



Exploring The Last Trends of Random Forest
Last Updated on December 11, 2020 by Editorial Team
Author(s): Barak Or
The random forest model is considered one of the promising ML ensemble models that recently became highly popular. In this post, we review the last trends of the random forest.
Ensemble Models-Intro
An ensemble considers multiple learning models and combines them to obtain a more powerful model. Combining different models into an ensemble leads to a better generalization of the data, minimizing the chance for overfitting. A random forest is an example of an ensemble model, where multiple decision trees are considered. As this post is related to the last trends of random forest, it is assumed the reader has a background on decision trees (if no, please refer to decision-trees-in-machine-learning, a great post by Prashant Gupta).
Random Forest-Background
The random forest was introduced by Leo Breiman [1] in 2001. The motivation lies in the key disadvantage of a decision tree model, where it is prone to overfitting while many leaves are created. Hence, many decision trees lead to a more stabilized model with better generalization. The random forest idea is to create lots of decision trees, where each one should predict reasonably well the target values but look different from the other trees. The “different” creation is done by adding random variations during the tree building process. These variations include the variety in the selected data of the trained model, and the features at each split test are selected randomly. Generally, the random forest process can be described as follows:

The main tuning parameters the design should set can be summarized as follows:
- The number of trees (estimators) to use in the ensemble model.
- The maximum features parameters. Influence mainly on the diversity of trees in the ensemble model. Strongly affect performance.
- Maximum tree-depth. This parameter is important to avoid overfitting.
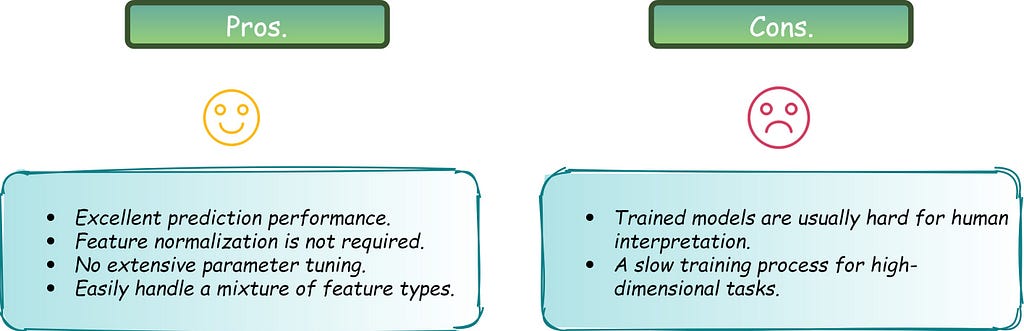
The pros and cons of random forest are summarized here:
A great example of using random forest is given here: an-implementation-and-explanation-of-the-random-forest-in-python-77bf308a9b76 by Arya Murali.
Learning From Weak-Label Data: A Deep Forest Expedition
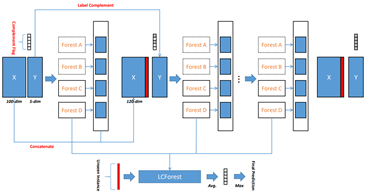
The weak label is the case where each training example is associated with multiple (true) labels simultaneously, but only part of them is provided. Recently, a paper by Wang et al. [2] suggested dealing with weak-label data by applying a deep forest expedition model. They introduced the “LCForset method” with the label complement structure:
The main contribution is the tree ensemble-based deep learning method (for a weak-label) training. Mostly, these kinds of problems are formulated as a regularized framework. In their work, they process the information layer by layer and are able to achieve an efficient label complement structure. Their general scheme is given in the figure below, where the data is used to train two completely random forests and two random forests in each layer. Then, for every training example, the feature vector is concatenated. The process continues until reaching the maximum layer T.
The method was demonstrated/tested on image and sequential data (medical NLP task) with great results.
Abstract Interpretation of Decision Tree Ensemble Classifiers
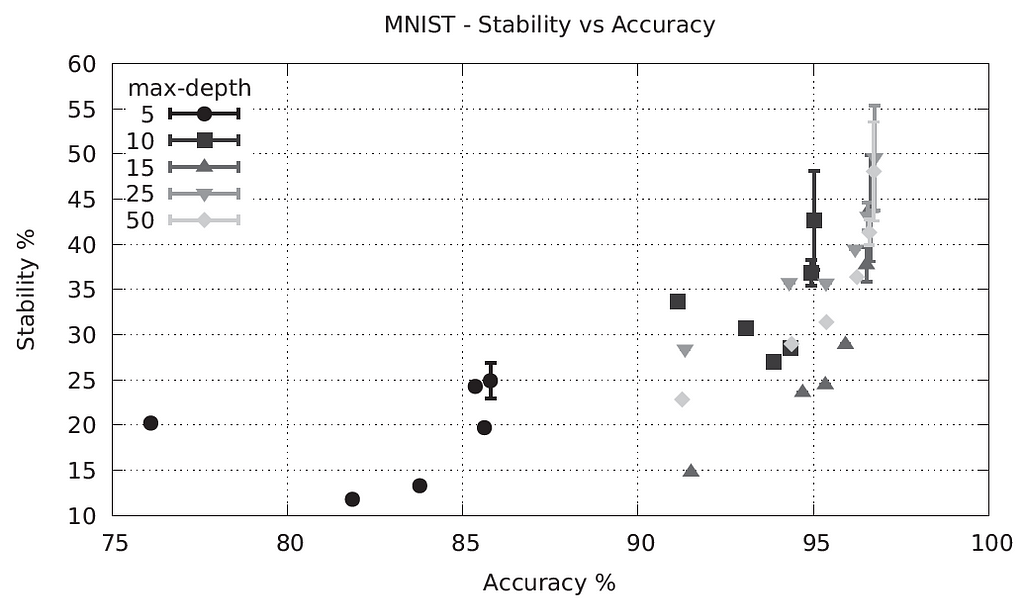
The problem of random forest robustness verification is of high importance. There is a clear need to interpret the trained model and provide some verification tools. Recently, Ranzato et al. [3] studied this problem with a general and principle abstract interpretation-based framework for formal stability and robustness properties of random forests. Their method includes robustness checks for standard adversarial perturbations. They evaluated their tool with the MNIST dataset and provided an efficient tool for random forest verification. The following chart describes the relationship between the stability and accuracy of different (max) depths.
Proving Data-Poisoning Robustness in Decision Trees
In many machine learning models, a small change in the training data might heavily affect the result prediction. Recently, Drews et al. [4] studied this problem in the context of an attack, where an attacker can affect the model by injecting a number of malicious. They presented their results by decision tree models that were largely used in the random forest algorithm. A novel tool, “Antidote”, was presented for verifying the data-poising robustness of decision tree learners. Their approach is summarized in the figure below.
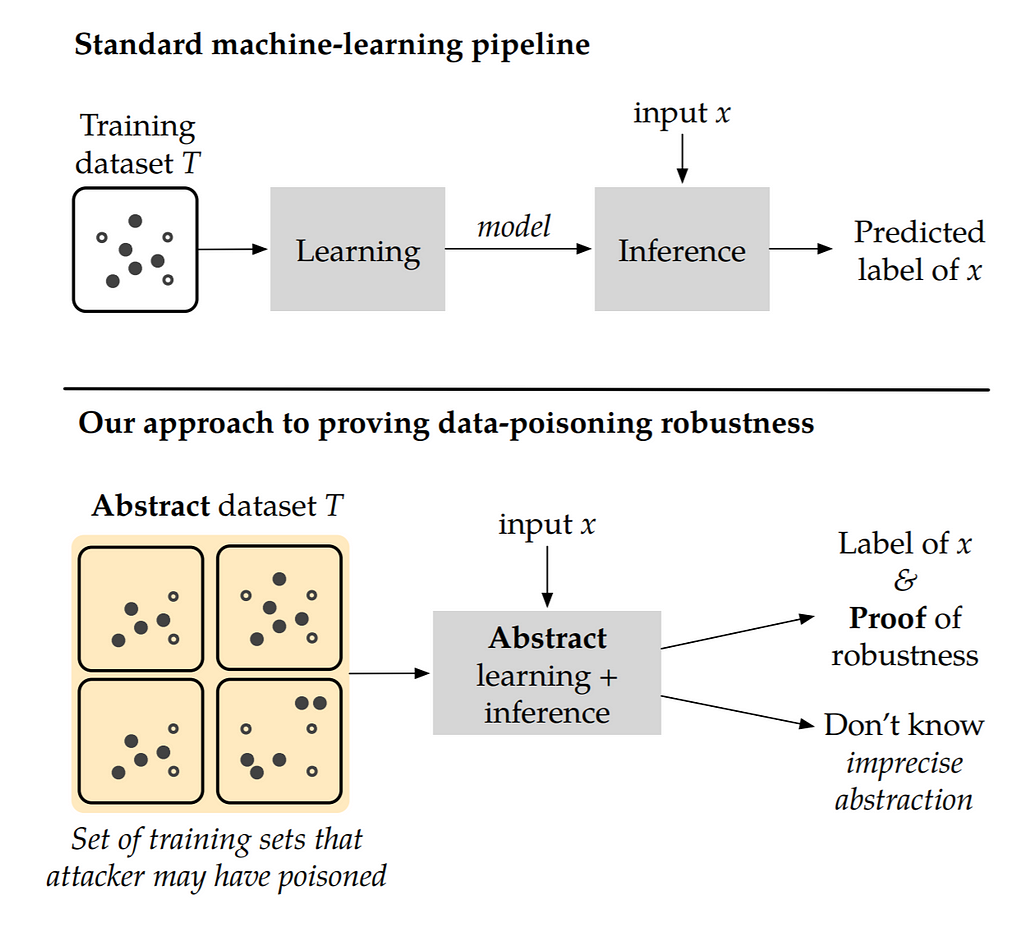
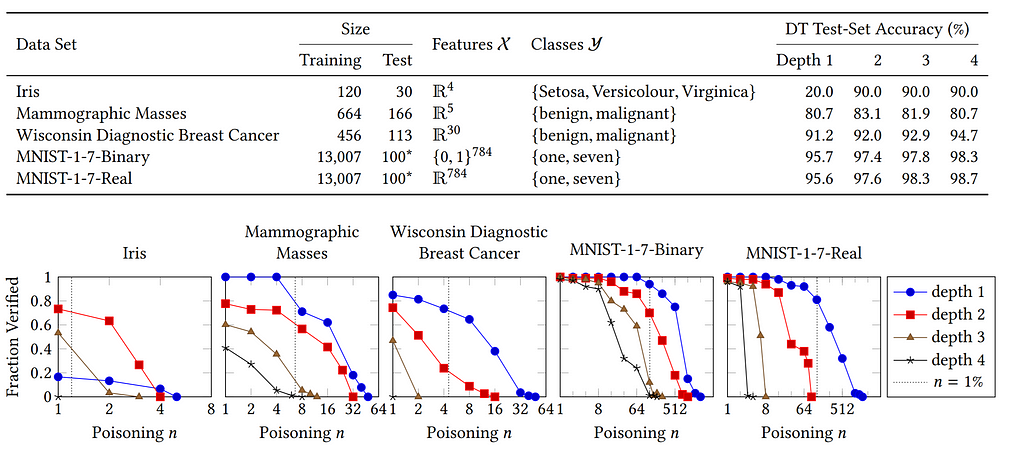
They evaluated their model on many data sets with the provided results below, where a fraction of test instances proven robust versus poisoning parameter n is presented.
Scalable and Generalizable Social Bot Detection through Data Selection
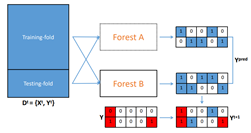
Social bots are widely used. Efficient and reliable social bot classification is highly important for detecting information manipulation on social media. Recently, Yang et al. [5] proposed a framework that uses minimal account metadata, enabling efficient analysis that scales up to handle the full stream of public tweets of Twitter in real-time. They found that strategically selecting a subset of training data yields better model accuracy and generalization than exhaustively training on all available data. The generability of the social bot was achieved by using a random forest with 5-fold cross-validation:
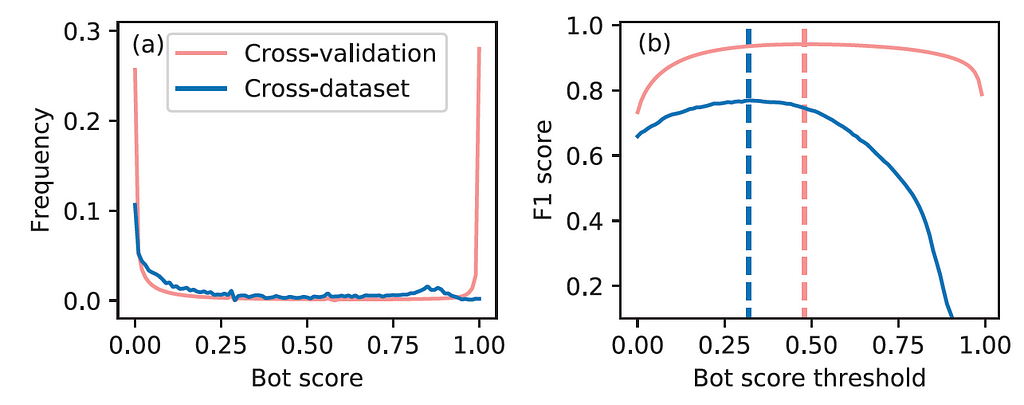
As the random forest generates a score between 0 and 1, thresholds that maximize precision and recall (via the F1 metric) are obtained for cross-validation or cross-domain testing. Hence, the choice of the threshold depends on the holdout datasets used for validation.
Heterogeneous Oblique Random Forest
Using random forests involves decision trees with a single feature in the nodes to split the data. This splitting may fail to exploit the inner structure of data (geometric structure, for example), as axis-parallel decision boundaries are involved. Katuwal et al. [6] recently presented the heterogenous oblique random forest, where an oblique hyperplane is employed instead of an axis-parallel hyperplane. Trees with such hyperplanes can better exploit the geometric structure to increase the accuracy of the trees and reduce the depth.
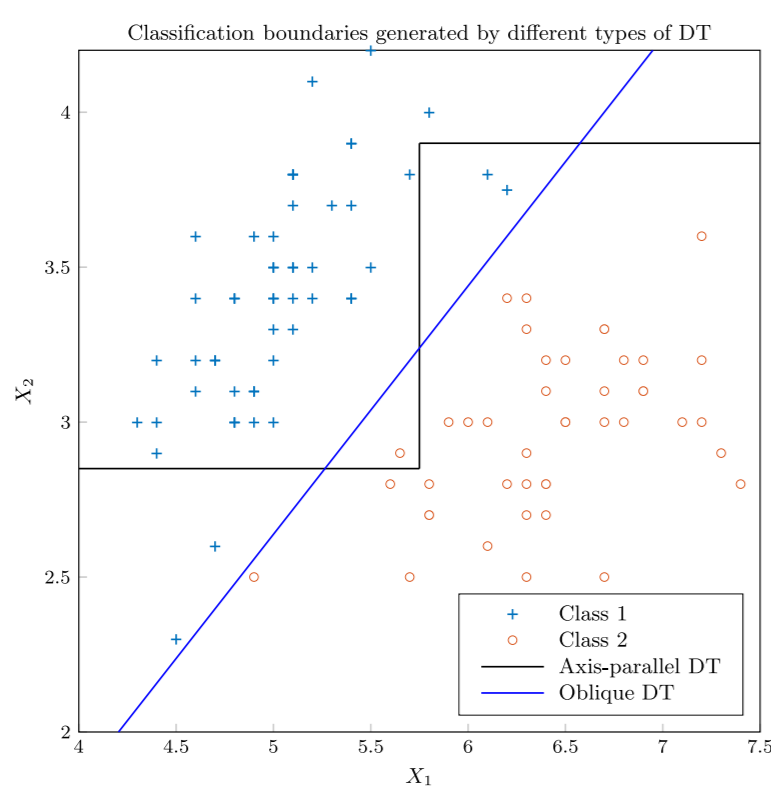
Their method includes several linear classifiers at the internal nodes of the tree, getting the K hyper-classes-based partitions, all creating K on-vs-all partitions.
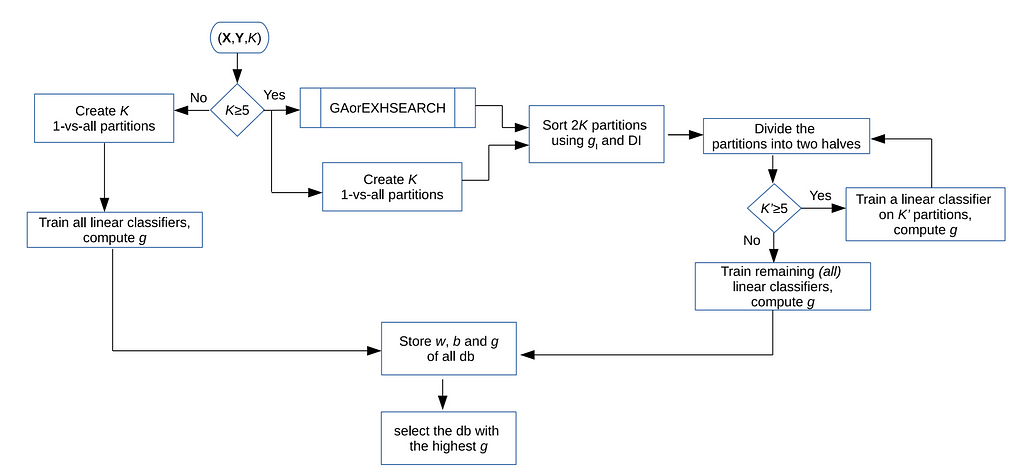
They checked their approach against several models on many known databases and obtained higher mean accuracy.
Deterministic Dropout for Deep Neural Networks Using Composite Random Forest
The following work is from the deep learning domain, where the random forest models were adapted to improve the dropout technique. Santra et al. [7] propose a method that deterministically identifies and terminates the unimportant connections in a neural network (dropout). The random forest algorithm was used for finding the unimportant connections, where it resulted in better accuracy for the MNIST dataset:
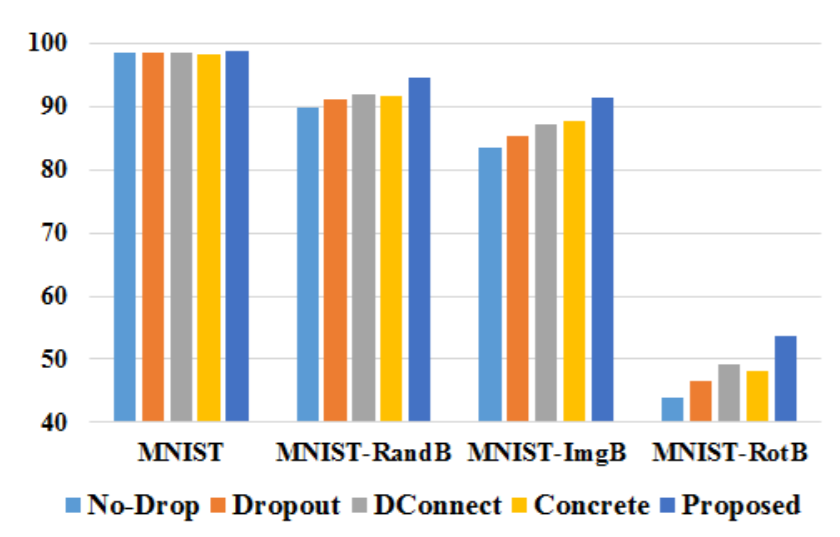
Their method flowchart is given by:
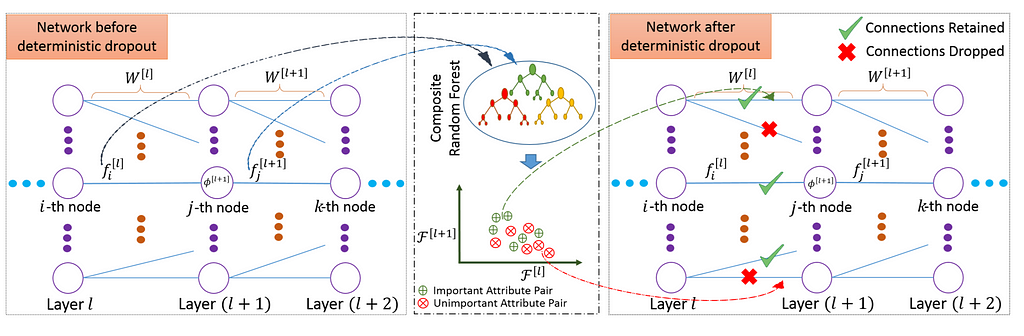
where generally, the various steps include finding the two fully-connected layers to perform dropout, building a feature vector at the output of the two layers (by that crating a composite feature vector), and finding the unimportant composite features to drop them out.
COVID-19 Patient Health Prediction Using Boosted Random Forest Algorithm
Lastly, the random forest’s high popularity leads it to be used also in COVID-19 prediction. Iwendi et-al [8] proposed a fine-tuned Random Forest model boosted by the AdaBoost algorithm. Their suggested model uses many COVID-19 features and has an accuracy of 94% and an F1 Score of 0.86 on their used dataset.
Conclusion
In this post, we explored the latest works in the field of random forest. The random forest became very popular recently, where many publications have appeared as also practical-industrial uses. Model stability and complexity seem to be of high importance, where the main research ways include dropout techniques and stability constraints. Also, integration with deep learning seems frequent for advanced models.
— — — — — — — — — — — — — — — — — —
About the Author
Barak Or received the B.Sc. (2016), M.Sc. (2018) degrees in aerospace engineering, and also B.A. in economics and management (2016, Cum Laude) from the Technion, Israel Institute of Technology. He was with Qualcomm (2019–2020), where he mainly dealt with Machine Learning and Signal Processing algorithms. Barak currently studies toward his Ph.D. at the University of Haifa. His research interest includes sensor fusion, navigation, machine learning, and estimation theory.
www.Barakor.com | https://www.linkedin.com/in/barakor/
— — — — — — — — — — — — — — — — -
References
[1] Breiman, Leo. “Random forests.” Machine learning 45.1 (2001): 5–32.
[2] Wang, Qian-Wei, Liang Yang, and Yu-Feng Li. “Learning from Weak-Label Data: A Deep Forest Expedition.” AAAI. 2020.
[3] Ranzato, Francesco, and Marco Zanella. “Abstract interpretation of decision tree ensemble classifiers.” Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 34. №04. 2020.
[4] Drews, Samuel, Aws Albarghouthi, and Loris D’Antoni. “Proving data-poisoning robustness in decision trees.” Proceedings of the 41st ACM SIGPLAN Conference on Programming Language Design and Implementation. 2020.
[5] Yang, Kai-Cheng, et al. “Scalable and generalizable social bot detection through data selection.” Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 34. №01. 2020.
[6] Katuwal, Rakesh, Ponnuthurai Nagaratnam Suganthan, and Le Zhang. “Heterogeneous oblique random forest.” Pattern Recognition 99 (2020): 107078.
[7] Santra, Bikash, Angshuman Paul, and Dipti Prasad Mukherjee. “Deterministic dropout for deep neural networks using composite random forest.” Pattern Recognition Letters 131 (2020): 205–212.
[8] Iwendi, Celestine, et al. “COVID-19 Patient health prediction using boosted random forest algorithm.” Frontiers in public health 8 (2020): 357.
Exploring The Last Trends of Random Forest was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts
")



")


