


Machine Learning Models Explainability — Definitions, Importance, Techniques, And Tools
Last Updated on July 17, 2023 by Editorial Team
Author(s): Kumar kaushal
Originally published on Towards AI.
Techniques (LIME, SHAP, PDP, ICE, DeepLIFT, others), libraries, and other details of Model Explainability
We may have come across comments regarding a model being a “black box” and stakeholders lacking understanding of what “goes inside” it. Many business leaders need to understand models’ explanations in terms of how and which input features are affecting the model’s output. These requirements can be fulfilled by Explainability in Machine Learning.
Meaning of Explainability
Explainability, as a set of processes and systems, helps users and other stakeholders of the Machine Learning models to understand the model and its results. Though Model Interpretability is different from Model Explainability, still these two terms have been used interchangeably.
Importance of Explainability in Machine Learning
It entrusts confidence in the model’s output(s) and identifies and understands biases. Using Model Explainability, one can not only understand the role of input features in impacting the output but also comprehend a specific decision made by the model. It makes Machine Learning a responsible and transparent application that is understood by data scientists, businesses, users, and society at large; assisting regulators, corporate governance, and others.
The above are just a few instances that highlight the importance of Model Explainability, and the list is ever-growing.
Methods of Model Explainability
Before we jump to various popular methods of Model Explainability, it is important to mention its types- local, cohort, and global explainability.
Local explainability emphasizes a specific decision made by the model and input features impacting that decision. It answers questions raised by users, auditors, and business leaders for a specific output of the model.
Cohort explainability is applicable to a certain cohort or sub-set of data. It helps in understanding the model and its features’ role in prediction output for a certain set of data, thus providing insights due to bias and performance.
Global explainability takes a holistic view of model explanation, assisting the user in understanding the role and impact of input features on the output, considering the whole population. It helps to understand the overall performance of the model.
Let us discuss the various methods of model explainability.
- Partial Dependency plot (PDP)
PDP shows the dependence between a set of input features and the target variable, with other input features held constant. There can be one-way or two-way dependencies plots.

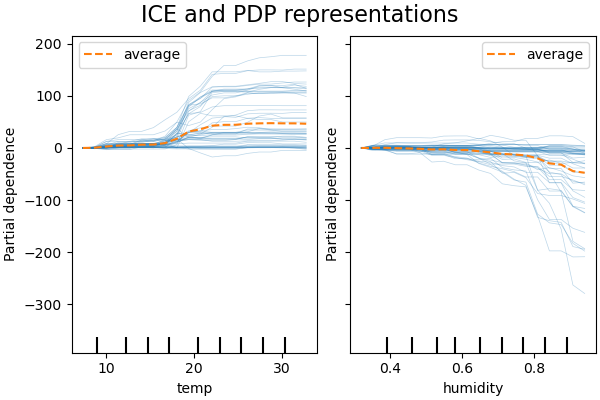
One-way PDPs show the dependency of target response on one input feature. In the above figure, we can observe the interaction of target response with one input — temperature and humidity each. The leftmost plot indicates that higher temperature is related to a higher value of target response. Two-way PDP plots, as shown in the rightmost plot, show the dependency of the target response on joint values of two input features- temperature and humidity.
- Individual Condition Expectations (ICE) plot
Just like PDP, ICE shows the dependency of the target response on the input features. However, in contrast to PDP, which shows the average effect of input features on the target response, an ICE plot shows the effect of prediction on an input feature for each sample separately. Each sample is represented as one line in the ICE plot.
- Permutation Feature Importance
This is another model inspection technique where data is in tabular form. Permutation Feature Importance is defined as the decrease in the model prediction score as we randomly shuffle the input feature. If a feature is important, then shuffling its value will increase the model error. If a feature is not important, then shuffling will not change the prediction error.

- Leave One Feature Out (LOFO)
It is a simple approach to model inspection where one feature or column is left out, the model is retrained, and the new model’s output is compared with the original model’s output. If there is a significant difference in the output, then the left-out feature must be important.
- Local Interpretable Model — Agnostic Explanations — LIME
LIME was introduced in 2016 in the paper “Why Should I Trust You?” Explaining the Predictions of Any Classifier. As the name suggests, LIME is a model-agnostic approach with local fidelity. Local means local fidelity, i.e., it is desired that the explanation reflects the classifier behavior in the neighborhood of the instance being predicted. In other words, it means the explanation must correspond to how the model behaves in the vicinity of the instance being predicted. Interpretable means that the explanation must be interpretable in terms of providing qualitative understanding between input features and the response variable. The characteristic of model agnostic means that the approach can be applied to any model for the explanation. LIME can be applied to tabular, text, and image datasets.

- Shapley Additive Explanations — SHAP
SHAP tries to explain the output of a Machine Learning model through the Game Theory approach. The shapely value of the input feature’s importance is the average marginal contribution of overall feature combinations. An introduction to shap is shown in the below code snippet:

- Deep Learning Important FeaTures (DeepLIFT)
Deep Learning Important FeaTures (DeepLIFT)- is a method to explain neural networks where the output of the model is decomposed on a specific input by backpropagating the contributions of all neurons in the network to every feature of the input.
Additionally, there are other methods of Deep Neural Network model explanation such as Layerwise Relevance Propagation (LRP), and Deep Visual Explanation (DVE). The below image shows the various list of explainers for Deep Neural Network models:


Python Libraries for Model Explainability
Here’s a list of a few libraries available for Explainable AI tasks:
- OmniXAI: https://opensource.salesforce.com/OmniXAI/latest/index.html#
- InterpretML: https://interpret.ml/
- AI Explainability 360: https://aix360.mybluemix.net/
- Eli5: Link
- Captum: https://captum.ai/
- Alibi: https://pypi.org/project/alibi/0.3.2/
- SHAP: https://shap.readthedocs.io/en/latest/index.html
References
https://scikit-learn.org/stable/modules/partial_dependence.html
https://arxiv.org/pdf/1602.04938.pdf
Learning Important Features Through Propagating Activation Differences
The purported "black box" nature of neural networks is a barrier to adoption in applications where interpretability is…
arxiv.org
Welcome to the SHAP documentation – SHAP latest documentation
SHAP (SHapley Additive exPlanations) is a game theoretic approach to explain the output of any machine learning model…
shap.readthedocs.io
Machine Learning algorithms range from simple linear regression to complex Deep Learning ones.
Explainability and Auditability in ML: Definitions, Techniques, and Tools – neptune.ai
Imagine that you have to present your newly built facial recognition feature to the technical heads of a SaaS product…
neptune.ai
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Related posts


Popular posts

 for 2021")



Updates

Recent Posts



