



Getting Started with Apache Kafka — Beginners Tutorial
Last Updated on July 20, 2023 by Editorial Team
Author(s): Vivek Chaudhary
Originally published on Towards AI.
Programming
The objective of this article is to build an understanding of What is Kafka, Why Kafka, Kafka architecture, producer, consumer, broker, and different components of the Kafka ecosystem. And a small coding exercise with Python-Kafka.
1. What is Kafka?
Apache Kafka is a distributed, publish-subscribe based durable messaging system, exchanging data between processes, applications, and servers. In other terms, it is an Enterprise Messaging system that is highly scalable, fault-tolerant, and agile.

Different applications can connect to Kafka systems and push messages/records to the topic. A message/record can be anything from database table records to application events or web server logs. A message or record has a format comprising of a key, a value which is mandatory attributes, and timestamp and header are optional. A topic in simple terms can be understood as a database table that holds records or messages.
2. Kafka Architecture
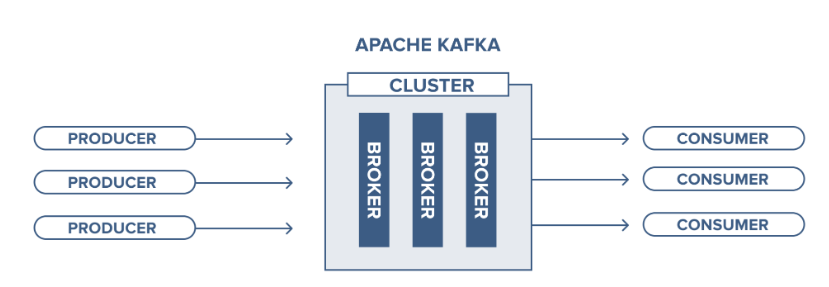
The story of Apache Kafka architecture revolves around four core APIs: Producer, Consumer, Streams, and Connector. A cluster is basically a collection of one or more Kafka servers or brokers as a part of Distributed messaging systems. Let’s understand them in more detail.
Producer API: enables an application to connect to Kafka Brokers and publish a stream of records or messages to one or more Kafka topics.
Consumer API: enables an application to connect to Kafka Brokers and consume a stream of records or messages from one or more Kafka topics.
Streams API: enables applications to consume an input stream from one or more topics and produces an output stream for one or more topics, thus allowing the transformation of input and output streams.
Connector API: allows writing reusable consumer and producer code, e.g., read data from the database and publish to Kafka topic and consume data from Kafka topic and write to the database.
What is a Broker?
A Broker is an instance or a single server of a Kafka cluster. Kafka Broker stores the messages on the topic or topics. The broker instance that we connect to in order to access the messages or records is known as the bootstrap server. A cluster can have 100s of brokers.
What is Zookeeper?
A Zookeeper can be understood as a Resource Management part of the whole ecosystem. It keeps the metadata about the processes running in the system, performs health check and broker leader selection, etc.
What is a Topic?
The topic is the structure that holds the messages or the records published to the Kafka broker. Internally a topic is divided into partitions, the place exactly where data is published. These partitions are distributed across the brokers in the cluster. A topic is identified by a name just like a table in the database. Atopic is partitioned. Each partition of a topic will have a leader that will lead the read/write operations.

That’s all about the theory part of Kafka, and there are other concepts involved as well that we will cover in upcoming blogs.
3. Use Case and Coding:
With the help of a very basic Python code, we will publish some messages in key-value pair format to Kafka Broker and consume those messages from the broker. But before that, there are some services that need to be up and running to access the Kafka cluster.
Step1: Start the Zookeeper
D:\Kafka_setup\kafka_2.12–2.5.0\bin\windows\zookeeper-server-start.bat D:\Kafka_setup\kafka_2.12–2.5.0\config\zookeeper.properties
Step2: Start the Kafka Broker
D:\Kafka_setup\kafka_2.12–2.5.0\bin\windows\kafka-server-start.bat D:\Kafka_setup\kafka_2.12–2.5.0\config\server.properties
Step3: Create a topic
D:\Kafka_setup\kafka_2.12–2.5.0\bin\windows\kafka-topics.bat — zookeeper localhost:2181 — create — topic demo1 — partitions 2 — replication-factor 2
I have created a topic with two partitions with a replication factor of 2. In this case, as the cluster has more than two brokers, the partitions are evenly distributed, and the replicas of each partition are replicated over to another broker. As the replication factor is 2, there is no data loss, even if a broker goes down. To achieve resilience, the replication factor should be greater than one and less than the number of brokers in the cluster.
Step4: Start Consumer console
D:\Kafka_setup\kafka_2.12–2.5.0\bin\windows\kafka-console-consumer.bat — bootstrap-server localhost:9092 —-topic demo1
Step5: Run Producer code to push messages to Kafka Broker
#producer.py
from json import dumps
import json
from kafka import KafkaProducerproducer = KafkaProducer(bootstrap_servers=['localhost:9092'],
value_serializer=lambda x:json.dumps(x).encode('utf-8'))try:
for num in range(1,5):
msg={'num': num}
producer.send('demo1',value=msg)
producer.send('demo1', {'name': 'vivek'})
producer.send('demo1', {'name': 'vishakha'})
except Exception as e:
print(e)print('Message sent to kafka demo1')
Step6: Check messages on Consumer console

Step7: Run consumer code to subscribe to messages
#consumer.py
from kafka import KafkaConsumer
from json import loads
import jsonconsumer = KafkaConsumer(‘demo1’,
bootstrap_servers=[‘localhost:9092’],
auto_offset_reset=’earliest’,
enable_auto_commit=True,
group_id=’my-group’,
value_deserializer=lambda x: loads(x.decode(‘utf-8’)))for message in consumer:
msg = message.value
print(msg)
consumer.close()#subscribed messages:
{"num": 1}
{"num": 2}
{"num": 3}
{"num": 4}
{"name": "vivek"}
{"name": "vishakha"}
Let’s understand about the properties we have used in producer and consumer code:
bootstrap_servers: sets the host and port the producer should contact to bootstrap initial cluster metadata. It is not necessary to set this here since the default is localhost:9092.
value_serializer: the function of how the data should be serialized before sending it to the broker. Here, we convert the data to a JSON file and encode it to utf-8.
enable_auto_commit: makes sure the consumer commits its read to offset every interval.
auto_offset_reset: one of the most important arguments. It handles where the consumer restarts reading after breaking down or being turned off and can be set either to the earliest or latest. When set to the latest, the consumer starts reading at the end of the log. When set to earliest, the consumer starts reading at the latest committed offset, and that’s exactly what we want in this case.
value_deserializer: performed at the consumer end, is the reverse operation of serialization and converts the data from a byte array into JSON format.
Hurray, we learned some basics about Apache Kafka messaging systems. This blog can be helpful in building a basic understanding of Kafka systems and how the producer/consumer code looks like.
Summary:
· Kafka based distributed pub-sub messaging system.
· Kafka architecture and different components.
· Kafka concepts such as producer, consumer, broker, topic, partition, zookeeper, etc.
· Services related to the Kafka ecosystem.
· Topic creation, partition, and replication factor.
· Simple coding exercise, producer, and consumer in python language.
Thanks to all for reading my blog, and If you like my content and explanation, please follow me on medium and share your feedback, which will always help all of us to enhance our knowledge.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Related posts


Popular posts

 for 2021")



Updates

Recent Posts



