



Data Acquisition & Exploration: Exploring 5 Key MLOps Questions using AWS SageMaker
Last Updated on June 28, 2023 by Editorial Team
Author(s): Anirudh Mehta
Originally published on Towards AI.
The ’31 Questions that Shape Fortune 500 ML Strategy’ highlighted key questions to assess the maturity of an ML system.
A robust ML platform offers managed solutions to easily address these aspects. In this blog, I will walk through AWS SageMaker's capabilities in addressing these questions.
What?
An MLOps workflow consists of a series of steps from data acquisition and feature engineering to training and deployment. As such, instead of covering all aspects in a single blog, we will focus on key questions surrounding Data Acquisition & Exploration (EDA).
▢ [Automation] Does the existing platform helps the data scientist to quickly analyze, visualize the data and automatically detect common issues
▢ [Automation] Does the existing platform allows integrating and visualizing the relationship between datasets from multiple sources?
▢ [Collaboration] How can multiple data scientists collaborate in real-time on the same dataset?
▢ [Reproducibility] How do you track and manage different versions of acquired datasets
▢ [Governance & Compliance] How do you ensure that the data privacy or security considerations have been addressed during the acquisition
Use Case & Dataset
The questions can be best answered in a context of a use case. For this series, we will consider “Fraud Detection” as a use case with very simple rules:
- Any transaction above 500 amount is considered fraud
- Any transaction outside the user’s billing address is considered fraud
- Any transaction outside the normal hours is considered fraud
The following script generates customer & transaction datasets with occasional fraudulent events.
# Script to generate the transactions dataset
import numpy as np
import pandas as pd
from datetime import datetime, timedelta
import random
np.random.seed(123)
# Define count for the sample dataset
n_customers = 10
n_transactions = 100000
# Define dictionary for sample dataset
states = ['CA', 'NY', 'TX']
cities = ['Los Angeles', 'New York', 'Dallas']
streets = ["Main St", "Oak St", "Pine St", "Maple Ave", "Elm St", "Cedar St"]
zips = [10001, 10002, 90001, 90002, 33101, 33102, 75201, 75202, 60601, 60602]
# Generate customers
customer_df = pd.DataFrame({
'customer_id': range(n_customers),
'state': np.random.choice(states, n_customers),
'city': np.random.choice(cities, n_customers),
'street': np.random.choice(streets, n_customers),
'zip': np.random.choice(zips, n_customers)
})
customer_states = dict(zip(customer_df['customer_id'], customer_df["state"]))
# Generate transactions
transaction_df = pd.DataFrame({
'transaction_id': np.random.choice([random.randint(100000000, 999999999) for i in range(1000)], n_transactions),
'customer_id': np.random.choice(range(n_customers), n_transactions),
'amount': [random.uniform(0, 500) if random.random() < 0.9 else random.randint(500, 1000) for i in range(n_transactions)],
'transaction_time': np.random.choice([datetime(2023, 4, 25, 22, 15, 16) - timedelta(days=random.randint(0, 30), hours=random.randint(0, 12), minutes=random.randint(0, 60)) for i in range(n_transactions)], n_transactions)
})
# Set transaction state to customer state
transaction_df['transaction_state'] = [customer_states[x] if random.random() < 0.9 else np.random.choice(states) for x in transaction_df['customer_id']]
# Mark transaction as fraud if an outlier
transaction_df['fraud'] = transaction_df.apply(lambda x: random.random() < 0.1 or x['amount'] > 500 or x['transaction_time'].hour < 10 or x['transaction_time'].hour > 22 or x['transaction_state'] != customer_states[x['customer_id']], axis=1)
print(f"Not fraud: {str(transaction_df['fraud'].value_counts()[0])} \nFraud: {str(transaction_df['fraud'].value_counts()[1])}")
customer_df.to_csv("customers.csv", index=False)
transaction_df.to_csv("transactions.csv", index=False)
For real-world data, you can refer Kaggle Credit Card Fraud Dataset.
U+1F4A1 AWS offers a fully managed service for customized fraud detection — Amazon Fraud Detector.
How?
I have tried to structure the article to be easily readable. However, to truly understand SageMaker’s capabilities, I highly recommend taking a hands-on approach.
For this series, I will be using SageMaker Studio, a fully managed ML & MLOps IDE. AWS also offers SageMaker Studio Lab, a free Jupyter-based IDE environment.
U+1F4A1 AWS SageMaker is offered as part of the free tier for the first 2 months with various sub-limits. I will include the sub-limits where applicable.
Organize with SageMaker Domain
[U+2713] [Governance & Compliance] How do you ensure that the data privacy or security considerations have been addressed during the acquisition
In an enterprise, multiple models are often developed simultaneously. These models are based on different datasets and algorithms and are often managed by different teams. Effective organization and controlled access are critical for efficient management, as well as ensuring overall data privacy and security.
SageMaker provides the concept of domains to organize ML resources such as notebooks, experiments, and models, and to manage access to them.
Create a domain
Creating a domain in Amazon SageMaker is a quick and straightforward process. The console offers two workflows: Quick Setup (1 min) and Standard Setup (10 min). The latter allows for additional security configurations, such as authentication, encryption, and VPC configuration.

Manage access – User profiles
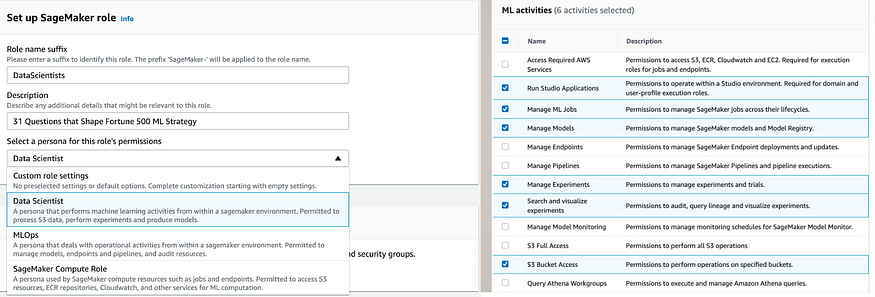
Amazon SageMaker allows the creation of different profiles based on either custom or predefined personas, such as data scientists, MLOps engineers, or compute.
These profiles enable an organization to effectively manage permissions & govern access across the platform:
- Control access to resources such as the SageMaker canvas or a particular bucket.
- Control user activities like creating ML jobs or publishing models.
Explore with SageMaker Data Wrangler
[U+2713] [Automation] Does the existing platform helps the data scientist to quickly analyze, visualize the data and automatically detect common issues?
In any data science exercise, the first step is to make sense of the data and identify correlations, patterns, and outliers. The success of a model depends on the quality of the dataset, making this a crucial step.
SageMaker Data Wrangler simplifies and accelerates this process.
U+26A0️ ㅤThe Data Wrangler’s free tier provides only 25 hours of ml.m5.4xlarge instances per month for 2 months. Additionally, there are associated costs for reading and writing to S3.
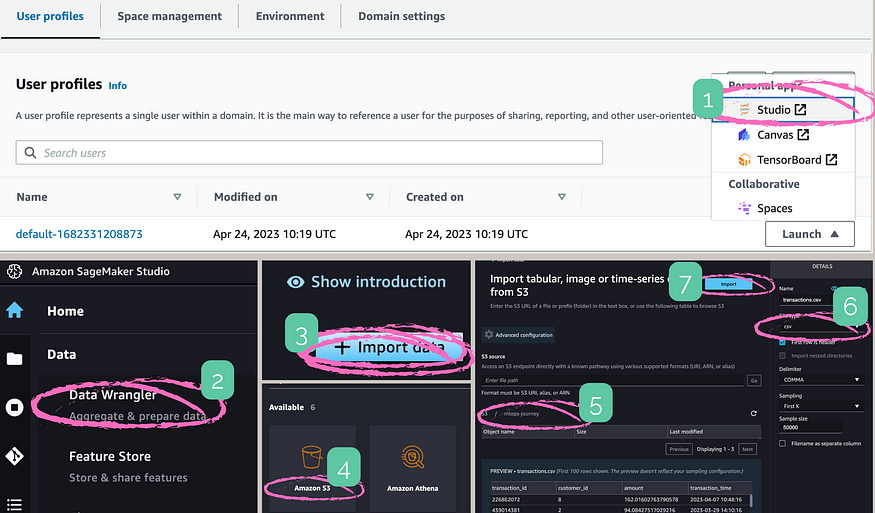
Importing the data
Data Wrangler supports importing data from various sources, such as Amazon S3, Redshift, Snowflake, and more. For this article, I have already uploaded the customer and transaction datasets generated previously to Amazon S3. I have also granted SageMaker’s user profile access to this bucket.
Automated Analysis
Out of the box, Data Wrangler automatically identifies the data types of various columns within the uploaded data. Additionally, Data Wrangler offers built-in capabilities such as data quality and insights reports.
Let’s run it against our target column – “fraud”, and review the insights it automatically generates.

- Dataset Statistics: Statistical summaries of the dataset — feature count, count of valid and invalid records, and feature type distribution. It found 6 features and no duplicate or invalid records.
- Target Column Distribution: Understand any imbalances in the dataset.
- Feature Summary: Predictive power of individual features. As expected, the features — amount, time, and state play the most important role.
- Feature Distribution: Distribution of individual features w.r.t the target label.
- Quick Model: Predicts how good a trained model on this dataset might be.
- Confusion Matrix: Performance of the quick model to detect fraud or not.
[U+2713] [Automation] Does the existing platform allows integrating and visualizing the relationship between datasets from multiple sources?
SageMaker Wrangler enables data scientists to quickly join two datasets and visualize them together. In this particular case, we are joining customer data with transaction data. Once joined, data scientists can run the automated analysis of the combined data in a similar manner.
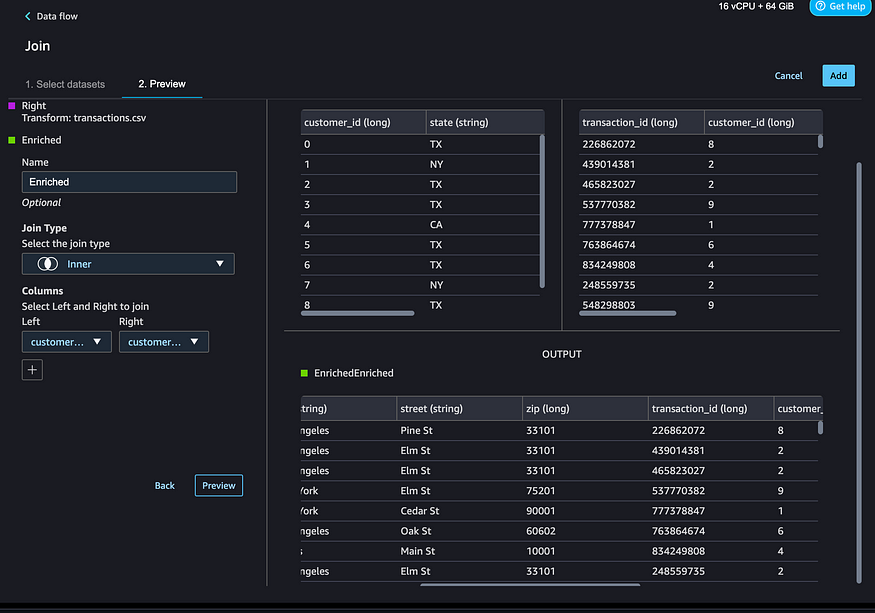
We will explore this further in the next blog on “Data Transformation and Feature Engineering”.
Collaborate with SageMaker Spaces
[U+2713] [Collaboration] How can multiple data scientists collaborate in real-time on the same dataset?
SageMaker Spaces enables users within a domain to collaborate and access the same resources, including notebooks, files, experiments, and models. It allows multiple users to access, edit and review the same notebooks in real time within a shared studio application.


Track with SageMaker Lineage & DVC
[U+2713] [Reproducibility] How do you track and manage different versions of acquired datasets
Version control is a well-known concept in the coding and development world, but it is also essential for data science activities.
DVC (Data Version Control) is a popular open-source tool designed for the same purpose. It allows you to track and manage versions of your datasets, features, and models.
DVC integrates with Git and allows data scientists to store and track references to the data stored in various locations such as Amazon S3, HTTP, or on disk.
# Register S3 remote
dvc remote add -d myremote s3://<bucket>/<optional_key>
# Track file
# This creates ".dvc" file with information necessary for tracking
dvc add data/raw.csv
git add training.csv.dvc # Version control ".dvc" file like any other git file
# Push data file to S3
dvc push
# Pull data files from S3
dvc pull
# Switch between versions
dvc checkout
[U+2713] [Governance & Compliance] How do you ensure that the data privacy or security considerations have been addressed during the acquisition (cont..)
DVC enables you to track data set versions. However, we may need to track additional information for governance and understanding the usage:
- Where did the raw data originate from?
- Who owns or manages the raw data?
- What transformations and preprocessing are being applied to the raw data?
- What models use a data set?
SageMaker Lineage is capable of providing answers to several of these questions. We will explore this further in the next blog on “Data Transformation and Feature Engineering”.
Here’s a quick example of creating a raw data artifact entity capturing source, origin, and owner information.
# Create a artifact
aws sagemaker create-artifact
--artifact-name raw-data
--source SourceUri=s3://my_bucket/training.csv
--artifact-type raw-data
--properties owner=anirudh,topic=mlops,orgin=script # Additional details
--tags Key=cost_center,Value=research
{
"ArtifactArn": "arn:aws:sagemaker:us-east-1:removed:artifact/24c7ff167309de3b466aab30f95a8810"
}
# Describe a artifact
aws sagemaker decribe-artifact --artifact-arn arn:aws:sagemaker:us-east-1:removed:artifact/24c7ff167309de3b466aab30f95a8810
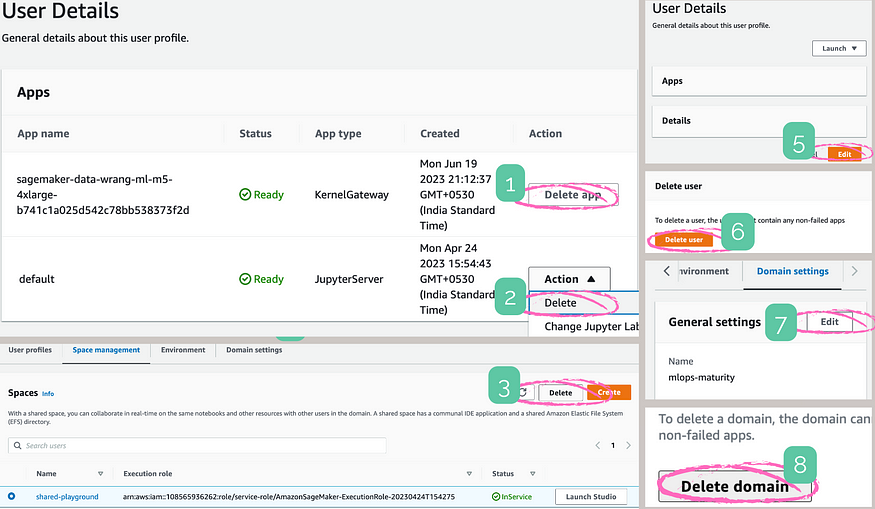
U+26A0️ Clean-up
If you have been following along with the hands-on exercises, make sure to clean up to avoid charges.
In summary, AWS SageMaker Wrangler greatly accelerates the complex tasks of data exploration for data scientists.
In the next article, I will explore how SageMaker can assist with Data Transformation and Feature Engineering.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Related posts


Popular posts

 for 2021")



Updates

Recent Posts



