



How Tesla has been Optimizing its Software and Hardware for FSD Capabilities and a Hyper Efficient Robo-Taxi Fleet?
Last Updated on July 19, 2023 by Editorial Team
Author(s): Sandeep Aswathnarayana
Originally published on Towards AI.
Computer Vision, Self Driving Cars
FSD Chip Tour, Solving the Vision Problem, Fleet Learning using Data Engine, Object Detection using Vector Space, Sensor Redundancy, Shadow Mode, Robo-Taxi Cost Model, and more.
Note to Readers:
I have neither directly worked nor do I have a comprehensive understanding of the working of the Hardware. So, for the most part, I have introduced only the specifications and a brief overview of the Hardware in Part 3 of this article.
Please be advised that the flow of this article is leaned towards providing intuition and technical insights about Autopilot AI as opposed to storytelling.
Though all the images are available on public platforms, all rights and credit pertaining to the facts and images in this article belong to Tesla.
Motive:
I have been following and hearing about Tesla’s work over the past 6 years or so, but I have been listening to them only from the past couple of years.
I believe, to innovate, we need to stay curious and push the boundaries of our scientific limits. Needless to mention, incorporating an optimistic mindset and culture is pivotal to overcoming the challenges while pursuing these endeavors. Also, Innovation (say, space exploration) fosters a peaceful connection with other nations by finding a common ground. This article is one such example that encompasses my understanding and intuition of Tesla Autopilot AI and its potential that are backed by some facts and ongoing research.
Brief Overview:
PART 1:
Andrej Karpathy (Director of AI and Autopilot Vision)
Concepts covered: The Essentials for Neural Networks (Large dataset, Varied dataset, Real dataset), Object Detection, Corner Cases, Data Engine, Fleet Labeling & Learning, Path Prediction, Depth Perception from VISION only.
PART 2: Stuart Bowers (Former VP of Engineering)
Concepts covered: Packaging the Hardware and AI into a viable product at production, Sensor Redundancy, Vector Space, Shadow Mode, Feature lifecycle.
PART 3: Pete Bannon (VP of Hardware Engineering)
Concepts covered: A Full Tour of FSD Computer — Image Signal Processor, Neural Network Processor, Video Encoder, GPU, Main Processor, Safety System, Security System, Control Energy, Post Processing, Neural Network Compiler, HW 2.5 vs FSD Results Comparison.
PART 4: Elon Musk
Concepts covered: The Robo-Taxi Fleet & Cost Model, The Future of Self-Driving.
PART 1: Andrej Karpathy, Director of AI and Autopilot Vision
A brief overview of Andrej’s work on VISION:
- Primer on Neural Networks
- The Fleet Advantage
- Vision & LiDAR
Primer on Neural Networks: Visual Recognition, Interpretation, Artificial Neural Networks.
Note: To get an overview of Convolutional Neural Networks, I recommend getting started by watching all the CS231n lecture videos on YouTube. The slides and synopsis for all the sessions from Winter 2015–16 are available on the course website.
Lane Labeling:
Train the neural network for interesting lane markings (say, curved lanes) with labeled data.

Variety in the dataset:
- Train for unique conditions including, but not limited to, lighting, shadows, tunnels.
- How to approach this challenge? — annotate and train as many corner case images as possible.


Why Simulation isn’t an optimal approach?
- Simulation is like ‘grading your own homework’ where you already know (or at least are aware of) what’s coming.



- Simulation has trouble with modeling the appearance, Physics, and behavior of agents around you.
- On the contrary, the real world has millions of corner cases or edge cases.
- So, what’s essential for neural networks? — Large dataset, Varied dataset, Real dataset.
Object Detection:
Corner Case Example


Solution:
Ask the fleet for similar images collected across the world. Now, collect them and annotate each such image as a single-car i.e., do not annotate the bike as a separate object in this case. Following this labeling technique eventually improves the performance of the detector.
Other Corner Case Examples:


Data Engine:
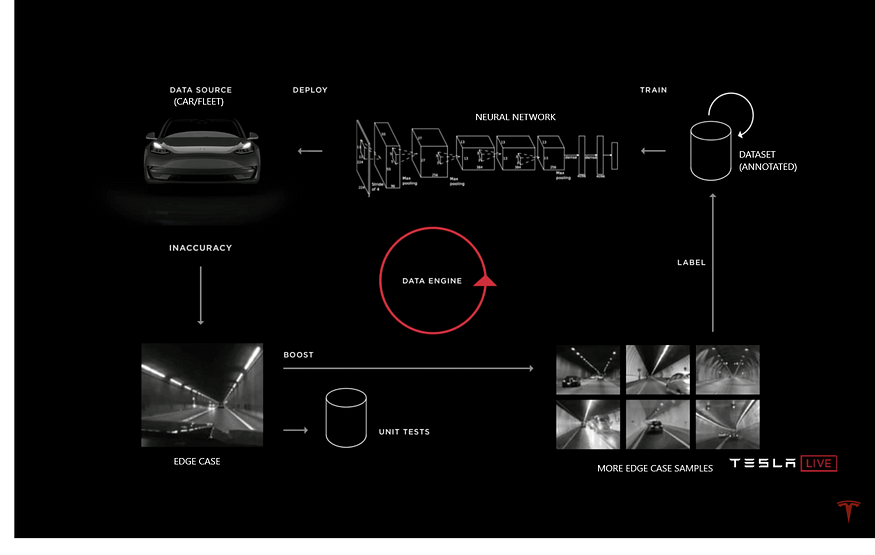
Data Engine: The process by which the team at Tesla iteratively applies active learning to source examples in cases where the detector is misbehaving. Then, the team sources examples in those, label, and incorporate them into as a part of the training set.
This is a feedback loop where the Autopilot driving errors (flagged by disengagements, aborts, and crashes) lead Tesla Engineers to identify a problem and design a trigger to collect sensor data relevant to that problem.
The Core Principle and the Feedback Loop of the Data Engine:
- Annotate the initial dataset with new object classes
- Train the Neural Network model to detect the new objects
- Evaluate the Model Performance
- Identify the cases in which the Performance is low
- Add those to data Unit Test
- Deploy models to the Car Fleet in ‘Shadow Mode’ to fetch similar edge cases
- Retrieve the cases from the Car Fleet
- Review and label collected edge case samples
- Retrain the model
- Repeat Steps 6-9 until the model performance is acceptable
How does the Data Engine help address the ‘long tail’ problem?
- The AI team at Tesla is pushing the envelope of deep learning by combining multi-task learning and this massive “data engine” to collect rare examples and corner cases which are the essence of addressing the long tail problem.
- It helps ensure data can be collected in the most efficient manner in order to cover the extremely long tail of examples required for models to reliably perform in a real unconstrained world.
How can the Data Engine ensure the labeling team won’t be overwhelmed by False Positives?
Karpathy mentions a few approaches to overcome this bottleneck in his talk at ScaledML Conference 2020, also admitting that no method works perfectly. Some of the challenging examples with lack of health of the detector at test time include a flickering stop sign, neural network uncertainty from a Bayesian perspective, instances where you were surprised to see a stop sign only after nearing or closing in, map-vision disagreement in detection.
Tesla’s Fleet Advantage:
The principle at the core of the Data Engine is not unique to Tesla: it is inspired by Active Learning and has been a hot topic of research for years. The competitive advantage Tesla has is its unmatched scale of fleet learning and data collection.
Lex Fridman’s Tesla Autopilot Mileage Statistics show that Tesla has collected more than 3 billion miles in autopilot and is currently leading by (at least) a factor of 100 over its competitors.
Data collection is not always possible and easy — often due to privacy and other regulations — but Tesla has made sure that being transparent with the customers about data collection and fleet advantage would mutually benefit both in the long run.
Reiterating the above statement with an example scenario: Tesla, as of June 2020, has been making a gross profit of 20.99%, and moreover it doesn’t have to pay its customers for data collection (except for the infrastructure costs to maintain, store, label, and process data). As a result of this, the customers could get over-the-air software updates at an affordable price and at a faster pace due to the exponential growth in Innovation.
Fleet Labeling Data Automatically:
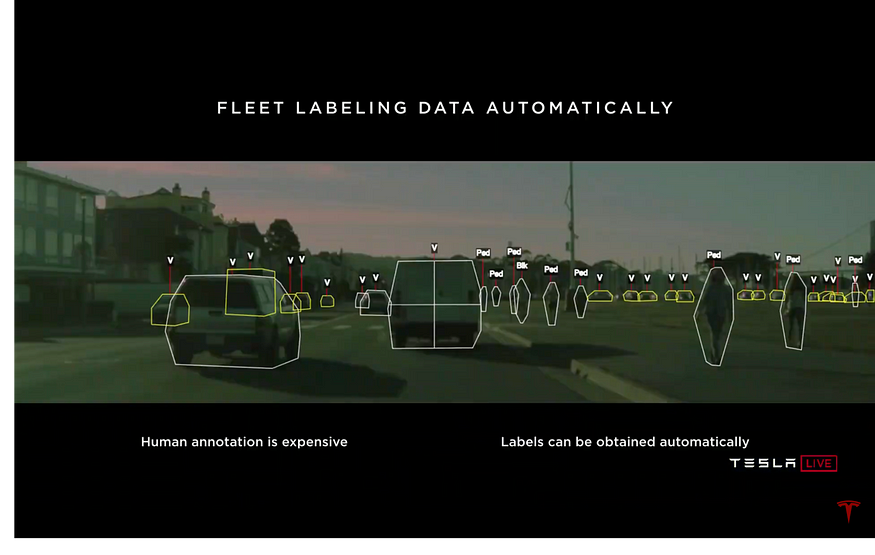
Fleet Learning: Cut-Ins
An example scenario: A car, ahead of us, trying to change the lane.
Steps taken by the Tesla Engineers to approach this edge case:
- Rewind the time backward
- Automatically annotate data based on its behavior
- Train the neural network
- Run the neural network on the car in the “Shadow Mode”
- Analyze and balance the False Positives and False Negatives (Train the neural network for interesting cases, say, the car ahead of us just keeps teasing and doesn’t really make the lane change)
How does ‘Shadow Mode’ help the regulators evaluate Tesla’s Safety and Reliability?
In shadow mode, the car isn’t taking any action, but it registers when it would have taken action. So, the car will run Autopilot in “shadow mode” in order for Tesla to gather statistical data to show false positives and false negatives of the software. It will record how the car would have acted if the computer was in control, including information about how the car might have avoided an accident (or caused one). That data would then be used to show a material improvement in the accident rate over manually driven cars.
Path Prediction:
Steering angle, curves, complicated path, etc. — all become a part of your fleet’s labeled data.
Imitation Learning: Imitation Learning, in this case, could be defined as taking the human trajectories from the real world and try to imitate how people drive in the real world. Then, apply the same Data Engine crank to all of this and make this work with time. By turning on the Augmented Vision, you can see lane lines and path prediction in the car overlaid in the video. (NOTE: The team at Tesla concentrates on imitating only the better drivers, which involves a lot of technical ways to slice and dice that data.)
The prediction actually is a 3D prediction that is projected back to the image (see image to the left below). We know about the slope of the ground from all of this, which is extremely valuable for driving.


The 3 key components of how Tesla iterates on the predictions of the network and make it work with time:

Depth Perception using VISION only:
Three examples of Depth Perception from VISION include:
- Classical Computer Vision
- Sensor Supervision
- Self-supervision
(1). Classical Computer Vision
This mostly includes solving problems in Image Processing and Object Detection. The following sections concentrate on how Tesla leverages Sensor Supervision and Self-supervision for Depth Perception.
(2). Vision Learning from RADAR: Sensor Supervision
Neural Networks are very powerful visual recognition engines and they can predict ‘depth’ (monocular depth) using the labels of depth.
Example Project to demonstrate this: Use the forward-facing RADAR, where the RADAR is looking at the depth of the objects. Now, we use the RADAR to annotate what the Vision is seeing i.e., bounding boxes that come out of the neural network.


So, the depths of the cuboids are learned through the ‘Sensor Annotation’ of RADAR. You would see that the circles in the top-down view would agree with the cuboids, which reemphasizes the fact that it’s working very well. This is because neural networks are very competent at predicting depths. They can learn the different sizes of the vehicle internally which helps derive depth from this quite accurately.
(3). Depth from VISION: Self-Supervision

You only feed raw videos (with no labels) into neural networks and get them to learn depth.
Idea: The neural network predicts depth at every single frame of the video with no explicit targets that it is supposed to regress to, with the labels. Instead, the only objective of the network is to be consistent over time i.e., the depth you predict has to be consistent over the duration of that video.
Conclusion:

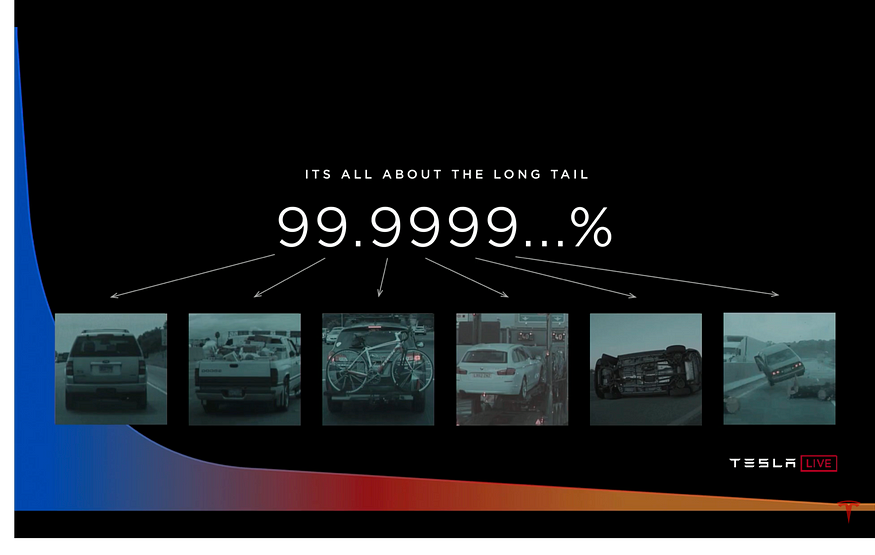
Is the object in the top-left image a tire or a plastic bag? — LiDAR can only give you a few points on that. But Vision can tell you which one of those two is true that eventually impacts your Control. The answers to these questions play a key role in attaining Level-4 and Level-5 autonomy.
Most of the autonomy that can handle all possible cases falls in the 99.99% range. Chasing some of the last few 9s is going to be very tricky and difficult. It’s going to require a very powerful visual system. Given below are some images of what you might encounter in any one slice of those 9s.
Here’s an overview of Tesla Vision, Advanced Sensor Coverage, Processing Power, Autopilot, Future of FSD Capability, Standard Safety Features.
Q&A Responses:
- Variety >>> Scale — It’s really the variety of data that matters and not the scale of the data.
- Why VISION over LiDAR?
a. LiDAR is expensive hardware.
b. Once you solve Vision, LiDAR is worthless in this case. But, cameras need to have enough resolution to know that you are braking for a real object, and not just a bridge or a manhole cover.
c. If you want to use LiDAR, use a wavelength that is occlusion-penetrating like RADAR so it can help see through fog, rain, dust, etc. You can rely on RADAR at approximately 4mm wavelength.
d. LiDAR, fundamentally, is just active photon generation in the visible spectrum. We already have enough redundancy with 12 ultrasonic sensors for near field information, 8 cameras, forward-facing RADAR. Do we really need anything more? — NO!
- Use GPS data only for trips and tricks but not as the primary source for Perception/Depth.
- An optimized training infrastructure — The neural net is steadily eating into the software base more and more over time. Also, Tesla is working towards integrating a new inference computer called Dojo, which is basically a training infrastructure that is optimized to perform unsupervised learning from the video at scale. The goal of Dojo will be to take in vast amounts of data — at a video level — and do unsupervised training of vast amounts of video with the Dojo computer.
“The Dojo system — that’s like an FP16 training system and it is primarily constrained by heat and by communication between the chips. We are developing new buses and a new sort of heat projection or cooling systems that enable a very high operation computer that will be able to process video data effectively.”
— Elon Musk on Dojo at (Virtual) World AI Conference 2020, Shanghai.
Note: Half-precision floating-point format (FP16) uses 16 bits, compared to 32 bits for single-precision (FP32). Lowering the required memory enables training of larger models or training with larger mini-batches. Shorten the training or inference time. Execution time can be sensitive to memory or arithmetic bandwidth. More on FP16 on Deep Learning Performance Documentation.
PART 2: Stuart Bowers, (Former) VP of Engineering
A brief overview of Stuart’s work:
- Taking the cutting-edge ML and connecting that with customers with robustness and scale.
- Take the amazing things happening at both the Hardware side and AI side — Package these together with all the Planning, Control, Testing, Kernel patching of the OS, Continuous Integration, Simulation, and built this into a product to get onto cars in production.
How could this be achieved with ‘Navigate on Autopilot’?
Currently, the Tesla fleet has added 70+ million miles off ‘Navigate on Autopilot’ — With the Data Engine and Tesla Fleet, making more assertive lane changes become seamless. The team at Tesla tries to learn from these cases and intervene where necessary (in failed scenarios).
Sensor Redundancy:
- 8 cameras for 360-degree view, 12 ultrasonic sensors, RADAR, Inertial Measurement Unit, GPS, Pedal/Steering wheel angle sensor.
Understanding the world around:
- A single neural network helps see the detections around it, then build all of that together by scaling using multiple neural networks and multiple detections. Now, by bringing in the other sensors, convert these detections into a ‘Vector Space’ which helps understand the world around the vehicle. These neural networks and detection get better with more varied data, tuning, and training.

- With a redundant visual system, Tesla helps get overlapping fields of view from multiple cameras. By combining this with RADAR and ultrasonic sensors, gaining an understanding and building accurate predictions become seamless. This plays a pivotal role in building the next generation Automatic Emergency Braking (AEB) systems to avoid or mitigate car crashes.

Shadow Mode:
With Tesla integrating new algorithms over time, it helps observe driver actions & traffic patterns more meticulously. Finally, see what actions/decisions the fleet would have taken in the real-world scenarios.

With more tuning of parameters and training of ML models, Tesla helps attain the ‘Controlled Deployment’ which is still an early access program at Tesla.

Run sophisticated Data Infrastructure to understand over time, tune and fix these algorithms and get closer to human behavior and eventually exceed them.

With wide rollout and Continuous Integration, Tesla collects data from the fleet including some of the interesting cases, such as simultaneous merging on the highways. Data collected from these scenarios help decide on the appropriate behavior and parameter tuning of the neural networks. Over the course of time, there have been 9+ million successfully accepted lane changes. And, there are currently over 100,000 automated lane changes per day on the highways.


With the infrastructure, tooling, and combined power of the FSD computer, the Data Engine crank would rapidly increase with time as Tesla moves ‘Navigate on Autopilot’ from the Highway System to the City Streets.
PART 3: Pete Bannon, VP of Hardware Engineering
A brief overview of Pete’s work:
- Custom designed chip for Full Self-Driving (FSD).
- <100W Power — Low parts costs i.e., at least 50 Trillion Operations Per Second (TOPS) of neural network performance; batch size =1 to minimize the latency or maximize safety and security.
- Designed the dual redundant FSD Computer, HW 2.5 Computer Assembly, FSD Computer Assembly. These dual redundant chips add significant value to Perception with the help of Radar, GPS, Maps, IMU, Ultrasonic, Wheel Ticks, Steering angle. Then, these redundant systems finally compare and validate.
Leverage Existing Teams at Tesla:
Power Supply Design, Signal Integrity Analysis, Package Design, System Software, Board Design, Firmware, System Validation, etc.
FSD Chip:
Early testing of new FSD hardware shows a 21x improvement in image processing capability with fully redundant computing capability.



Image Signal Processor:

- 1G pixel/sec and 24-bit pipeline: to take full advantage of the HDR sensors that the car provides.
- Advanced Tone Mapping: for details and shadows.
- Advanced Noise Reduction: to improve overall image quality.
Neural Network Processor:

- 32MB SRAM: to hold the temporary results, and minimize the amount of data required to transmit on and off the chip. This, in turn, reduces the Power.
- Other Specs: ReLU Hardware, Pooling Hardware, 36 TOPS at 2 GHz.
- 2 per chip, 72 TOPS total.
Video Encoder:
- H.265 Video Encoder
GPU:
- 1 GHz, 600 GFLOPS, FP32, FP16
Main Processor:
- 12 ARM A72 64b CPUs
- 2.2 GHz
Safety System:
- Lock Step CPU
- Final Drive Control
- Control Validation
Security System:
- Ensure the system only runs code cryptographically signed by Tesla.
Neural Network Accelerator:


Control Energy:
- How much power does it take to execute single instruction?
- 32b Add power is 0.15% of the total power i.e., minimize Control and use all the available Power for Arithmetic.
Compute-Multiply-Add:
There is a total of 9216 multiply adds per clock. For every clock, it reads
- 256b of activation data out of SRAM array.
- 128b of weight data out of SRAM array.
Post-Processing:

Sequential Steps in Post-Processing: After computing the dot product, the engine will be unloaded to shift the data out → Dedicated ReLU Unit → Optional Pooling Unit → Write Buffer → Write Result.
Neural Network Compiler:
- Build and populate the network graph
- Remap functions onto hardware instructions
- Fuse layers (Conv — Scale — ReLU — Pool)
- Smooth layers
- Channel padding to reduce bank conflicts
- DMA insertion
- Code generation
Simple Programming Model:
Running a network, just four stores include
- Set input buffer address
- Set output buffer address
- Set weight buffer address
- Set program address and run control
Results & Comparison (FSD vs HW 2.5):
Power: HW 2.5 = 57W vs FSD = 72W (FSD is still worth because of its efficiency as it runs on neural networks)
Costs: FSD = 0.8x of HW 2.5
Performance (in FPS): FSD = 21x of HW 2.5
TOPS: FSD =144 TOPS vs Drive Xavier = 21 TOPS
Conclusion:
FSD Computer will enable a new level of safety and autonomy in Tesla vehicles without impacting the cost or range.
- Outstanding Performance (144 TOPS)
- Outstanding Power/Performance
- Full redundancy
- Modest cost
Q&A Responses:
- Tesla’s Fleet (i.e., ‘data-gathering cars’ on-road) is its biggest advantage
An analogy: Google Search Engine has a massive advantage over other search engines since it gets better with time as more people effectively program Google with their queries.
- Power Consumption plays a huge role in FSD — most importantly, for the Robo-taxi fleet in cities.
- Recently, the race among the EV competitors has narrowed to the effort to eliminate cobalt, the most expensive metal in the lithium-ion battery. For a brief overview of the numbers and how Tesla has been striving to drive down the cost of its battery packs, please read the article by Steve LeVine.
- Real-world miles >>> Simulation miles: If the simulation really captured the real world, then that would be proof that we are already living in a simulation (which apparently is not the case). The real world is very complex, weird, evolving, and long-tailed with millions of corner cases.
PART 4: Elon Musk on Robo-Taxi and the Future of Self-Driving
In order to have an FSD car or Robo-taxi network, it’s necessary to have the redundancy throughout the vehicle down to the hardware level. Since Oct 2016, all Tesla cars were produced to achieve the Robo-taxi fleet with necessary features. They have redundant hardware including power steering, power, data lines, motor, auxiliary power system.
Future of Full Self-Driving:


It’s similar to a combination of Uber & Airbnb model: You can add or remove your car to the Tesla network with 25–30% of the revenue going to Tesla.

You could summon your car, add or remove your car from the network using your phone via the Ride-Sharing App.
Potential to smooth out the Demand Distribution Curve:

Typically, the use of the car is about 10–12 hours a week. But with autonomous driving and Robo-taxi model, the use of the car might increase to 1/3 of the week i.e., 55–60 hours a week. So, the fundamental utility of the vehicle increases by a factor of 5 which is a massive increase in ‘economic efficiency’.

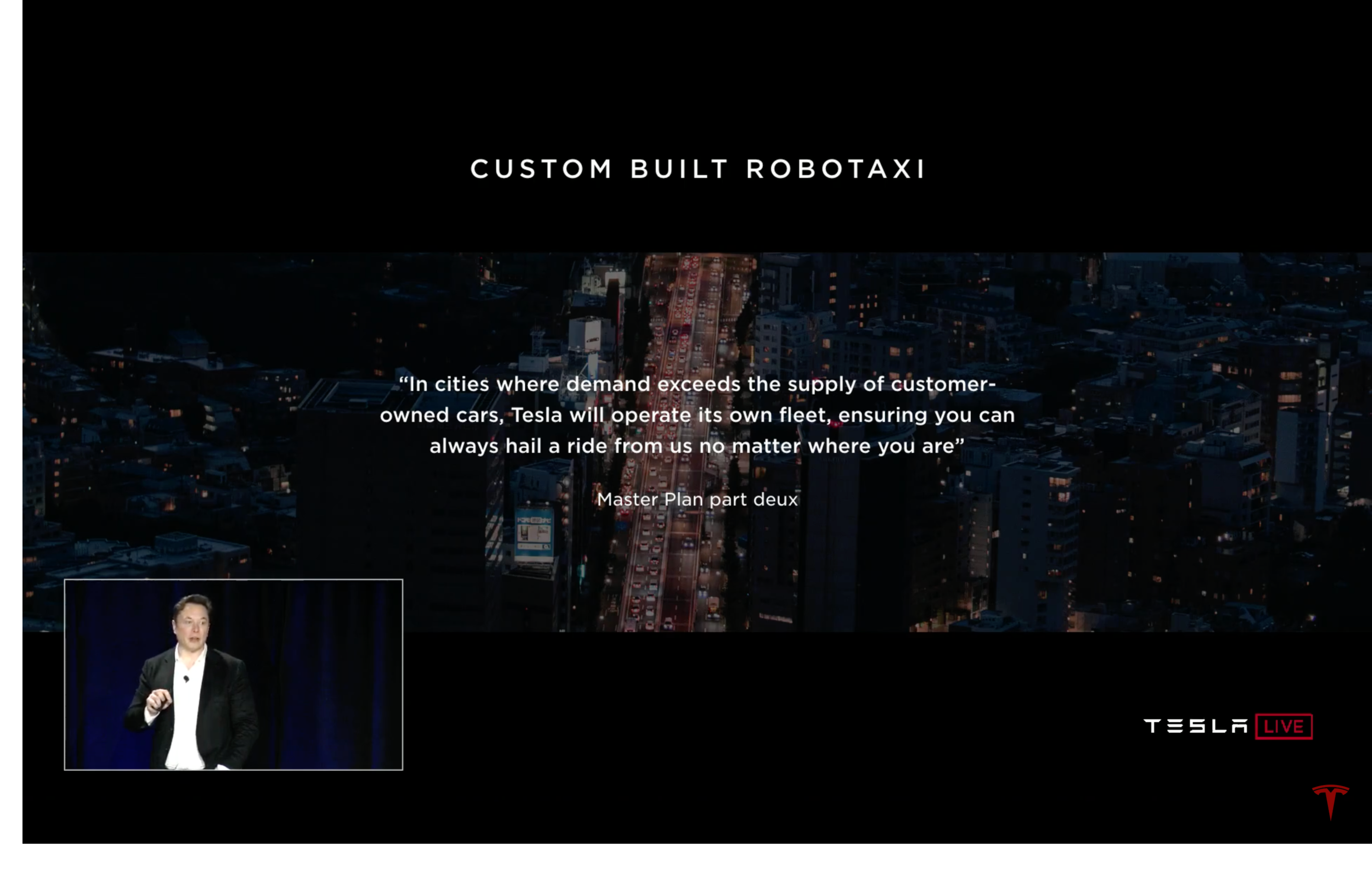


The Robo-taxi is designed with the longevity of million miles of operation and minimum maintenance. The hardware team at Tesla has been optimizing the car for a hyper-efficient Robo-taxi with tire design and eventually getting rid of steering wheels, pedals, and other parts as they become less important at some point in the future.
Cost Model of Robo-Taxi:




The Culture at Tesla and its Optimistic Goals:
Elon is seen as someone who always promises — he may have been optimistic with respect to the timing on some of these things, but he never over-promised on the outcome in most cases.
“This is not me prescribing a point of view about the world, instead it is me predicting what consumers will demand. Consumers will demand, in the future, that people are not allowed to drive these two-ton death machines.”
— Elon Musk on the Future of Autonomy.
Quoting Musk from one of his interviews, “I’d rather be optimistic and wrong than being pessimistic and right” — I personally believe that most of his decisions and promises, with relevance to this quote/belief, are based on context, intuition, and foresight. After having followed the works of SpaceX and Autopilot AI team over the past few years, I am sure that the internal goals of both Tesla and SpaceX are quite optimistic — and, running this belief throughout the culture at Tesla and SpaceX is something that needs to be highly appreciated.
I am curious and looking forward to learning more insights about ‘Dojo’ architecture and how the Robo-Taxi fleet could potentially change the regulatory and insurance business in the years to come.
Further Reading and Videos:
I strongly recommend the following talks/videos to get a grasp of how Andrej and his team have been approaching challenging cases and bottlenecks when developing FSD capabilities:
- PyTorch at Tesla, Andrej Karpathy
- Andrej Karpathy — AI for Full-Self Driving
- Andrej Karpathy: Tesla Autopilot and Multi-Task Learning for Perception and Prediction
- Scalability in Autonomous Driving Workshop U+007C CVPR’20 Keynote U+007C Andrej Karpathy U+007C Tesla
- Building the Software 2.0 Stack (Andrej Karpathy)
- Andrej Karpathy on AI at Tesla (Full Stack Deep Learning — August 2018)
Should you have any inputs that you want to share with me (or) provide me with any relevant feedback on my writing or thoughts, I’d be glad to hear from you. Please feel free to connect with me on Twitter, LinkedIn, or follow me on GitHub.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts


")



