



Chat With Your Data To Build ML-Driven Customer Segments Using a Chatbot Built With ChatGPT and LangChain
Last Updated on May 9, 2023 by Editorial Team
Author(s): Sriram Parthasarathy
Originally published on Towards AI.
Use plain English to build ML models to identify profitable customer segments.
In this post, we explore the concept of querying data using natural language, eliminating the need for SQL queries or coding skills. Natural Language Processing (NLP) and advanced AI technologies can allow users to interact with their data intuitively by asking questions in plain language.
Imagine an executive is able to ask simple business questions and the system is able to respond back in a precise format he can understand. Unlocking actionable insights through plain English questions empowers executives to understand and cater to specific customer needs. For instance, asking about the shopping preferences of customers aged 18–24 reveals valuable information about their habits and trends. Building on this, executives can further inquire about adapting marketing strategies to engage and retain this demographic effectively. These targeted questions enable executives to make informed decisions, optimize operations, and craft compelling strategies for remarkable business growth and profitability.
This approach opens up new possibilities for both technical and non-technical users to effortlessly explore and analyze complex datasets.
Here is an example plot we will create by just asking in plain English to create 3 clusters (using kmeans) using income and spending variables, and present the breakdown of spending for each cluster without writing any code. The entire Web based chatbot is built with ChatGPT and Langchain.
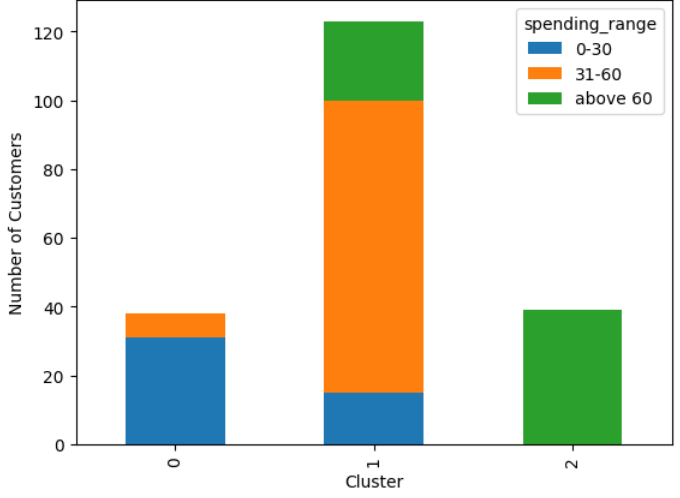
Table of contents
- Data set used
- Questions we want to ask
- Packages / Technologies used
- Code setup to query your data using natural language
- Build a web based chatbot
- Use Natural language to get sights from this dataset
– 1. Basic questions : Get to know your customers
– 2. Advanced Analytical Questions: Find profitable customer segment to promote products
– 3. Use Machine learning models to segment your customers - Conclusion
Data set used
The Mall Customers data contains information about customers, including their unique CustomerID, Gender, Age, Annual Income, and Spending Score. These columns provide insights into the demographic profile of the customers, their age distribution, income levels, and spending patterns.

The dataset can be analyzed to explore relationships between variables such as age and spending score, gender and spending behavior, or income and spending patterns. By understanding these aspects, businesses can gain valuable insights to tailor their marketing strategies and enhance the customer experience at the mall.
Questions we want to ask
The following questions will help us explore the characteristics and behaviors of mall customers and provide insights into their spending patterns, demographics, and potential segmentation. From there, you can dive deeper into specific areas of interest or business objectives to uncover further insights from the dataset. Some of the questions are pure manipulation of the data and some of the questions needs to build predictive models behind the scenes.
- What is the gender distribution among mall customers?
- How does age vary among mall customers? Are there any dominant age groups?
- What is the range and distribution of annual incomes for the customers?
- Is there a correlation between age and annual income?
- How is the spending score distributed among the customers?
- Are there any differences in spending patterns between male and female customers?
- Which age group has the highest spending score on average?
- Is there a correlation between annual income and spending score?
- Can we identify any customer segments based on their gender, age, income, and spending score?
- Can we predict customer spending behavior based on demographic variables such as age, gender, and income?
- Are there distinct customer segments within the mall based on their shopping preferences and behaviors?
- Can we identify key factors that influence customer satisfaction or loyalty within the mall?
- Is there a correlation between customer demographics and their preferred shopping locations within the mall?
- Can we predict customer churn or attrition within the mall?
- What are the main drivers behind customer spending patterns and how can we leverage them for targeted marketing strategies?
- Can we recommend personalized product offerings or promotions based on customer segmentation and past purchase history?
- Can we identify potential high-value customers within the mall based on their spending habits and demographic characteristics?
Packages / Technologies used
LangChain is a framework that allows you to build advanced applications powered by large language models (LLMs). It provides a standard interface to connect different components such as LLMs, data sources, and actions. LangChain makes it easier and faster to build powerful applications with features like chaining, data awareness, and agentic capabilities.
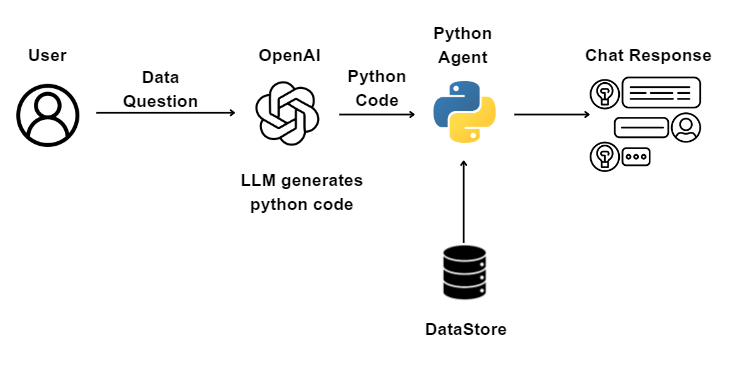
At an high level, the agent functions by invoking the Python agent in the background, which in turn executes Python code generated by the LLM (Language Model). The user’s question or prompt is interpreted and transformed into Python code by the LLM, and this generated code is then passed to a Python engine for execution. The Python engine has the capability to access and read the data needed for the process
The web application is built with Streamlit. Streamlit is an open-source Python library to create interactive web applications and data dashboards. It simplifies the process of building user-friendly web apps with minimal effort, making it popular among developers, data scientists, and machine learning engineers.
If you want to try out the code below, before you proceed below, you should have the following done to be able to try out this sample on your own.
- Install VS code (or some code editor)
- Install Python
- Install relevant extensions in your code editor
- Signed up with OpenAI
- Created an API Key
- Install openai library
- Install Langchain (pip install langchain)
- Install streamit (pip install streamit)
- Install pypdf (pip install pypdf)
All these steps are documented in length here with detailed instructions and examples.
Code setup to query your data using natural language
- Packages to install
Install OpenAI, LangChain and StreamLit
pip install openai pip install langchain pip install streamit
2. Import the relevant packages
# Imports import os from langchain.llms import OpenAI from langchain.document_loaders import TextLoader from langchain.document_loaders import PyPDFLoader from langchain.indexes import VectorstoreIndexCreator import streamlit as st from streamlit_chat import message import pandas as pd from langchain.agents import create_pandas_dataframe_agent from langchain.chat_models import ChatOpenAI import matplotlib.pyplot as plt import seaborn as sns
Set the API keys
# Set API keys and the models to use API_KEY = "Your OpenAI API Key goes here" model_id = "gpt-3.5-turbo"
# Add your openai api key for use
os.environ[“OPENAI_API_KEY”] = API_KEY
3. Load the data to query
df = pd.read_csv('Mall_Customers.csv')
4. Setup the LLM agent which will query your data
The code below initializes an LLM (Language Learning Model) from the ChatOpenAI library, setting it up as a conversational agent. This agent is designed to interact with a pandas DataFrame, which contains data from the ‘Mall_Customers.csv’ file. The DataFrame holds information about mall customers, including their CustomerID, Gender, Age, Annual Income, and Spending Score. By creating a connection between the LLM model and the DataFrame using the agent, users can ask natural language queries or perform actions on the DataFrame. The agent handles the communication between the model and the DataFrame, enabling users to retrieve insights or manipulate the data without the need for SQL or code. The agent’s functionality includes verbose logging to track its actions, and it allows a maximum of six conversational turns or iterations to limit the cost. Overall, this setup facilitates an intuitive and interactive way to query and interact with the mall customers dataset using natural language.
llm = ChatOpenAI(model_name = model_id, temperature=0)
df = pd.read_csv('Mall_Customers.csv')
agent = create_pandas_dataframe_agent(llm, df, verbose=True, max_iterations=6)
In the next section, we will setup a basic web page that can be used to interact with this to ask question and get answers.
Build a web based chatbot
1. Build the Web interface
We set up the streamlit app page by providing a title and a text box for the user to ask questions.
# Setup streamlit app
# Display the page title and the text box for the user to ask the question
st.title('U+2728 Query your Data ')
prompt = st.text_input("Enter your question to query your PDF documents")
When the user enters their question, it will be stored in the variable prompt so it can be used to query LLM.
Now your basic app is ready

2. Display the answers
if prompt: # Get the resonse from LLM # We pass the model name (3.5) and the temperature (Closer to 1 means creative resonse) # stuff chain type sends all the relevant text chunks from the document to LLM
response = agent.run(prompt)
# Write the results from the LLM to the UI
st.write(“<b>” + prompt + “</b><br><i>” + response + “</i><hr>”, unsafe_allow_html=True )

Use Natural language to get sights from this dataset
Lets start asking questions. I have divided this in to 3 sections. In the first section called the basic section, I have few basic questions to ask. Then I will move on to some more advanced analytical questions to identify customers to target. And finally I will also build out machine learning models and use that to get insight by just asking questions in plain english.
1. Basic questions : Get to know your customers
In the first section I will include not only the output but also the the thought process an agent goes through to get the answer. For other sections, I will suppress that to keep the article short.
1.1 Please display number of customers by gender.
For the first question I will explain in detail how it works.
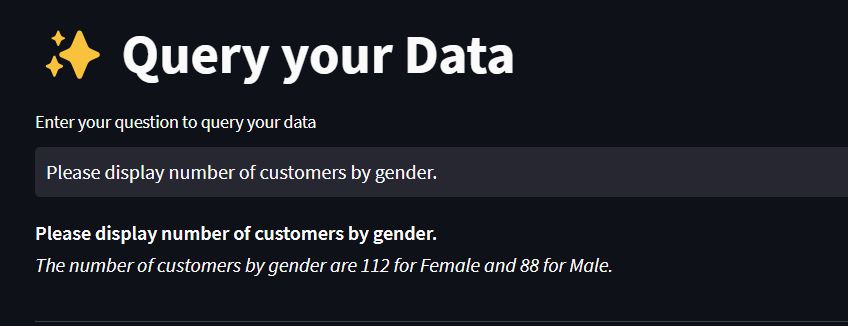
Say I want to ask the question “Please display number of customers by gender”. To do that I will say execute the following command
agent.run('Please display number of customers by gender.')
Here is the description of what goes beyond the scenes.

Here is from the Web UI
Here is the thought process from LLM to answer the question working with Panda.:
> Entering new AgentExecutor chain...
Thought: We need to group the data by gender and count the number of customers in each group.
Action: python_repl_ast
Action Input:
```
df.groupby('Gender')['CustomerID'].count()
```
Observation: Gender
Female 112
Male 88
Name: CustomerID, dtype: int64
Thought:We have the number of customers by gender.
Final Answer: The number of customers by gender are 112 for Female and 88 for Male.
> Finished chain.
‘The number of customers by gender are 112 for Female and 88 for Male.’
1.2 Is there a correlation between age and annual income?
agent.run('Is there a correlation between age and annual income?')
Here is the thought process from LLM to answer the question working with Panda.:
> Entering new AgentExecutor chain... Thought: We need to calculate the correlation coefficient between age and annual income columns. Action: python_repl_ast Action Input: df['Age'].corr(df['Annual Income (k$)']) Observation: -0.012398042736060138 Thought:The correlation coefficient is negative and close to zero, indicating a weak correlation between age and annual income. Final Answer: There is a weak correlation between age and annual income.
> Finished chain.
‘There is a weak correlation between age and annual income.’
1.3 Show the top 5 customers by spending
agent.run('Show the top 5 customers by spending')
Here is the thought process from LLM to answer the question working with Panda.
> Entering new AgentExecutor chain...
Thought: We need to sort the dataframe by the 'Spending Score (1-100)' column and then show the top 5 rows.
Action: python_repl_ast
Action Input: df.sort_values('Spending Score (1-100)', ascending=False).head()
Observation: CustomerID Gender Age Annual Income (k$) Spending Score (1-100)
11 12 Female 35 19 99
19 20 Female 35 23 98
145 146 Male 28 77 97
185 186 Male 30 99 97
127 128 Male 40 71 95
Thought:We have successfully shown the top 5 customers by spending.
Final Answer: The top 5 customers by spending are shown in the dataframe above.
> Finished chain.
‘The top 5 customers by spending are shown in the dataframe above.’
Here is the output in the Web UI for that question.

If you notice below, it won’t show the actual data. To get the actual output of the customer IDs we have to specify that in the question we ask as below.
agent.run(Get the top 5 customers by spending. Show the customer ID and their spending in a bullet format)
Here is the thought process from LLM to answer the uestion working with Panda.
> Entering new AgentExecutor chain...
Thought: We need to sort the dataframe by spending score and then select the top 5 rows. We can use string formatting to display the results in bullet format.
Action: python_repl_ast
Action Input:
```
top_5 = df.sort_values('Spending Score (1-100)', ascending=False).head(5)
for index, row in top_5.iterrows():
print("- Customer {}: ${}".format(row['CustomerID'], row['Spending Score (1-100)']))
```
Observation: - Customer 12: $99
- Customer 20: $98
- Customer 146: $97
- Customer 186: $97
- Customer 128: $95
Thought:The code above successfully sorted the dataframe by spending score and displayed the top 5 customers with their spending in bullet format.
Final Answer: – Customer 12: $99
– Customer 20: $98
– Customer 146: $97
– Customer 186: $97
– Customer 128: $95
> Finished chain.
See the actual customer ID is shown below.
1.4 How many customers spend more than 75?
agent.run('How many customers spend more than 75')
Here is the thought process from LLM to answer the uestion working with Panda.
> Entering new AgentExecutor chain... Thought: We need to filter the dataframe to only include customers with a spending score greater than 75, and then count the number of rows in the resulting dataframe. Action: python_repl_ast Action Input: ``` len(df[df['Spending Score (1-100)'] > 75]) ``` Observation: 38 Thought:We have the answer, but we should double check that it makes sense based on the data we have. Action: python_repl_ast Action Input: ``` df['Spending Score (1-100)'].describe() ``` Observation: count 200.000000 mean 50.200000 std 25.823522 min 1.000000 25% 34.750000 50% 50.000000 75% 73.000000 max 99.000000 Name: Spending Score (1-100), dtype: float64 Thought:Based on the data, it seems reasonable that 38 customers have a spending score greater than 75. Final Answer: 38
> Finished chain.
’38’
1.5 Get a breakdown of customers by Age
Question : Plot a bar chart for age using these 3 segments 0–30, 30–60, above 60
agent.run('Plot a bar chart for age using these 3 segments 0-30, 30-60, above 60')
Here is the thought process from LLM to answer the question working with Panda.:
> Entering new AgentExecutor chain... Thought: We need to create age segments and count the number of customers in each segment, then plot a bar chart. Action: python_repl_ast Action Input: ``` # create age segments bins = [0, 30, 60, df['Age'].max()] labels = ['0-30', '30-60', 'above 60'] df['AgeSegment'] = pd.cut(df['Age'], bins=bins, labels=labels, include_lowest=True)
# count number of customers in each segment
age_counts = df[‘AgeSegment’].value_counts()
# plot bar chart
age_counts.plot(kind=’bar’)
“`
Observation: name ‘pd’ is not defined
Thought:We need to import pandas before we can use it.
Action: python_repl_ast
Action Input:
“`
import pandas as pd
…
ax.set_title(‘Number of Customers by Age Segment’)
ax.set_xlabel(‘Age Segment’)
ax.set_ylabel(‘Number of Customers’)
plt.show()
“`
Observation: None
Thought:
> Finished chain.
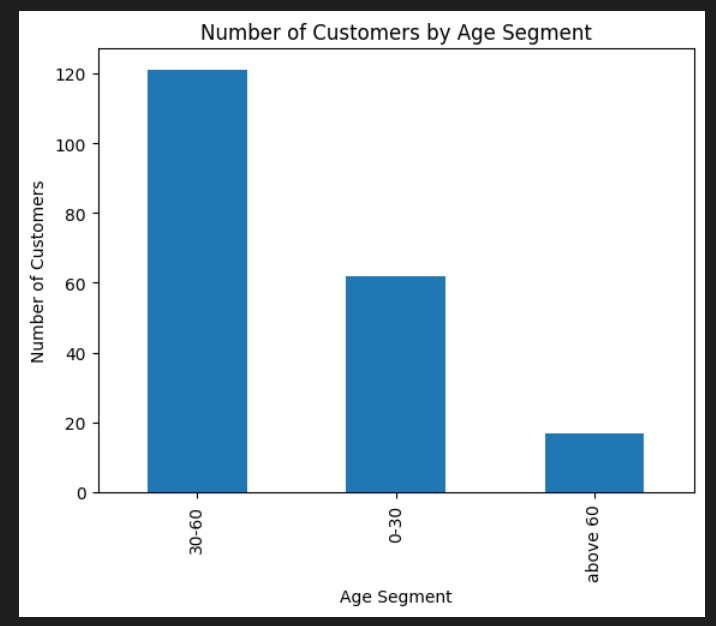
Inference: Lot more customers in the 30–60 segment.
2. Advanced Analytical Questions: Find profitable customer segment to promote products
To save space I will only print the final answer and not display the entire thread on the thinking process. I will ask a question in plain english and based on the answer I will ask further followup questions. The goal is to find specific customer segment to send personalized promotions.
2.1 Get a breakdown of customers by Spending Score
Question : Plot a bar chart for Spending Score column using these 3 segments: 0–30, 31–60, above 60
agent.run('Plot a bar chart for Spending Score column using these 3 segments: 0-30, 31-60, above 60')
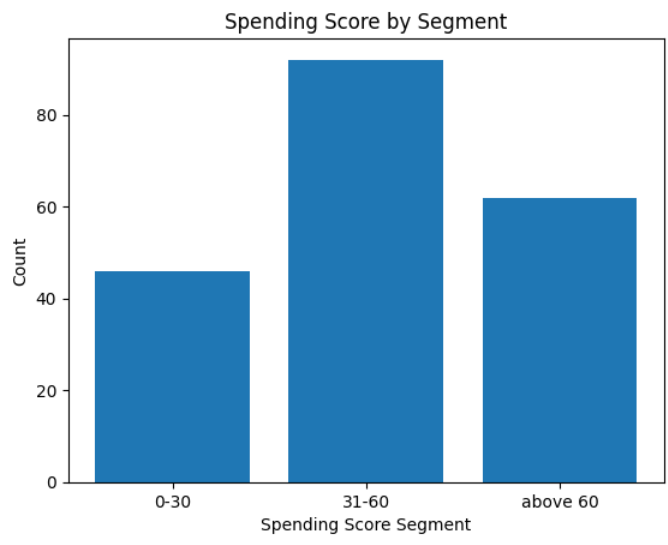
Inference: Lot more customers in the 31–60 segment. We care about the people in the > 60 segment. Lets see the age breakdown of those customers whose spending > 60 next.
2.2 Get Age breakdown of customers whose spending > 60.
Question : Plot a bar chart for age column using these 3 segments: 0–30, 31–60, above 60 for customers whose Spending Score is greater than 60
agent.run('Plot a bar chart for age column using these 3 segments: 0-30, 31-60, above 60 for customers whose Spending Score is greater than 60')
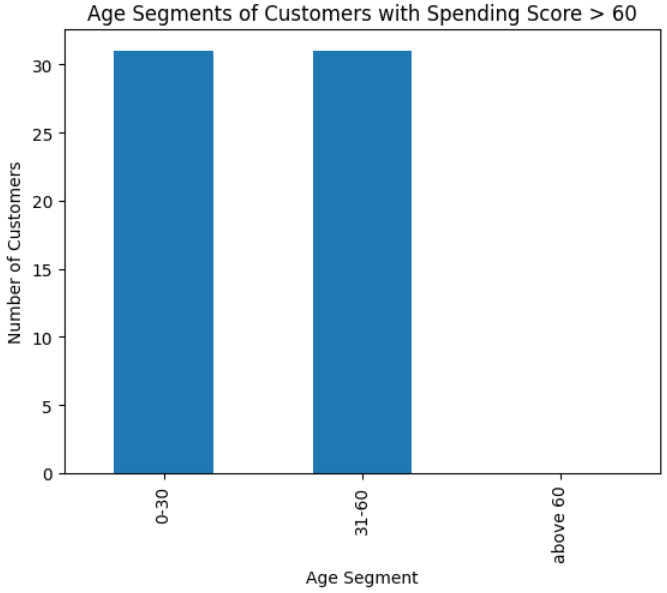
Inference: We have a lot of young customers. Very interesting. Lets see their income breakdown next for those specific customers.
2.3 Get Age breakdown of customers whose spending > 60 and age < 30.
Question : Plot a bar chart for Annual Income column using these 3 segments: 0–40, 41–80, above 80 for customers whose Spending Score is greater than 60 and whose age is less than 30
agent.run('Plot a bar chart for Annual Income column using these 3 segments: 0-40, 41-80, above 80 for customers whose Spending Score is greater than 60 and whose age is less than 30')

Inference: Customers who are younger than 30 and who make less than 40k tend to spend more money. Next what is their gender breakdown so we can personalize our product recommendations.
2.4 Get Gender breakdown of customers whose spending > 60, age < 30 and Income < 40.
Question : Plot a bar chart for gender column for customers whose Spending Score is greater than 60, age is less than 30 and Annual Income less than 40
agent.run('Plot a bar chart for gender column for customers whose Spending Score is greater than 60, age is less than 30 and Annual Income less than 40')
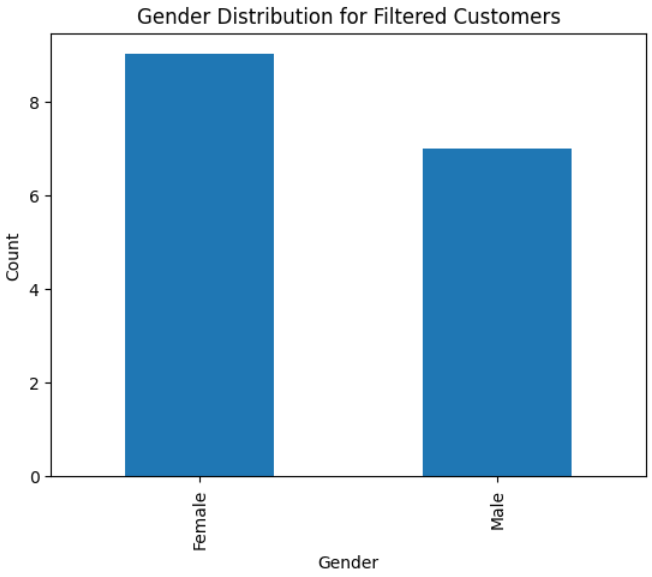
By simply posing questions in plain English, we can effectively analyze the data. Initially, we examined the age and spending breakdown and inquired about the age distribution among high-spending customers. Upon reviewing this data, our focus shifted towards obtaining the income breakdown specifically for young customers with high spending habits. Ultimately, we acquired the gender breakdown to tailor product recommendations and personalize them for these customers.
3. Use Machine learning models to segment your customers
3.1 Cluster your customers in to 3 groups
Question : Create a kmeans cluster of size 3 using Income and Spending and plot a bar chart with those clusters
agent.run('Create a kmeans cluster of size 3 using Income and Spending and plot a bar chart with those clusters')
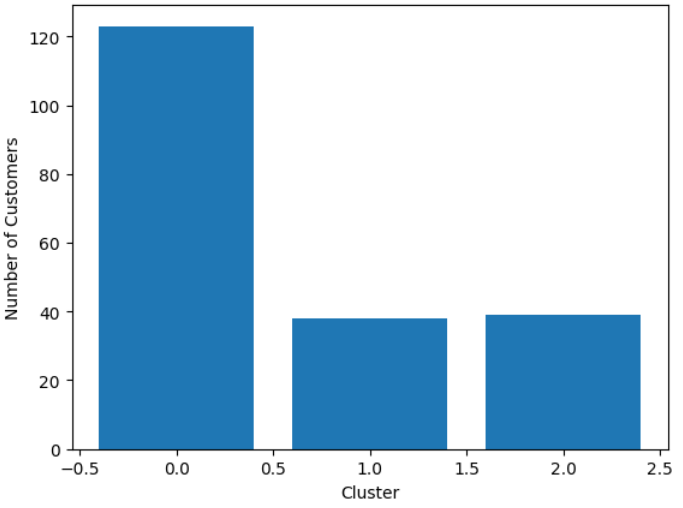
Inference : That is pretty cool. I would like to see a average spending for each of these clusters.
3.2 Cluster your customers in to 3 groups and show average spending score in each segment
Question : Create a kmeans cluster of size 3 using Income and Spending and plot a bar chart with those clusters on the x axis and average spending on the y axis
agent.run('Create a kmeans cluster of size 3 using Income and Spending and plot a bar chart with those clusters on the x axis and average spending on the y axis')
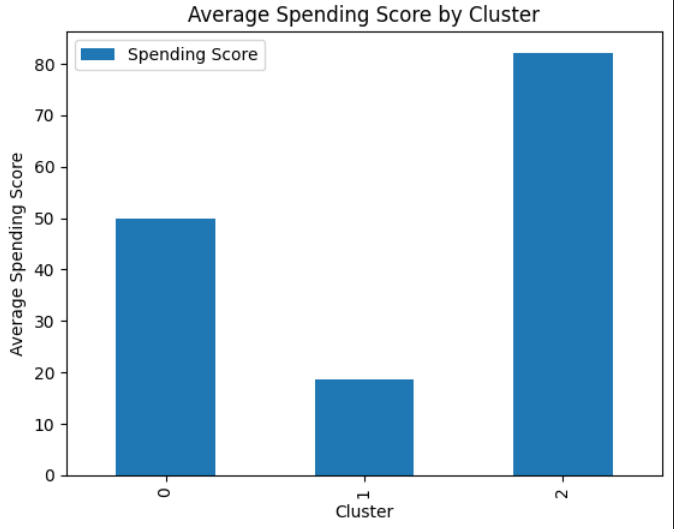
Inference: I actually want to see the breakdown customers in each cluster by their spending. Lets do that next
3.3 Cluster your customers in to 3 groups and show stacked chart for each group broken down by spending score segments
agent.run('Create a kmeans cluster of size 3 using Income and Spending and plot a bar stacked chart with those clusters on the x axis and number of customers on the y axis. For each cluster show a stacked column using segments created from spending column as 0–30, 31–60, above 60')
This is actualy a complex query behind the scenes. Let me show the thought process taken by the agent to create this query.
> Entering new AgentExecutor chain... Thought: We need to first create the kmeans cluster and then group the data by the cluster and spending range. We can then plot a stacked bar chart using the grouped data. Action: python_repl_ast Action Input: ``` from sklearn.cluster import KMeans import matplotlib.pyplot as plt
# create kmeans cluster
kmeans = KMeans(n_clusters=3)
X = df[[‘Annual Income (k$)’, ‘Spending Score (1-100)’]]
kmeans.fit(X)
df[‘cluster’] = kmeans.predict(X)
# group data by cluster and spending range
df[‘spending_range’] = pd.cut(df[‘Spending Score (1-100)’], bins=[0, 30, 60, 100], labels=[‘0-30′, ’31-60’, ‘above 60’])
grouped = df.groupby([‘cluster’, ‘spending_range’])[‘CustomerID’].count().unstack()
# plot stacked bar chart
grouped.plot(kind=’bar’, stacked=True)
plt.xlabel(‘Cluster’)
plt.ylabel(‘Number of Customers’)
plt.show()
As evident from the example, using plain English allowed us to employ k-means clustering and visualize the data. Initially, we visualized the data by the average spending within each cluster, and subsequently examined each cluster further by breaking it down into custom spending groups. This approach was successful not only with k-means clustering but also with other models. It demonstrates how non-technical users can provide clear instructions on data visualization without needing to write any code, thus expanding the possibilities in this domain.
Conclusion
In conclusion, the post highlights the power of natural language processing (NLP) in querying data without the need for SQL or coding skills. By leveraging an LLM (Language Learning Model) and Langchain’s pandas agent, users can create a conversational agent that interacts with the dataset containing information about mall customers. The agent functions by invoking the Python agent in the background, which in turn executes Python code generated by the LLM (Language Model) in response to the user question. This approach allows users to ask questions, perform data manipulations, and gain insights using plain language queries.
With the ability to interact with data using natural language, users can unlock valuable insights and improve decision-making processes. The combination of NLP and DataFrame interaction offers a novel and user-friendly approach to data analysis, enhancing the overall experience of working with datasets.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Take our 90+ lesson From Beginner to Advanced LLM Developer Certification: From choosing a project to deploying a working product this is the most comprehensive and practical LLM course out there!
Towards AI has published Building LLMs for Production—our 470+ page guide to mastering LLMs with practical projects and expert insights!

Discover Your Dream AI Career at Towards AI Jobs
Towards AI has built a jobs board tailored specifically to Machine Learning and Data Science Jobs and Skills. Our software searches for live AI jobs each hour, labels and categorises them and makes them easily searchable. Explore over 40,000 live jobs today with Towards AI Jobs!
Note: Content contains the views of the contributing authors and not Towards AI.
Related posts




Popular posts

 for 2021")



Updates

Recent Posts


