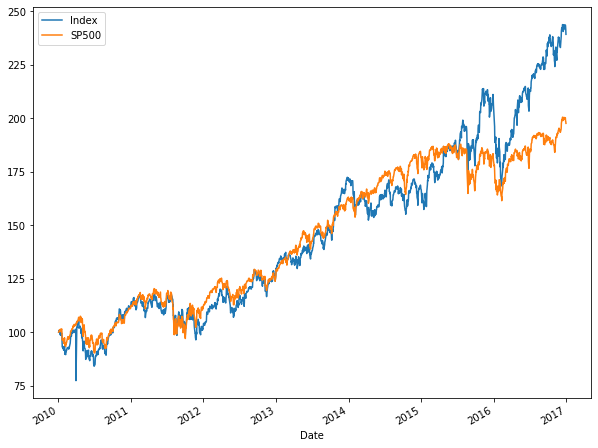
Let’s now move on and compare the composite index performance to the S&P 500 for the same period. Convert the index series to a DataFrame so you can insert a new column. Import the data from the Federal Reserve as before. Then normalize the S&P 500 to start at 100 just like your index, and insert as a new column, then plot both time series. You can see that your index did a couple of percentage points better for the period.
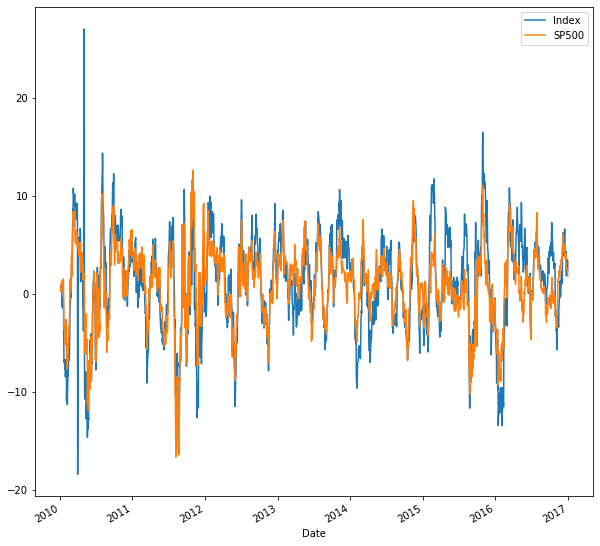
Lastly, to compare the performance over various subperiods, create a multi-period-return function that compounds a NumPy array of period returns to a multi-period return as you did in chapter 3. Create the daily returns of your index and the S&P 500, a 30 calendar day rolling window, and apply your new function. The plot shows all 30-day returns for either series and illustrates when it was better to be invested in your index or the S&P 500 for a 30 day period.
Thanks for reading! If you like the article make sure to clap (up to 50!) and connect me on LinkedIn and follow me on Medium to stay updated with my new articles.
Manipulating Time Series Data In Python was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts
")



")


