



Contributing a New Large Dataset for SARS-CoV-2 Identification via CT Scan
Last Updated on May 23, 2020 by Editorial Team
Author(s): Eduardo Soares and Plamen Angelov
An open-source dataset for the development of artificial intelligent methods able to identify patients infected by SARS-CoV-2 through computed tomography scan analysis
You can find the dataset on Kaggle. For the detailed paper, please visit medRxiv.
In December 2019, an outbreak coronavirus (SARS-CoV-2) infection began in
Wuhan, the capital of central China’s Hubei province. On Jan 30, 2020, the World Health Organization (WHO) declared a global health emergency. By May 9, 2020, over 4 million officially confirmed cases were reported in practically every corner of the Earth, with 275,976 officially reported deaths documented.
Researchers of different disciplines work along with public health officials to understand the COVID-19 pathogenesis and jointly with the policymakers urgently develop strategies to control the spread of this new disease. Recent findings have observed imaging patterns on chest radiography and computed tomography (CT) for patients diagnosed with COVID-19.
The prospective analysis revealed bilateral lung opacities on 40 of 41 (98\%) chest CTs in infected patients in Wuhan and described lobular and subsegmental areas of consolidation as the most typical findings. Other investigators found high rates of ground-glass opacities and consolidation, sometimes with a rounded morphology and peripheral lung distribution. Thoracic radiology evaluation is often key to the evaluation of patients suspected of COVID-19 infection. Prompt detection and diagnosis of the disease are invaluable in the efforts to ensure timely treatment. From a public health perspective, rapid patient isolation is crucial for the containment of this communicable disease and optimal use of available resources, which quickly become scarce and overwhelmed by the exponentially growing number of patients and prolonged periods of treatment.
To encourage the research and development of artificial intelligent (AI) methods, which are able to identify if a person is infected by SARS-CoV-2 through the analysis of CT scans. We make public a new large dataset for SARS-CoV-2 identification via CT scans. The presented dataset is composed of 2482 CT scans, which 1252 corresponds to 60 patients identified with SARS-CoV-2, and 1230 CT scans correspond to 60 patients not identified with the disease. These data have been collected from public hospitals of São Paulo — Brazil from Mar 15 to Apr 15, 2020.
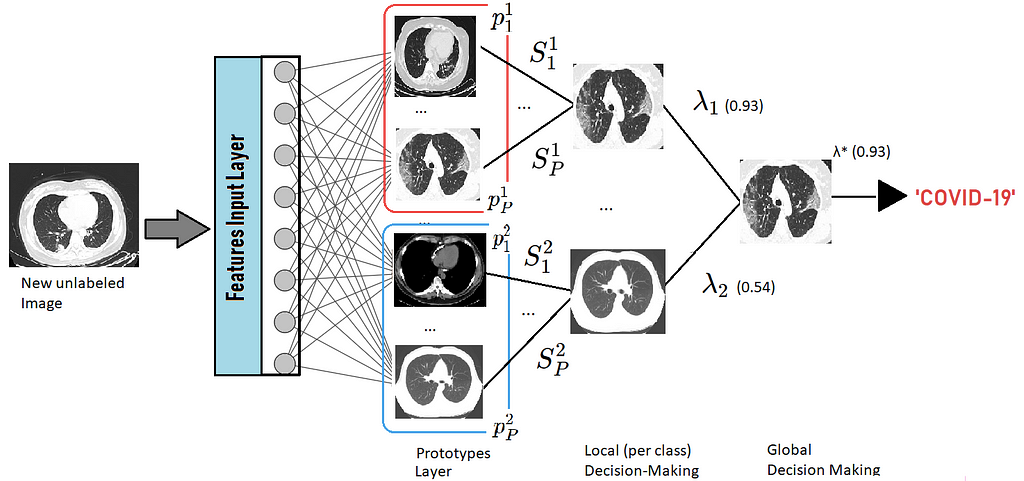
Moreover, we tested the proposed data set has been tested with different state-of-the-art methods. The xDNN classifier demonstrated the best results in terms of performance than other state-of-the-art approaches, presenting an F1 score of 97.31% for the best case. The xDNN classifier is non-iterative and non-parametric, which explains its efficiency in terms of time and computational resources. From the user perspective, the proposed approach is clearly understandable/explainable, which for the specific case of COVID-19 infections means to aid explanations and decisions made ultimately by human doctors (instead of percentages and likelihoods they can see and understand an image and compare similarities). In this sense, this is an approach of anthropomorphic machine learning. For more information about the dataset, please visit Kaggle.
For more information about the xDNN code, please visit our GitHub repository.
For the original research paper, please visit medRxiv:
When used in academic settings, please cite:
Soares, Eduardo, Angelov, Plamen, Biaso, Sarah, Higa Froes, Michele, and Kanda Abe, Daniel. “SARS-CoV-2 CT-scan dataset: A large dataset of real patients CT scans for SARS-CoV-2 identification.” medRxiv (2020). DOI: https://doi.org/10.1101/2020.04.24.20078584.
Angelov, Plamen, Soares, Eduardo. Towards Explainable Deep Neural Networks (xDNN). arXiv preprint arXiv:1912.02523. 2019 Dec 5.
Contributing a New Large Dataset for SARS-CoV-2 Identification via CT Scan was originally published in Towards AI — Multidisciplinary Science Journal on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

