Logo:
Logo:  Areas Served:
Areas Served: Let’s Win at 7½ With RL!
Last Updated on July 20, 2023 by Editorial Team
Author(s): Alberto Prospero
Originally published on Towards AI.
Machine Learning
How reinforcement learning can be applied to find optimal strategies at 7½ (a game really similar to Blackjack!)
Introduction
“Winner, Winner, Chicken Dinner!”.In the movie 21, Ben Campbell and his team counted cards to win at blackjack, one of the most interesting and studied casino games, proving that mathematics and statistics indeed can be used to boost the common strategies used in these games. Since then, the scientific community has made enormous strides in conceiving methodologies and improving existing techniques, managing to reach top-level performances in several circumstances. Several of the most recent achievements have been possible using reinforcement learning and game theory techniques, which remarkably outperformed previous approaches.
In this tutorial, you will see how reinforcement learning can be applied to identify the best strategies in playing 7½, an Italian game quite similar to blackjack. Throughout the tutorial, I will assume you are familiar with reinforcement learning. If this is not the case, take a look at my previous post, which gently introduces RL-based concepts from the ground up. Also, the tutorial will be based on the code you can find on my GitHub repository.
Disclaimer: the content expressed in this article comes from my personal research and experience and does not have to be intended as financial, investment or gambling advice. The content is for informational purposes only and is intended as educational material.
So! Can we consistently win at 7½ with reinforcement learning? Read on to find it out!
The rules
The game is played with a 40-card deck, a standard deck with eights, nines, and tens removed. The value of cards ace through seven is their pip value (1 through 7), face cards are worth 0.5 points each. One special card (the 7 of diamonds) is called “mad”. Its value can range from 0.5 to 7 and corresponds to the highest possible which makes the total sum of the player cards closest to 7½. So for example, if the player holds 1,2 the mad worth is 4, while if he holds a fig it is worth 7.
There are different variations of the game. In the repository is supported the following two-player version:
- At the beginning of the game, player0 and player1 receive one faced-up card.
- Then, player0 decides either to draw a card from the deck or to stick to the current card: if he sticks his turn is ended, if he hits he receives a faced down card from the deck, and this step repeats. The player may stick or hit as long as he does not go bust (exceed 7½) In this case, he immediately loses the game.
- When the player0 sticks, player1 starts his turn and carries out the same process by repeatedly hitting a new card or sticking to his current set of cards. Again, if his card sum exceeds 7½, he immediately loses the game.
- Finally, if both players stuck without being bust, the sum of their card values is compared and the player with the highest score wins the game.
The strategy
First of all, we need to define what is an optimal strategy: it means identify a sequence of moves that consistently lead the player (assume player0) to win the game. Note that if we want to apply reinforcement learning to find out this strategy, we first need to fix the opponent’s policy. Recall that RL assumes a unique agent interacting with an environment. So, in our case, player0 will be the agent and all the rest (including player1) will be the environment. In our case, we fix the following policy for the opponent: as soon as he scores 4 or more, he sticks. Otherwise, he hits.
The next step is to identify what are, from the player’s perspective, the states of the game, the actions of the player, and the rewards provided from the environment to the player.
We can define a single state as the set of cards owned by the player at the current time. At the beginning of the game, the player will be in the state formed by no cards. Then, if for example, the player draws a 6, his current state is formed by this card. If the player owns [3,4, face] the state will be formed exactly by these cards. There is also a special state, which is the terminal state. The player reaches this state when it chooses to stick with the current cards or it went bust.
The actions the agent can take are easy to identify: at each state (except the terminal one) player0 can either hit, drawing a new card, or stick to his current set of cards.
The most difficult part is related to modeling the rewards. We need to specify the rewards the player will receive with respect to each action it takes at every state. Also, we need to recall that the aim of giving rewards is not to indicate the agent how it should achieve its goals (this is the task of the reinforcement learning indeed!), but rather what goals we want it to achieve. With this in mind we do the following:
- If the player hits, we always provide a reward of 0, except when the player goes bust. In this case, the reward is -1
- If the player sticks, we generate the combinations of cards that the opponent can reach without losing the game. So, if the opponent draws 2 as first card, some of these combinations will be [2,1,face,face], [2,1,4], [2,1,face,2], [2,2] and so on. Note that the combination [1,4,1] will not be considered because is not consistent with the initial opponent’s card. Also, [2,1,2,3] will not be generated, because this would cause the opponent to lose the game. Finally, neither the combination [2,2,1] will be generated, because the opponent’s policy prescribes to stop as soon as the score of 4 is reached. Now, we divide the generated combinations into three categories: those causing the player to win the game, those causing the players to tie the game, and those causing the opponent to win the game. At this point, for each of these combinations, we also compute the corresponding probability of occurring. For example, the combination [2,2] will have a probability of occurring given by the product between the probability of drawing a 2 at that specific point of the game followed by another 2. The combination [2,1, face, face] instead will have a probability of occurring given by the product of 4 single probabilities of drawing the 4 cards. Finally, the reward is computed by considering summing the occurring probabilities of those combinations causing the player to win or to tie the game, scaled in the range [-1, 1]. Quite complicated right? Well, no worries, it took me ages to device it! 🙂
At this point, we are ready to describe the reinforcement learning algorithm used to solve the game!
Dynamic Programming
Under the hood, we applied a reinforcement learning technique call policy iteration. This is one of the simplest techniques of reinforcement learning, which is used in several practical circumstances to find the best strategies.
Policy iteration is formed by two important phases:
- Policy evaluation that identifies the value of each state basing on the current policy.
- Policy improvement that updates the current policy according to the value of the states.
Hence, in policy evaluation, we keep fixed the current policy and try to improve the estimation of the state values of the game. In policy improvement, we keep fixed the state values and try to improve the current policy. These two steps apply cyclically up to convergence: once we identified the best state values, we move to policy improvement to determine the best policy. Once we identified the best policy, we move to policy evaluation to identify the best state values.
In the policy evaluation step, I applied dynamic programming. At the very core, dynamic programming is a natural extension of the Bellman equation, which introduces a recurrent relation for assessing the value of a state. According to the Bellman equation, this is computed based on the next environment dynamics and the value of the immediate next states. You can have a good grasp of this concept by looking at the following formula:

Dynamic programming applies the Bellman equation to find successive approximated state values which iteratively converge to true state values (the convergence can be proved under the exact same assumptions which guarantee the convergence of the Bellman equation).
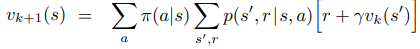
At the very beginning (k=0), we assign a constant value to each state (generally 0). Then, at k=1, we do a complete sweep of the states to find the next state values. If we assigned 0 as initial state values, only the states associated with a reward will change. At this point in fact, according to the formula, only the values with non-null r will cause the values to change. Next, at k=2 we repeat the process and do another complete sweep. Now, only the states placed before the states with a reward plus the states with a reward will be significantly involved by this formula. At k=3 the reasoning will apply again and so on.
As you might have noticed, dynamic programming works by propagating the effect of rewards starting from the states placed immediately closed up to the most distant ones. However, the important point is that as this formula is repeatedly applied for a sufficiently high number of times the changes of state values will start to get smaller and smaller, up to convergence.
For the policy improvement step, the typical choice is to apply greedy updates to improve the current policy. From the policy evaluation step, at each state we have a renewed set of state values. Among the choices we can apply, the greedy update prescribes to select the action which leads to the highest next state value. Are we sure that this procedure will actually bring us to a better policy? Well, the answer is yes. It can be shown that according to the policy improvement theorem this method will indeed improve the current policy.
Results
To realize how strong is the trained player, we consistently evaluate him against the opponent which plays according to the policy we defined above (i.e. as soon as he scores 4 or more, he sticks. Otherwise, he hits). Notice that the player was trained against this policy and only with respect to this policy he plays optimally.
Hence, I simulated 100000 random games and recorded for each of these if the player wins, if the players tie, or if the player loses the game. In the following plot you can look at the results:
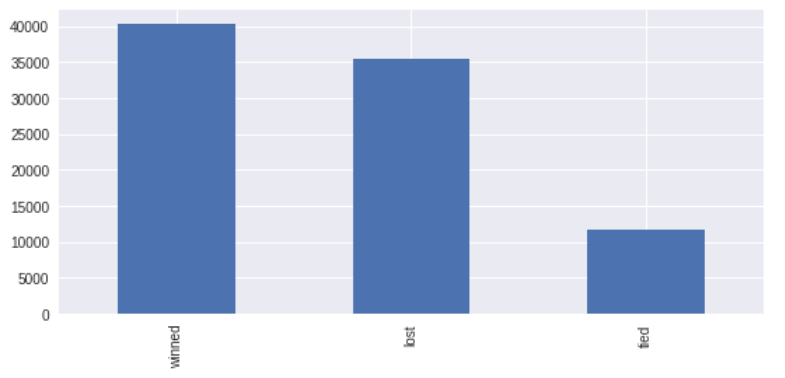
As you can see, the number of wined matches (40314) outperforms both the number of tied matches (11673) and the number of lost matches (35435). In other words, our trained agent can consistently beat on average the opponent. This is great!
Also, we can quantify more in detail the amount of money we would gain starting from an initial investment. Assume for example we play 100 games and at each game, we bet 1 unit. On average, we would win 40,3 games, would tie 11,6 games and would lose 35,4 games. This means that in the end, we would gain 40,3–35,4 = 4,9 units of money, which corresponds to a 4,9% return out of our initial investment. Not bad!
Conclusions
In this tutorial, we used reinforcement learning to find the optimal strategy when playing 7½. After the training, our agent consistently beats the opponent, which plays with a fixed strategy. If we had to invest some money, we would be sure that the expected gain will be around 4,9%!
Hope you enjoyed the article. Feel free to comment if you have any questions!
See you around, stay gold! 🙂
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Related posts
Popular posts

 for 2021")



Updates

Recent Posts