



Making Video Conferencing more Accessible with Machine Learning
Last Updated on January 6, 2023 by Editorial Team
Author(s): Jay Gupta
Computer Vision, Machine Learning
Learn to build an Azure-powered pipeline for the visually impaired or with other disorders
The COVID-19 pandemic has pushed organizations to the edge, with most employers resorting to Work-from-Home (WFH) arrangements. Apart from work, with severe global travel restrictions, people are slowly adapting to video-conferencing modes to keep in touch with their friends and family. This pandemic has nurtured the rise of platforms like Microsoft Teams and Zoom, which have seen colossal growth patterns, within the last six months [1].
In this article, we will learn to build a Microsoft Azure-powered pipeline, to detect sentiments, and facial expressions of participants in a Microsoft Teams (Teams) call, in real-time. We’ll also include a feature which will help the participants to align their cameras properly before the start of the call.
Disclaimer — This project was originally built for Microsoft AI for Accessibility Hackathon, and was carried to qualify as one of the top five submissions from Singapore, and pitched to a stream of Microsoft & partner judges as a top submission in the Asia Pacific region. I would like to give the due credits to my fellow teammates Aditya, Ritwik & Vidurveer, without whom, this excerpt would not have been possible.
Background
While video conferencing has its perks, it critically lacks accessibility for those with visual impairment and visual disorders in various aspects.
For countless disorders, not limited to social-emotional agnosia, autism, dyslexia and anxiety disorders, it presents a challenge for such individuals to comprehend other’s emotions and facial expressions, and respond properly over a video conference. With such a setting, they are not comfortable with video calls and it takes a real dive when it comes to virtual job interviews, where it is critical for them to interpret the interviewer’s facial expressions [2].
The second issue is that with these disabilities, it is hard for individuals to keep themselves aware of the fact that if they are even visible to the other person and if their camera is aligned properly.
Pipeline
There are three steps in building our pipeline, firstly, we capture frames (screenshots) from the video conference after a set interval, say after every two seconds. Afterwards, we send these frames to Microsoft Azure APIs to get the sentiment (emotion) of the individual on the call, and then, finally render the detected sentiment on the screen.
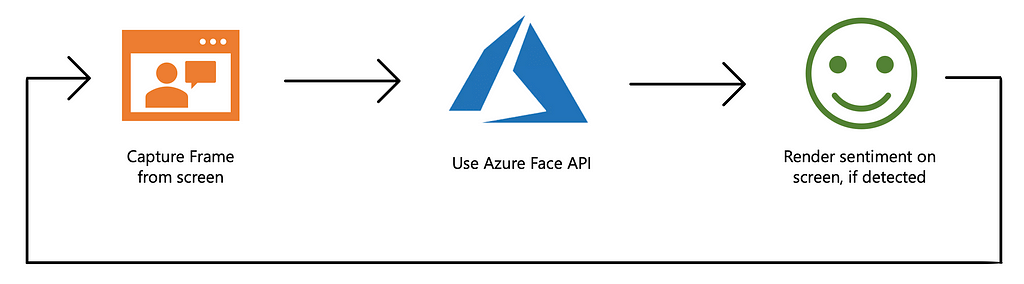
Capturing Frames
The first step in the process is to capture frames from the on-going video call, after a set duration. We are directly taking a screenshot of the computer screen because currently, there is no option to get the video feed directly from a Teams call.
The process of taking a screenshot is simple with the help of Python’s cross-platform ‘pyautogui’ library. After the screenshot is taken, it is stored as ‘screen.png’ in our local directory.
Using Azure Face API
Secondly, after a frame is captured, we call the Azure Face API to detect the sentiment of the person in the frame. For simplicity, I’m going to assume that there is only one person in the video call.
The Face API is a part of cognitive services, offered by Azure that has a feature called ‘Perceived emotion recognition’ that can detect perceived facial expressions such as anger, happiness, and surprise. Face API is available for free of charge, with a cap of 20 API calls per minute, which should be sufficient for our use-case.
The code mentioned below is a sample JSON response from the Azure Face API. We note the myriad of emotions given by the API as well as their confidence intervals. For example, we can see in the below JSON response, for a given sample image, the ‘happiness’ emotion is highest with 60% confidence. The API gives much more data such as location and existence of facial features like hair colour, smile, and head pose, but I’ve chosen to omit those here.
[
{
"faceId":"92e6d028-188a-40bc-9696-6ccc54831ead",
"faceRectangle":{
"top":636,
"left":1249,
"width":403,
"height":403
},
"faceAttributes":{
"emotion":{
"anger":0.0,
"contempt":0.087,
"disgust":0.0,
"fear":0.0,
"happiness":0.606,
"neutral":0.307,
"sadness":0.0,
"surprise":0.0
}
}
}
]
The process of calling the API is quite straightforward in Python. Firstly, we configure the API end-point which is universal and the API subscription key which is unique. The service is free in Azure, and the key can be easily obtained by following three quick steps under the ‘Prerequisites’ tab in the Azure documentation.
After configuration, we simply read the frame taken in step one, configure the parameters for the API to obtain only the required information and call the API. Afterwards, if the response is empty, there is no face detected, otherwise, we return the most confident emotion from the JSON response.
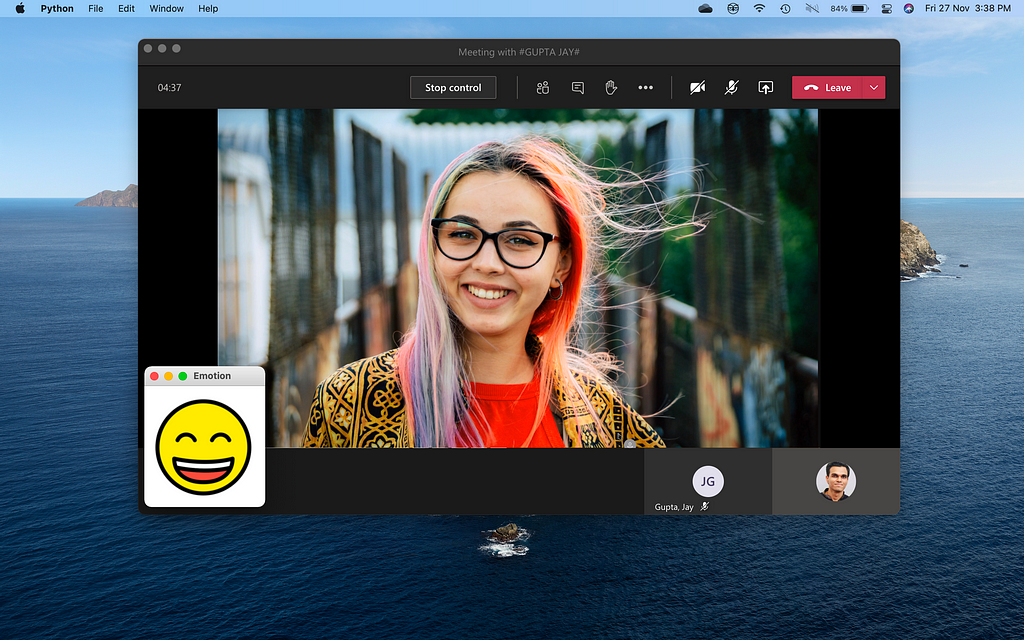
Rendering sentiment on screen
Finally, after detecting the emotion of the individual on the Teams call, we display it on the screen. For this process, I am using the Tkinter Python library, but feel free to use a library of your own preference.

Firstly, I’ve created a local directory, which contains the emoji images for different emotions, shown above. The method simply gets the emoji name as a parameter and displays it on the screen in the correct position.
Driver Code
The final piece is the driver code, through which, we combine all the methods written above to run our program. You can change the ‘MODE’ variable to switch between detecting emotions during a video conference, and detecting the proper alignment of the face before the start of the call.
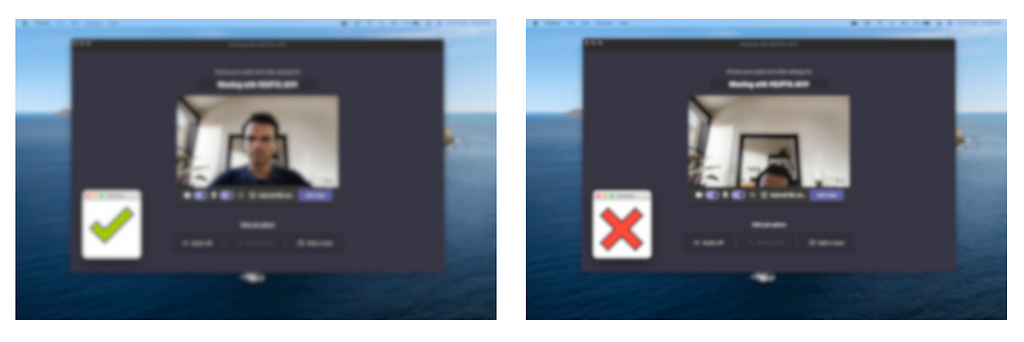
Wrap Up
The Azure pipeline we have created is a prototype, that can be potentially integrated into video conferencing platforms as an accessibility feature for visually disabled and impaired people.
There are various shortcomings of our approach, most prominently the lacking integration of this program with the Microsoft Teams platform itself. At the time of writing this piece, it is not possible to build an end-to-end integrated solution within Teams or Zoom, because of its developer limitations. However, as we know it, these applications are rapidly evolving, and a tight integration might be possible in the near future. Secondly, it is assumed that there is one person in the video conference, which often, might not be the case.
Feel free to play around and make the code better. If you think there are other ways to improve, please leave a comment.
References
[1] Spataro, J. (2020, October 30). Microsoft Teams reaches 115 million DAU-plus, a new daily collaboration minutes metric for Microsoft 365, Microsoft.
[2] Zhao, Y., Wu, S., Reynolds, L., & Azenkot, S. (2018). A Face Recognition Application for People with Visual Impairments. Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems — CHI ’18. doi:10.1145/3173574.3173789
Making Video Conferencing more Accessible with Machine Learning was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Related posts


Popular posts

 for 2021")



Updates

Recent Posts



