
 Logo:
Logo:  Areas Served:
Areas Served: 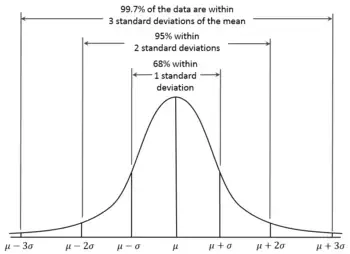
Feature Scaling with Python’s Scikit-learn
Last Updated on July 24, 2023 by Editorial Team
Author(s): Bindhu Balu
Originally published on Towards AI.
Top highlight
One of the primary objectives of normalization is to bring the data close to zero. That makes the optimization problem more “numerically stable”.
Now, the scaling using mean and standard deviation assumes that the data is normally distributed, that is, most of the data is sufficiently close to the mean. So shifting the mean to zero ensures that most components of most data points are close to 0. Specifically, 68% of data would be between -1 and 1, as can be seen from the following figure:
In this post we explore 3 methods of feature scaling that are implemented in scikit-learn:
StandardScalerMinMaxScalerRobustScalerNormalizer
The… Read the full blog for free on Medium.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Related posts
Popular posts

 for 2021")



Updates

Recent Posts



