



LangChain 101: Part 2d. Fine-tuning LLMs with Human Feedback
Last Updated on November 5, 2023 by Editorial Team
Author(s): Ivan Reznikov
Originally published on Towards AI.
This is part 2d and the last part of the Models section of the LangChain 101 course. It is strongly recommended to check the first two parts to understand the context of this article better.
LangChain 101 Course (updated)
LangChain 101 course sessions. All code is on GitHub. LLMs, Chatbots
medium.com
LangChain 101: Part 2c. Fine-tuning LLMs with PEFT, LORA, and RL
All you need to know about fine-tuning llms, PEFT, LORA and training large language models
pub.towardsai.net
(follow the author in order not to miss the next parts :)
Overview
RLHF (Reinforcement Learning from Human Feedback) is an important component of the current training method of advanced language models. It helps include people’s feedback when finetuning models, ultimately making the model more valuable and secure.
Let’s go through the most common training methods:
Base model
A base model is a pre-trained large language model trained on a massive generalistic dataset of text (sometimes code): GPT, LLAMA, Falcon, and others.
Base models are good to use for text generation for general-purpose domains. However, their performance for specific tasks or domains may lack quality.
Prompting
Prompting is a technique that improves the performance of LLMs by providing the model with a prompt specific to the task.
For example, suppose you wanted an LLM to give you cooking advice. In that case, you might want to add something such as “Act as a professional Michellene chef” at the beginning of your query. The LLM would then use this prompt to “act as an experienced cook.”
Prompting is a simple way to improve the performance of LLMs. However, it requires a prompt design and is less effective for tasks requiring additional information and lexicon than the pre-trained LLM was trained upon.
Fine-tuning
Fine-tuning is a technique that improves the performance of LLMs by training them on particular datasets — examples of the desired input and output.
For example, you want to fine-tune an LLM to translate English to Arabic. In that case, you need to provide a dataset of English-Arabic translation pairs.
Fine-tuning is usually more effective than prompting for tasks that require the LLM to learn a lot of new data and information. However, it requires more data and computational resources.
LangChain 101: Part 2c. Fine-tuning LLMs with PEFT, LORA, and RL
All you need to know about fine-tuning llms, PEFT, LORA and training large language models
pub.towardsai.net
Fine-tuning + RLHF
Fine-tuning with reinforcement learning from human feedback (RLHF) is a technique that improves the performance of LLMs by training them on particular datasets of labeled data ranked by human evaluators. Such data includes examples of the desired input and output for the task and feedback from human evaluators on the production quality.
Fine-tuning with RLHF is usually more effective than fine-tuning alone, especially for tasks requiring an LLM to learn human values and preferences. However, it requires even more data, computational resources, and human effort.
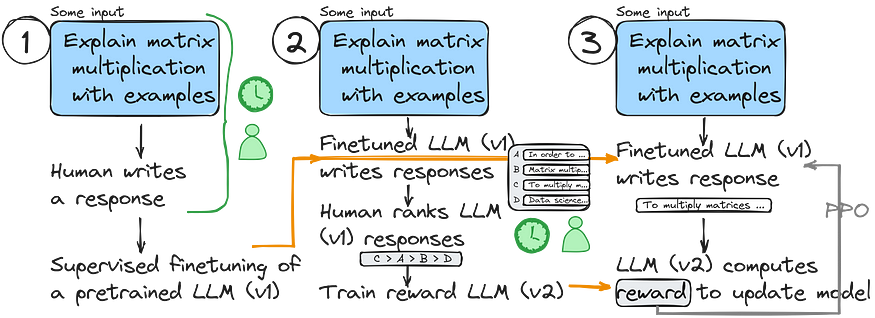
(Instruct)GPT RLHF pipeline
Let’s take a closer look at how the Instruct RLHF pipeline (most probably the ChatGPT pipeline looks similar) is constructed.
The Instruct(GPT) RLHF pipeline involves taking a pre-trained model and refining it through supervised training (similar to “Supervised finetuning” in the traditional training pipeline). Afterward, the updated model is further refined using proximal policy optimization.
The RLHF pipeline can be summed up as a 3-step training process:
- Refined training of the pre-trained model through supervision
- Development of a model for providing rewards
- Additional refinement using proximal policy optimization (PPO)
In the first step of the RLHF pipeline, we either generate or select prompts (potentially from a dataset or database) and request humans to produce high-quality responses. We utilize this data collection to finetune the pre-existing base model in a guided manner.

In RLHF pipeline step 2, we utilize the finetuned model via supervised training to construct a reward model for the next step. This involves generating multiple responses for each prompt and having individuals rank them according to preference.
To transform the model from RLHF pipeline step 1 to a reward model, we replace its output layer (the next-token layer) with a regression layer with a single output node.

In the 3rd and last step of the RLHF pipeline, we employ the reward model (v2) to finetune further the previous model that underwent supervised finetuning (v1).
We adjust the v1 model using proximal policy optimization (PPO) guided by the reward scores obtained from the reward model we established in RLHF pipeline step 2.

And this is pretty much how the (Instruct)GPT RLHF pipeline works. This method delivers quality results but requires much time and human effort. Can we do it more effectively?
LLAMA RLHF pipeline
The Meta AI Llama 2 model, while using a similar RLHF approach to InstructGPT, introduces several noteworthy differences:
- Two Reward Models
- Margin Loss
- Rejection Sampling
Two Reward Models: Llama2 employs two reward models, one focused on helpfulness and the other on safety. The final optimization of the model is based on a combination of these two scores.
Margin Loss: Llama2 introduces a “margin” label in ranking model responses, which measures the gap between preferences. This margin parameter helps refine the ranking loss calculation.

Rejection Sampling: Llama2 uses an iterative RLHF approach, creating multiple versions of the model (from RLHF-V1 to RLHF-V5). In addition to PPO, they employ rejection sampling.
This technique generates multiple outputs and selects the highest reward for gradient updates during optimization. It’s different from PPO, which updates based on a single sample.

The final pipeline will look as follows:

It is seen that choosing a better response out of 2 is faster than ranking a set of 4. Adding a margin also understandably helps the model learn faster, as it is similar to a classic ML training process. Finally, rejecting samples sounds like an interesting concept to gain quality at the end of the pipe.
Honourable mentions
Before we move to code, I’d like to list some other RLHF techniques:
Researchers introduce a self-training method based on a set of rules provided by humans.
The study introduces HIR (Hindsight Instruction Labeling), a two-step method involving prompt sampling and training, which effectively converts cases where the Language Model deviates from instructions.
The study on RLAIF demonstrates that ratings used for reward model training in RLHF can be generated by an LLM rather than solely relying on human input.
ReST is a method that aligns language models with human preferences through a sampling-based approach, iteratively training on progressively higher-quality subsets to enhance its reward function
Time to Code
The full code is available on GitHub.
First, we’ll need to define the general training and Lora config parameters we’ll be using. This is very similar to the code from the fine-tuning part of the series.
from transformers import TrainingArguments
from peft import LoraConfig
# Prepare training parameters
training_args = TrainingArguments(
output_dir="./train_logs", # Output folder
max_steps=100, # Maximum number of training steps
per_device_train_batch_size=4, # Batch size per GPU for training
gradient_accumulation_steps=1, # Number of steps to accumulate gradients
learning_rate=1.0e-4, # Learning rate
optim="adamw_torch", # Optimizer
save_steps=50, # How often to save checkpoints
logging_steps=10, # How often to log training information
report_to="tensorboard", # Reporting method (in this case, TensorBoard)
remove_unused_columns=False, # Whether to remove unused columns
evaluation_strategy="steps", # Evaluation strategy
num_train_epochs=5, # Number of training epochs
)
# Prepare PEFT parameters
peft_config = LoraConfig(
r=16, # Value of r
lora_alpha=16, # Value of lora_alpha
bias="none", # Bias setting
task_type="SEQ_CLS", # Task type (Sequence Classification)
modules_to_save=["scores"], # Modules to save
)
Now, it’s time to define our RLHF pipeline.
First, let’s define our data. Usually, RLHF is excellent for production when you have a dataset of incorrectly answered questions. It might be a thumb-down answer, for example.

Later, we’ll format and split this dataset to use for training and testing our model. As we now have the human feedback in place, let’s specify the code for reinforcement learning:
from trl import RewardTrainer
# Prepare RewardTrainer
trainer = RewardTrainer(
model=model, # The model for reinforcement learning
tokenizer=tokenizer, # The tokenizer for processing input data
args=training_args, # Training arguments
train_dataset=formatted_dataset["train"], # Training dataset
eval_dataset=formatted_dataset["test"], # Evaluation dataset
peft_config=peft_config, # PEFT configuration
max_length=512, # Maximum length of input
)
# Execute training
trainer.train()
# Save the pretrained reward model
trainer.model.save_pretrained("./reward_model")
This is all we need to run reinforcement learning with human feedback!
Now you know when to use RLHF, how the data should look, and how to run the code.
This is the end of Part 2d. This is the last part of the Models part of my LangChain 101 course.
LangChain 101 Course (updated)
LangChain 101 course sessions. All code is on GitHub. LLMs, Chatbots
medium.com
Reminder: The complete code is available on GitHub.

Clap and follow me, as this motivates me to write new parts and articles 🙂 Plus, you’ll get notified when the new part will be published.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts






")