



Handle Missing Data in Pyspark
Last Updated on July 24, 2023 by Editorial Team
Author(s): Vivek Chaudhary
Originally published on Towards AI.
Programming, Python
The objective of this article is to understand various ways to handle missing or null values present in the dataset. A null means an unknown or missing or irrelevant value, but with machine learning or a data science aspect, it becomes essential to deal with nulls efficiently, the reason being an ML engineer can’t afford to get short on the dataset.
Let's check out various ways to handle missing data or Nulls in Spark Dataframe.
Pyspark connection and Application creation
import pyspark
from pyspark.sql import SparkSession
spark= SparkSession.builder.appName(‘NULL_Handling’).getOrCreate()
print(‘NULL_Handling’)
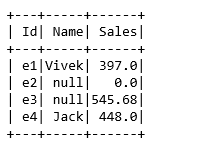
2. Import Dataset
null_df=spark.read.csv(r’D:\python_coding\pyspark_tutorial\Nulls.csv’,header=True,inferSchema=True)
null_df.show()

3. Dropping Null values
#na func to drop rows with null values
#rows having atleast a null value is droppednull_df.na.drop().show()

#rows having nulls greater than 2 are droppednull_df.na.drop(thresh=2).show()
4. Drop Nulls with ‘HOW’ argument
#drop rows having nulls using how parameter
#records having atleast a null wull be droppednull_df.na.drop(how=’any’).show()

#record having all nulls will be droppednull_df.na.drop(how=’all’).show()

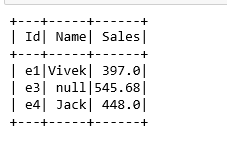
5. Drop Nulls basis of a column
#dropping null values on basis of a column
null_df.na.drop(subset=[‘Sales’]).show()

#records having both Name and Sales as Nulls are droppednull_df.na.drop(how=’all’,subset=[‘Name’,’Sales’]).show()

#records having both Name and Sales as Nulls are droppednull_df.na.drop(how=’any’,subset=[‘Name’,’Sales’]).show()

6. Fill the Nulls
#filling null values into dataset
#spark automatically detects if a column is string or numeric
null_df.na.fill(‘NA’).show()

#fill integer value column
null_df.na.fill(0).show()
7. Filling Nulls on basis of column
#filling on basis of column namenull_df.na.fill(‘Name Missing’,subset=[‘Name’]).show()

#filling multiple column values basis of datatypesnull_df.na.fill({‘Name’: ‘Missing Name’, ‘Sales’: 0}).show()

8. Filling null columns with another column value
#fill null values in Name column with Id valuefrom pyspark.sql.functions import whenname_fill_df=null_df.select('ID','Name',
when( null_df.Name.isNull(), null_df.Id).otherwise(null_df.Name).alias('Name_Filled'),'Sales')name_fill_df.show()

9. Filling nulls with mean or average
#filling numeric column values with the mean or average value of that particular columnfrom pyspark.sql.functions import mean
mean_val=null_df.select(mean(null_df.Sales)).collect()print(type(mean_val)) #mean_val is a list row objectprint('mean value of Sales', mean_val[0][0])
mean_sales=mean_val[0][0]#now using men_sales value to fill the nulls in sales column
null_df.na.fill(mean_sales,subset=['Sales']).show()

Summary:
· Drop null values
· Drop nulls with argument How
· Drop nulls with argument subset
· Fill the null values
· Fill the null column with another column value or with an average value
Hurray, here we have discussed several ways to deal with null values in a Spark data frame.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts

")





