



LLaMA-GPT4All: Simplified Local ChatGPT
Last Updated on April 11, 2023 by Editorial Team
Author(s): Luhui Hu
Originally published on Towards AI.
Meta LLaMA-based GPT4All for your local ChatGPT clone solution
ChatGPT has taken the world by storm. It sets new records for the fastest-growing user base in history, amassing 1 million users in 5 days and 100 million MAU in just two months.
Generative Pre-trained Transformer, or GPT, is the underlying technology of ChatGPT. The most recent version, GPT-4, is said to possess more than 1 trillion parameters. It has reportedly been trained on a cluster of 128 A100 GPUs for a duration of three months and four days.
Undoubtedly, many developers or users want to run their own ChatGPT locally. GPT4All has emerged as the popular solution. It quickly gained traction in the community, securing 15k GitHub stars in 4 days — a milestone that typically takes about four years for well-known open-source projects (e.g., Apache Spark and Kafka).
Here will touch on GPT4All and try it out step by step on a local CPU laptop.
Introduce GPT4All
GPT4All is a large language model (LLM) chatbot developed by Nomic AI, the world’s first information cartography company. It was fine-tuned from LLaMA 7B model, the leaked large language model from Meta (aka Facebook). GPT4All is trained on a massive dataset of text and code, and it can generate text, translate languages, write different kinds of creative content, and answer your questions in an informative way.
GPT4All is available to the public on GitHub. LLaMA is available for commercial use under the GPL-3.0 license — while the LLaMA code is available for commercial use, the WEIGHTS are not. This effectively puts it in the same license class as GPT4All. Nomic is working on a GPT-J-based version of GPT4All with an open commercial license. GPT4All is not going to have a subscription fee ever. GPT4All is Free4All.
Although GPT4All is still in its early stages, it has already left a notable mark on the AI landscape. Its popularity and capabilities are expected to expand further in the future.
How to Run GPT4All Locally
GPT4All Readme provides some details about its usage. Here will briefly demonstrate to run GPT4All locally on M1 CPU Mac.
- Download
gpt4all-lora-quantized.binfrom the-eye. - Clone this repository, navigate to
chat, and place the downloaded file there. Simply run the following command for M1 Mac:
cd chat;./gpt4all-lora-quantized-OSX-m1
Now, it’s ready to run locally. Please see a few snapshots below:
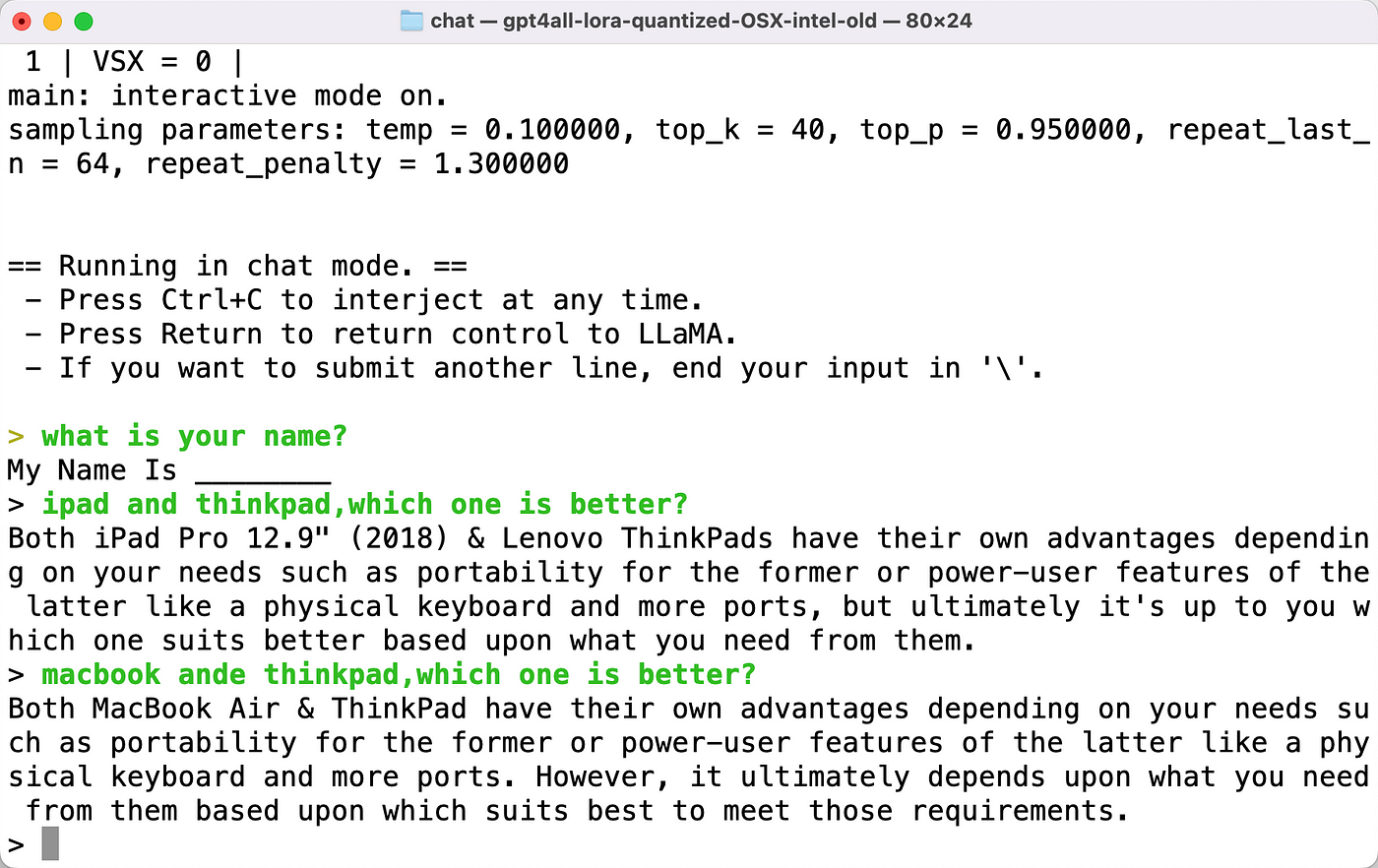

Similar to ChatGPT, GPT4All has the ability to comprehend Chinese, a feature that Bard lacks.
If you want to interact with GPT4All programmatically, you can install the nomic client as follows.
- Install the nomic client using
pip install nomic. - Use the following Python script to interact with GPT4All:
from nomic.gpt4all import GPT4All
m = GPT4All()
m.open()
m.prompt('write me a story about a superstar')
Chat4All Demystified
GPT4All aims to provide a cost-effective and fine-tuned model for high-quality LLM results.
The GPT4All model was fine-tuned using an instance of LLaMA 7B with LoRA on 437,605 post-processed examples for 4 epochs. Detailed model hyperparameters and training codes can be found in the GitHub repository.
GPT4All developers collected about 1 million prompt responses using the GPT-3.5-Turbo OpenAI API from various publicly available datasets. After an extensive data preparation process, they narrowed the dataset down to a final subset of 437,605 high-quality prompt-response pairs.
Developing GPT4All took approximately four days and incurred $800 in GPU expenses and $500 in OpenAI API fees. The final gpt4all-lora model can be trained on a Lambda Labs DGX A100 8x 80GB in about 8 hours, with a total cost of $100.
A preliminary evaluation of GPT4All compared its perplexity with the best publicly known alpaca-lora model. Results showed that the fine-tuned GPT4All models exhibited lower perplexity in the self-instruct evaluation compared to Alpaca. However, this assessment was not exhaustive due to encouraging users to run the model on local CPUs to gain qualitative insights into its capabilities.
TL;DR
Considering the expensive LLMs in training and serving, Meta LLaMA is a foundation for accelerating LLM open-source community.
Stanford’s Alpaca, based on LLaMA, offers an optimized smaller model with enhanced performance. Now, GPT4All, also built on LLaMA, enables local execution. Generative AI is evolving rapidly every day.
Thanks to Brandon Duderstadt for reviewing this article.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Related posts


Popular posts

 for 2021")



Updates

Recent Posts



