



LangChain 101: Part 1. Building Simple Q&A App
Last Updated on August 1, 2023 by Editorial Team
Author(s): Ivan Reznikov
Originally published on Towards AI.
Introduction
LangChain is a powerful framework for creating applications that generate text, answer questions, translate languages, and many more text-related things. I’ve been working with LangChain since the beginning of the year and am quite impressed by its capabilities.
This article is the start of my LangChain 101 course. I’ll start sharing concepts, practices, and experience by showing you how to build your own LangChain applications.
Today, we will discuss the following topics:
- What exactly is LangChain?
- LangChain’s fundamental concepts and components
- How to build a basic LangChain application
What is LangChain?
Lang stands for language, which is the primary focus of LangChain, and chain — the connotation of connecting things — refers to the chain component used in LangChain. Chains are sequences of instructions that the framework executes to perform a task. This simplifies the use of Large Language Models for specific tasks and enables you to combine the power of LLMs (Large Language Models) with other programming techniques.
I’ve been asked how LangChain differs from ChatGPT or LLM. To answer this question, I’m attaching a table that highlights the differences:
+==========+========================+====================+====================+
U+007C U+007C LangChain U+007C LLM U+007C ChatGPT U+007C
+==========+========================+====================+====================+
U+007C Type U+007C Framework U+007C Model U+007C Model U+007C
+----------+------------------------+--------------------+--------------------+
U+007C Purpose U+007C Build applications U+007C Generate text U+007C Generate chat U+007C
U+007C U+007C with LLMs U+007C U+007C conversations U+007C
+----------+------------------------+--------------------+--------------------+
U+007C Features U+007C Chains, prompts, LLMs, U+007C Large dataset of U+007C Large dataset of U+007C
U+007C U+007C memory, index, agents U+007C text and code U+007C chat conversations U+007C
+----------+------------------------+--------------------+--------------------+
U+007C Pros U+007C Can combine LLMs with U+007C Generates nearly U+007C Generates realisticU+007C
U+007C U+007C programming techniques U+007C human-quality text U+007C chat conversations U+007C
+----------+------------------------+--------------------+--------------------+
U+007C Cons U+007C Requires some U+007C Not as easy to use U+007C Not as versatile U+007C
U+007C U+007C programming knowledge U+007C for specific tasks U+007C as LangChain U+007C
+----------+------------------------+--------------------+--------------------+
Basic components of LangChain
There are six basic components of Langchain:
– Models
– Prompts
– Chains
– Memory
– Indexes
– Agents and Tools
Let’s briefly talk about all components.
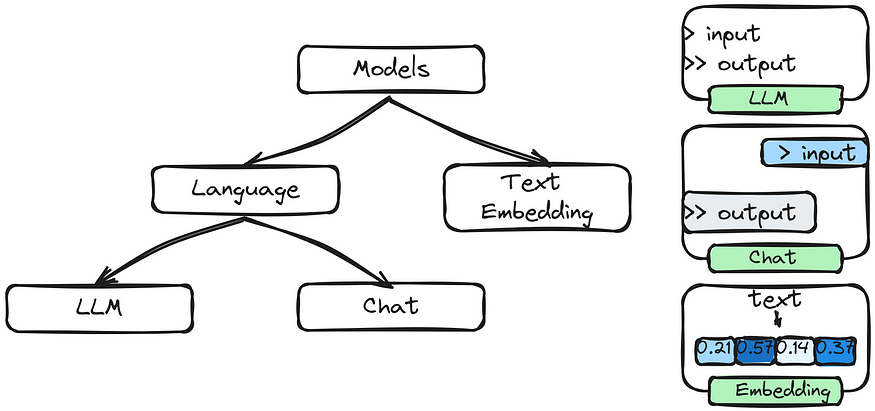
Models
Models in LangChain are large language models (LLMs) trained on enormous amounts of massive datasets of text and code.
Models are used in LangChain to generate text, answer questions, translate languages, and much more. They are also used to store information that the framework can access later.
Examples: GPT-x, Bloom, Flan T5, Alpaca, LLama, Dolly, FastChat-T5, etc.
Prompts
Prompts are pieces of text that guide the LLM to generate the desired output. Prompts can be simple or complex and can be used for text generation, translating languages, answering questions, and more.
In LangChain, prompts play a vital role in controlling the output of the LLM. You can influence the LLM to generate the desired output by carefully crafting the prompt.
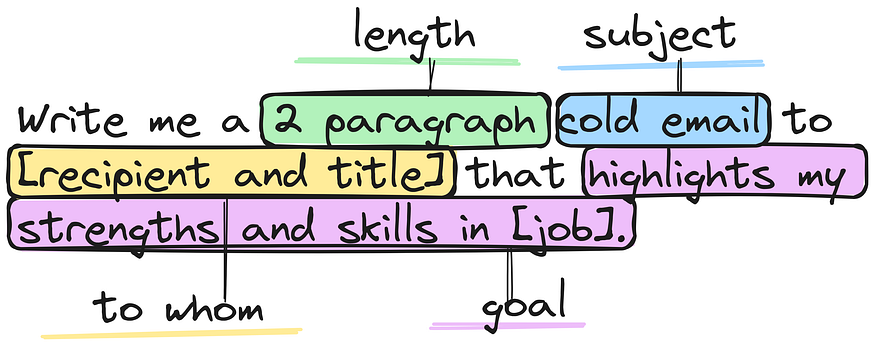
Here are some examples of how prompts can be used:
- Specify the desired output format: You can, for example, use a prompt to instruct the LLM to generate text, translate languages, or answer questions.
Example: Translate the input to Arabic - Provide context: A prompt can provide context for the LLM, such as information about the output topic or examples of the desired output.
Example: Explain the answer step-by-step like a school teacher - Constrain the output: You can use a prompt to limit the LLM’s output by specifying a maximum length or selecting a list of keywords to include in the output.
Example: Generate a tweet post using less than 140 words
Indexes
Indexes are unique data structures to store information about the data content. This information can include terms found in each document, document location in the dataset, relationships between documents, etc. Vectorstores are data structures storing vector representations of a dataset’s terms. A retriever is an interface that returns documents in response to an unstructured query. It is broader in scope than a vector store.
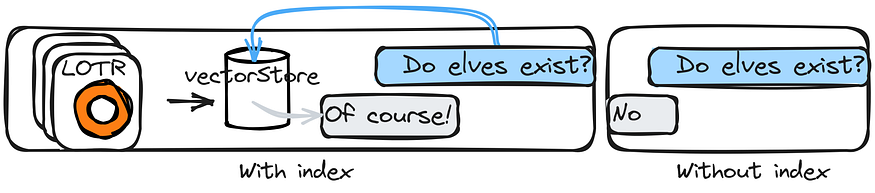
Understanding indexes, vectorstores, and retrievers is key to building an app on your specific data. Consider another example of a chain that includes all three components:
- A chain is formed to answer financial questions.
- The chain uses an index to find all documents that contain the word “finance.”
- The chain uses a vectorstore to find other terms that are most similar to the word “finance” (“money,” “investments,” etc.).
- The chain uses a retriever to retrieve the documents that are ranked highest for the query “What are ways to invest?”.
Memory
Memory in LangChain is a method of storing data that the LLM can later access. This information can include previous chain results, the context of the current chain, and any other information that the LLM requires. It also enables the application to keep track of the current conversation’s context.
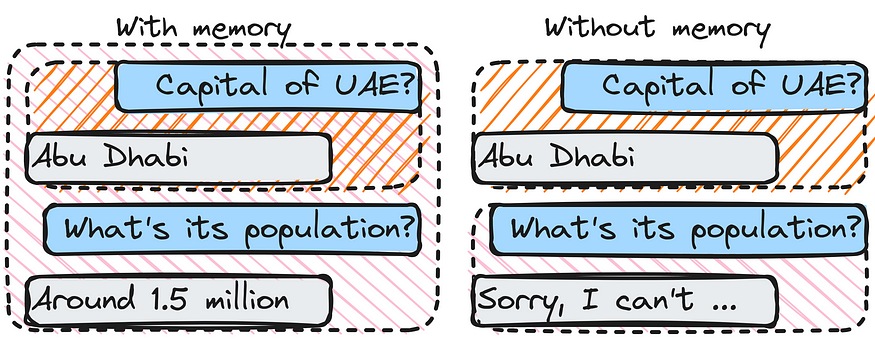
Memory plays a vital role in LangChain, allowing the LLM to learn from previous interactions and build up a knowledge base. This knowledge base can then be used to improve the performance of future chains.
Consider the creation of a chain designed to answer real estate-related questions. The chain may use memory to store the results of previous chains that have responded to real estate questions. When the chain asked a new question about a similar topic, this information could be used to improve its performance.
Chains
Chains are sequences of instructions the LangChain framework executes to perform a task. Chains may connect other LangChain components based on the application requirements. They allow the framework to perform a wide variety of tasks.
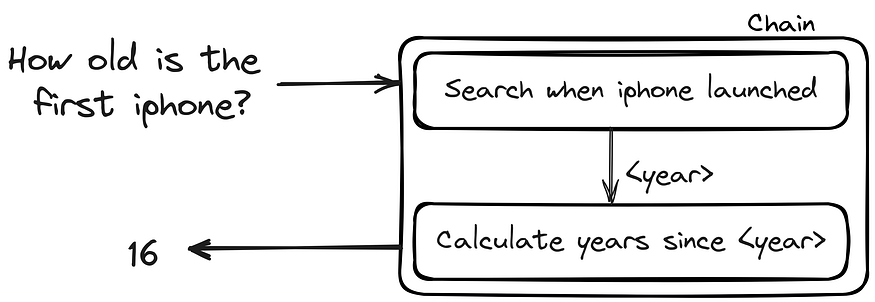
Assume we’re creating an app to assist us in interview preparation:
- Prompt: “I’m getting ready for an interview for a position as a software engineer. Can you ask me some common interview questions that I may expect?”
- Function A: This function would access the LLM’s knowledge of the software engineering field, such as its knowledge of common interview questions for software engineers. It can also look for appropriate data in the vectorstore.
- Function B: This function would manipulate data, such as generating a list of common interview questions for software engineers or a list of resources to help the student prepare for the interview. It will select a question and ask it.
- Memory: some follow-up questions might be asked to help better understand the knowledge of the chosen topic. Memory implementation will allow the chain to keep the context of the conversation.
Agents and Tools
Agents and tools are two important concepts in LangChain.
Agents are reusable components that can perform specific tasks such as text generation, language translation, and question-answering. Tools are function libraries that can be used to aid in developing various agents.
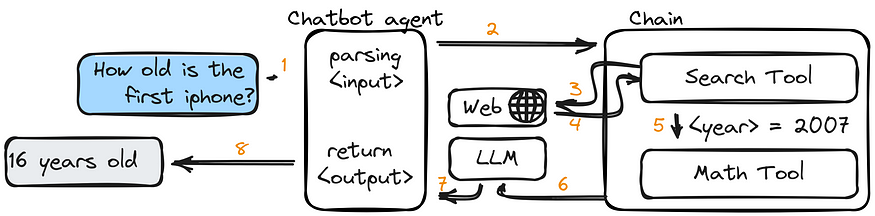
Examples:
NewsGeneratoragent — for generating news articles or headlines.DataManipulatortool — for manipulating data (cleaning, transforming, or extracting features).
Application. Building a Q&A system.
Let’s build a Q&A system to answer our questions regarding official holidays in the United Arab Emirates. Based on the components we’ve learned, we can draw a schema similar to the following one below:
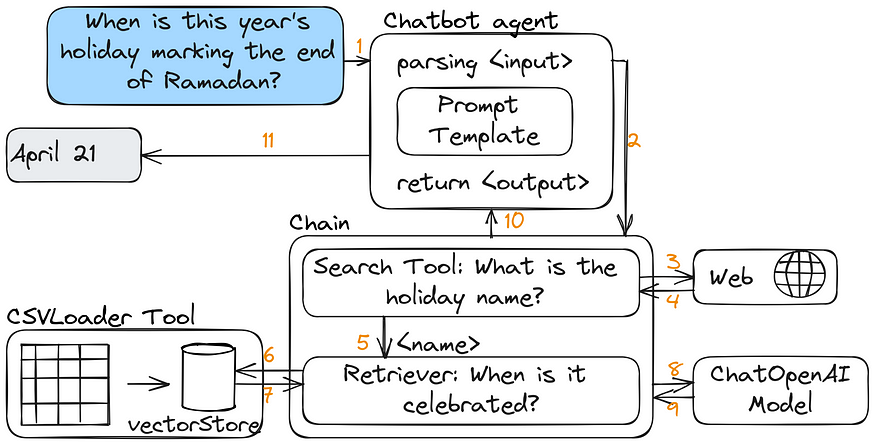
First, we install all dependencies. Some of the versions might be updated, but installing a specific version will resolve most, if not all, inner dependencies.
pip install chromadb==0.3.25
pydantic==1.10.9 openai==0.27.8 bs4 tiktoken==0.4.0 langchain==0.0.235
huggingface_hub==0.16.4 sentence_transformers==2.2.2 panda
The data we’ll be using can be found at the following website, as shown in the table below:
+--------+-----+-----------------------------+
U+007C Date U+007C Day U+007C Holiday U+007C
+--------+-----+-----------------------------+
U+007C 1 Jan U+007C Sun U+007C New Year's Day U+007C
U+007C 20 Apr U+007C Thu U+007C Eid al-Fitr Holiday U+007C
U+007C 21 Apr U+007C Fri U+007C Eid al-Fitr U+007C
U+007C 22 Apr U+007C Sat U+007C Eid al-Fitr Holiday U+007C
U+007C 23 Apr U+007C Sun U+007C Eid al-Fitr Holiday U+007C
U+007C 27 Jun U+007C Tue U+007C Arafat Day U+007C
U+007C 28 Jun U+007C Wed U+007C Eid al-Adha U+007C
U+007C 29 Jun U+007C Thu U+007C Eid al-Adha Holiday U+007C
U+007C 30 Jun U+007C Fri U+007C Eid al-Adha Holiday U+007C
U+007C 21 Jul U+007C Fri U+007C Islamic New Year U+007C
U+007C 29 Sep U+007C Fri U+007C Prophet Muhammad's Birthday U+007C
U+007C 1 Dec U+007C Fri U+007C Commemoration Day U+007C
U+007C 2 Dec U+007C Sat U+007C National Day U+007C
U+007C 3 Dec U+007C Sun U+007C National Day Holiday U+007C
+--------+-----+-----------------------------+
After we store the data in memory or dataframe, we can import the necessary packages:
# Load language model, embeddings, and index for conversational AI
from langchain.chat_models import ChatOpenAI #model
from langchain.indexes import VectorstoreIndexCreator #index
from langchain.document_loaders.csv_loader import CSVLoader #tool
from langchain.prompts import PromptTemplate #prompt
from langchain.memory import ConversationBufferMemory #memory
from langchain.chains import RetrievalQA #chain
import os
os.environ['OPENAI_API_KEY'] = 'sk-...'
In this tutorial, we’ll use OpenAI API key. We can put all the modules in place now.
def load_llm():
# Setting up the LLM model
llm = ChatOpenAI(temperature=0,model_name="gpt-3.5-turbo")
return llm
def load_index():
# if you want to avoid the step of saving/loading a file,
# you can use the `from_documents()` method of the VectorstoreIndexCreator()
loader = CSVLoader(file_path='uae_holidays.csv')
index = VectorstoreIndexCreator().from_loaders([loader])
return indextemplate = """
You are a assistant to help answer when are the official UAE holidays,
based only on the data provided.
Context: {context}
-----------------------
History: {chat_history}
=======================
Human: {question}
Chatbot:"""# Create a prompt using the template
prompt = PromptTemplate(
input_variables=["chat_history", "context", "question"],
template=template
)# Set up conversation memory
memory = ConversationBufferMemory(memory_key="chat_history",
return_messages=True, input_key="question")# Set up the retrieval-based conversational AI
qa = RetrievalQA.from_chain_type(
llm=load_llm(),
chain_type='stuff',
retriever=load_index().vectorstore.as_retriever(),
verbose=True,
chain_type_kwargs={
"prompt": prompt,
"memory": memory,
}
)
We’ll talk in more detail about all the components. For the moment, we’ve chosen gpt-3.5-turbo from OpenAI, a custom prompt, out of the box VectorstoreIndexCreator(), set up the ConversationBufferMemory to keep track of chat_history and chained everything into a RetrievalQA chain.
Holidays in March/December
query = "Are there any holidays in March?"
print_response_for_query(query)
> Finished chain.
Based on the data provided, there are no holidays in March.
Correct response. What about December?
query = "Sorry, I meant December"
print_response_for_query(query)
> Finished chain.
Based on the data provided, there are two official holidays in December
for the UAE. The first one is Commemoration Day on December 1st, which
falls on a Friday. The second one is National Day on December 2nd, which
falls on a Saturday. Additionally, there is a National Day Holiday on
December 3rd, which falls on a Sunday.
Did you notice how we used the memory here? If it wasn’t for it, the response would’ve sounded as:
> Finished chain
Sorry, I can't understand you. What exactly are you looking for in December?
It is worth noticing that despite the error in counting two official holidays at the beginning, the response contains all three holidays in the list. A prompt upgrade may solve the issue.
Multichain Ramadan example
Now let’s ask a trickier question.
query = "When does this year's holiday marking the end of Ramadan start?"
print_response_for_query(query)
So now, the chain will need to find the information about the name of the holiday that marks the end of Ramadan and only after that retrieve the required information from the table.
> Finished chain.
This year's holiday marking the end of Ramadan, also known as Eid al-Fitr,
starts on April 21st.
This is quite interesting. The chain correctly identified Eid al-Fitr as the end-of-Ramadan holiday. The issue is that the data is dirty, and the model cannot recognize that it is a four-day weekend. Of course, the easy solution here would be to either clean the data, possibly through tools or modify the prompt.
What is the closest upcoming holiday?
Last for today is retrieving what official holiday is next in line.
query = "Today is July 16. When is the nearest holiday?"
print_response_for_query(query)
> Finished chain.
The nearest holiday is the Islamic New Year, which falls on July 21st.
As one can see, the nearest holiday is detected correctly. I’m leaving it to you to think of the possible chain that was built to answer the question.
Conclusion
In this lecture, we have learned about the basics of LangChain, including models, chains, prompts, agents, memory, and indexes. We have also seen examples of how LangChain can perform different tasks and build an app for answering questions.
Upcoming lectures
The LangChain 101 course is currently in development.
Later in the course, we’ll learn:
- how to we utilize models on our computers
- how to use own data
- how to use chains to execute more complex tasks
- how to use memory to store information
- and much more.
We will continue building real-world apps with LangChain.
Consider following me on Medium or LinkedIn to learn more about LangChain and get updates, including new lectures, features, tutorials, and examples.
Thank you for your time!

Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Related posts


Popular posts

 for 2021")



Updates

Recent Posts



