



Build Your own Recommendation Engine-Netflix Demystified: Demo+Code
Last Updated on November 18, 2020 by Editorial Team
Author(s): Ravi Shankar
An intro to recommender systems with live implementation
How often you feel after a hectic day at work that what should I watch next? As for me — yes, and more than once. From Netflix to Prime Video, building robust movie recommendation systems is extremely important, given the huge demand for modern consumers’ personalized content.
Once at home, sitting in front of the TV seems like a fruitless exercise with no control and no remembrance of the content we consumed. We tend to prefer an intelligent platform which understands our tastes and preferences and not just run on autopilot.
I have given a shot to building the recommendation engine based on my professional experience at Hotstar and binging experience on Netflix. I would consider this exercise fruitful if it can make you watch at least one movie based on its suggestions.
The dataset comprises of ~10k movies across all Indian languages released since 1925. The final engine is hosted at:
Tableau Public
Edit description
public.tableau.com

Allow me to explain the basic logic of a recommendation engine before building one ourselves. There are broadly 3 algorithms which power a recco engine:
- Popular Movies: This algorithm handpicks trending content on the platform and recommends these movies to all the users. There is a major absence of personalization since every user would be shown the same content. It also implies the prominence of clickbait content with an eye-catching thumbnail. This algorithm fails to showcase the vast repository of titles available on the platform.

2. User-based Collaborative filtering: It shows what movies other users are watching and assumes that others would watch similar content. It tries to create a persona/watchlist of every user before movie recommendations. The major problem is the cold-start problem when a new user arrives on the platform, and the engine isn’t able to fire right reccos due to the absence of user history. It also assumes its users to be logical, and their movie choices represent their true taste. But there arises a situation where all the users are watching similar content based on the thumbnail, and thus, similar content is repeated for every user. It is a vicious cycle with similar movies being repeated in a loop, and again, the variety of content never surfaces upfront.
3. Item-based filtering: First thing first, it does not need any user-level data, and the recommendation engine can be up and running even in an isolated home PC(No data privacy issue). The algorithm relies on the basic assumption of why a user is watching a movie, Is it due to actor or director or war scene or revenge or based on a novel? This understanding of the consumer mindset forms the most important part in predicting what the user would watch next?
Netflix realizes metatags’ power and generates 1000s of metatags of each content by paying users to watch content all day long.
How I Got My Dream Job Of Getting Paid To Watch Netflix
“This is a very loaded question for someone who makes her living off loving films and TV shows-it’s akin to asking a…
www.fastcompany.com
Below is a representation of how Netflix sees the content.
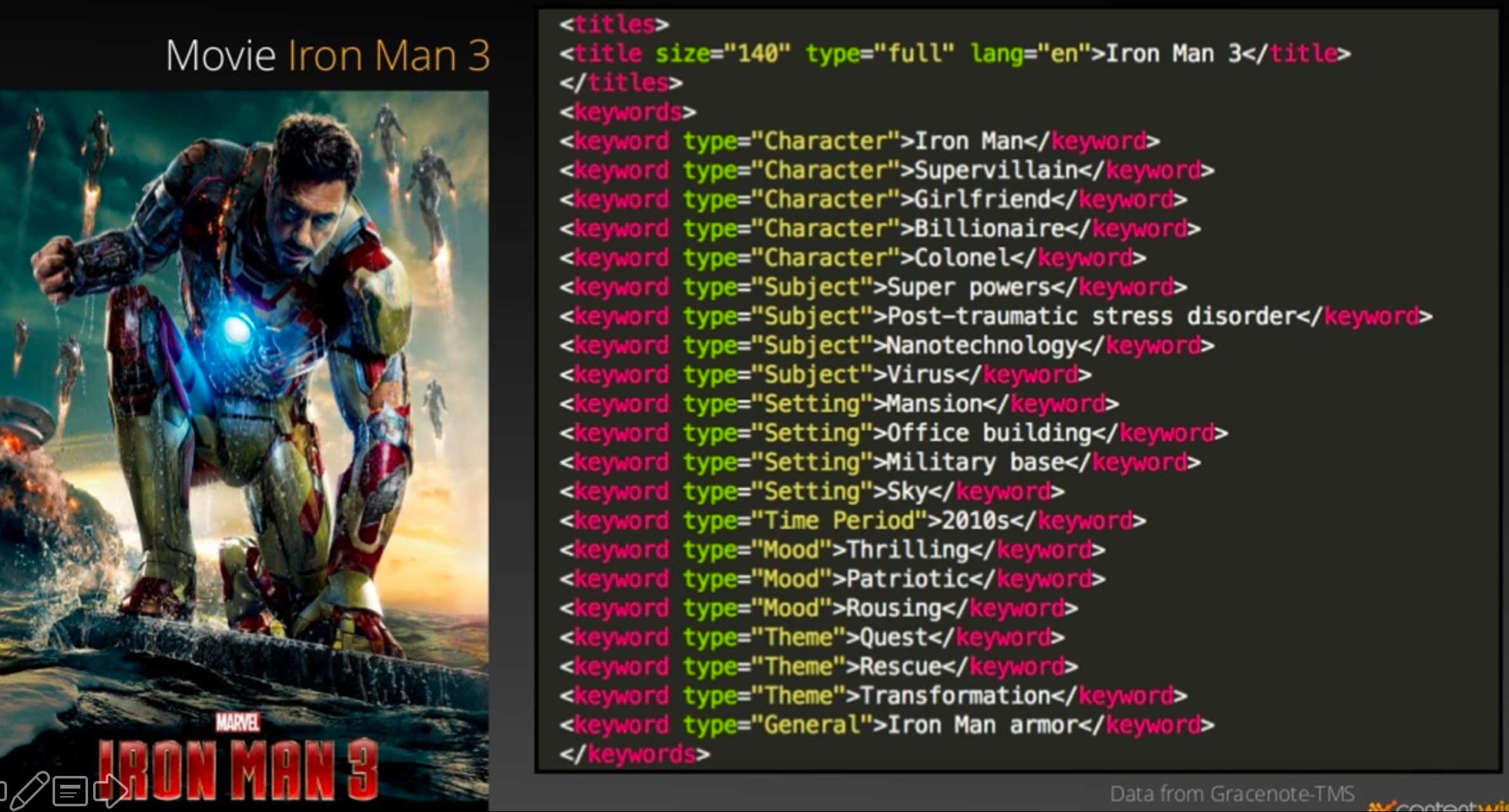
The user is shown content similar to the items he has watched, and the node becomes stronger with each additional item. In addition to understanding consumers’ deep-down behavior, it also solves the cold start problem and doesn’t require any personal data for experimentation ground. Next time Netflix is recommending a movie, pause back for a few seconds to analyze what connection it established between my last viewed and to be viewed content.
Now, the question is: If Netflix has already cracked this, why should someone even try one more recommendation engine?
- Netflix doesn’t have all the Indian Movies, so the user would most probably be revolving in Netflix’s basket of 300–400 Movies.
- Netflix doesn’t allow the user to filter out the movies based on actors, director, IMDB ratings, Release year, or metatags.
- Netflix doesn’t even allow users to sneak-peek on its content without membership.
- It has more focus on recently released movies, and an 80s fan would feel a tad disappointed seeing its recommendations.
Let’s try creating an algorithm that recommends using item-based Collaborative filtering based on metatags.
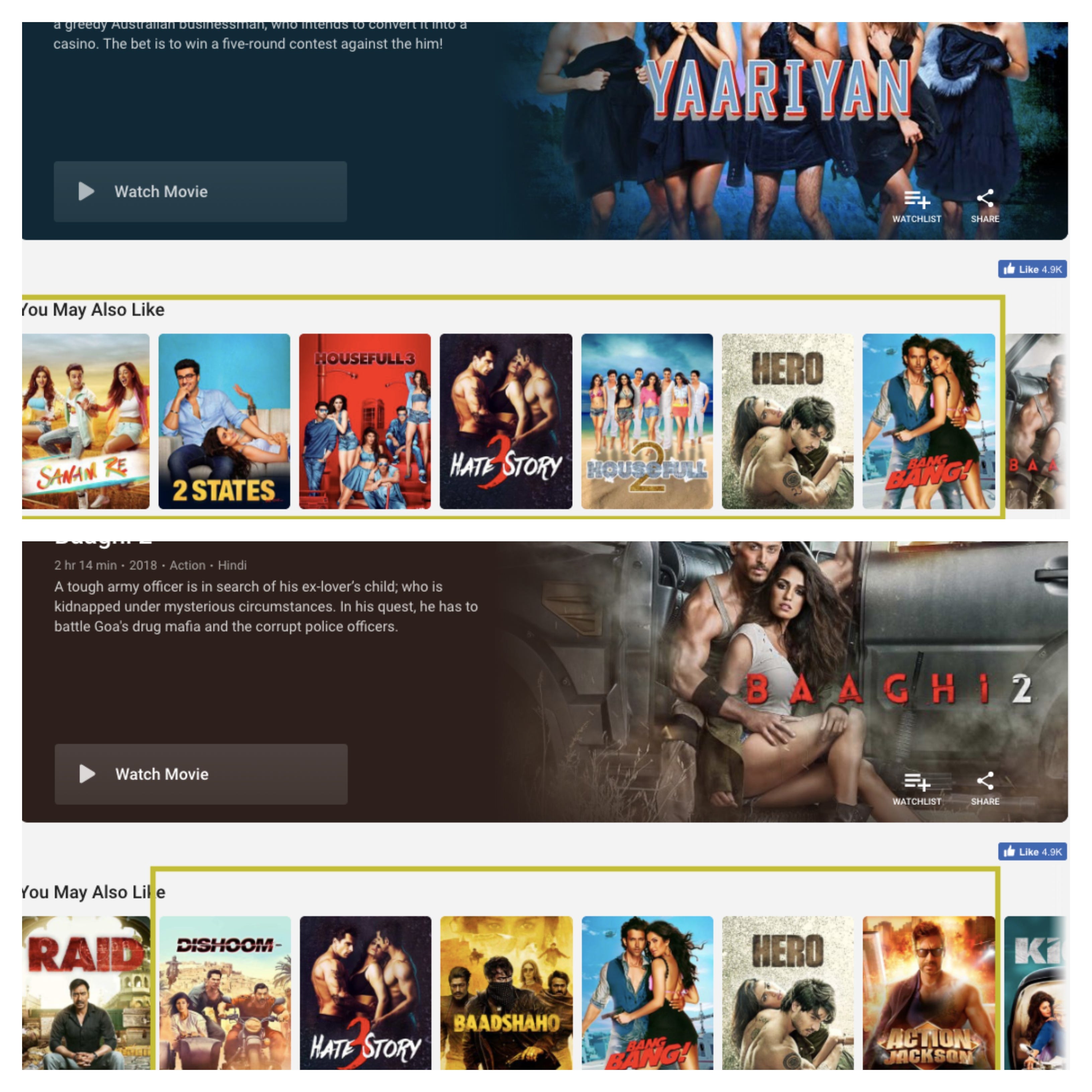
What would our live web demo look like in the end?
a. Filtering capability across IMDB ratings, metatags, actors, genre, language, release year, etc.
b. Filtered titles and their storyline with the capability to play YouTube trailer of the movie
c. Select our favorite movies for its recommendation list.
Tableau Movies Data
Let’s get our hands dirty and build the engine:
Stage 1: Data Collection and Cleaning.
This was the most painful exercise with 2 lac movies/tvshows/documentary released till now. Special thanks to IMDB for helping us with the interface where we can download data about titles, cast&crew, Release year, and genre.
IMDb
Subsets of IMDb data are available for access to customers for personal and non-commercial use. You can hold local…
www.imdb.com.
I needed keywords, YouTube trailer link, storyline, language, and Poster URL even after basic data.
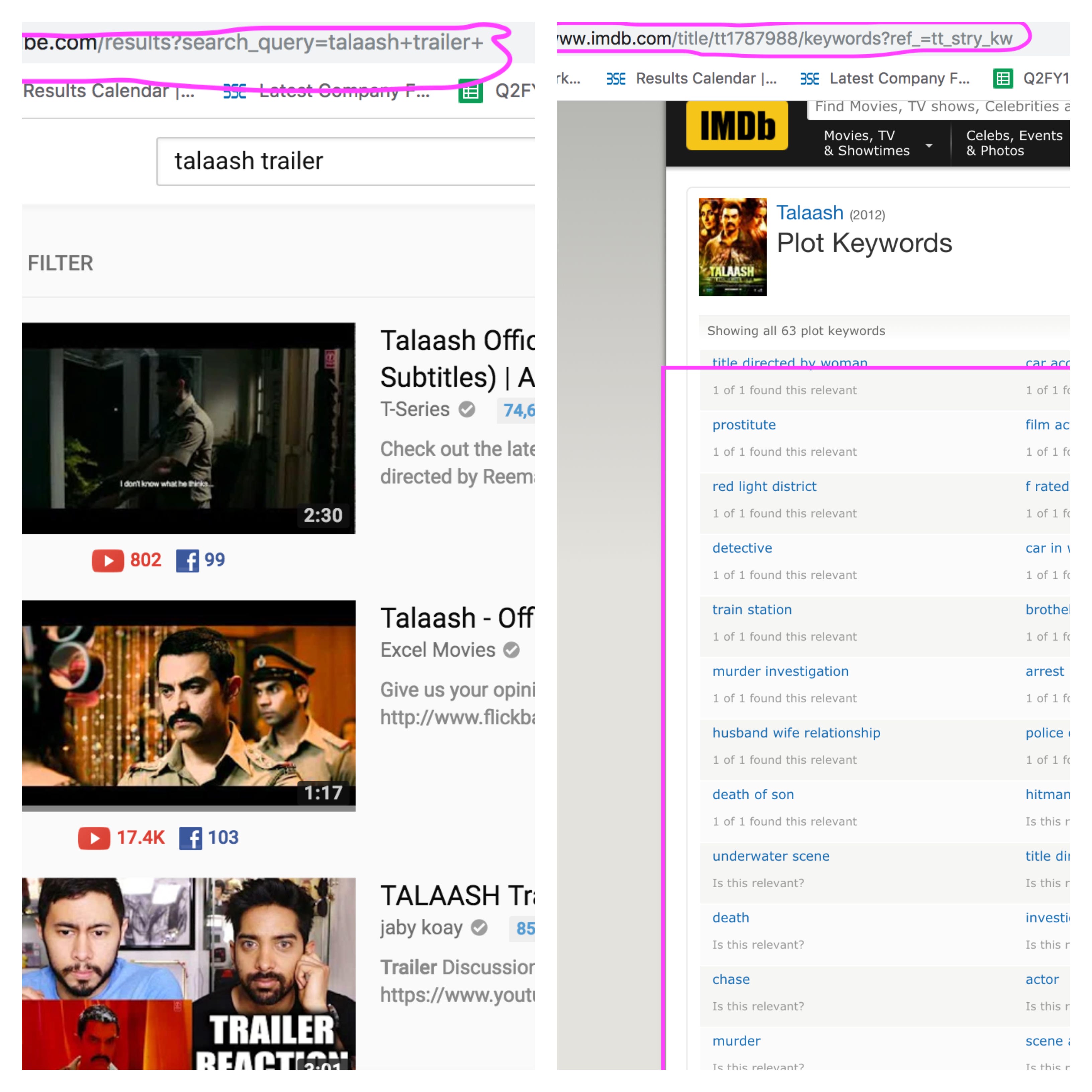
#Web Scraping Code #Python Code for YouTube trailer:from bs4 import BeautifulSoup as bs import requests import pandas as pd a=pd.read_csv("database_Indian.csv") base = "https://www.youtube.com/results?search_query=" url=[] for t in range(1,9140): try: qstring = a['originalTitle'][t]+' trailer' r = requests.get(base+qstring) page = r.text soup=bs(page,'html.parser') vids = soup.findAll('a',attrs={'class':'yt-uix-tile-link'}) videolist=[] for v in vids: tmp = 'https://www.youtube.com' + v['href'] videolist.append(tmp) videolist[1] print(t) print(videolist[1]) url.append(videolist[1]) time.sleep(10) except: print('error')#For Keywords# a4=db c=NULL for(i in 1:9140) {tryCatch({ url=paste0("https://www.imdb.com/title/",a4$tconst[i],"/keywords?ref_=tt_stry_kw") print(url) a1<-read_html(url) kw=as.character(html_nodes(a1,xpath='//*[@id="keywords_content"]/table')) b2=cbind(a4$tconst[i],as.character(kw)) c=rbind(c,b2) print(i) }, error=function(e){}) }
Stage 2: Recommendation engine algorithm:
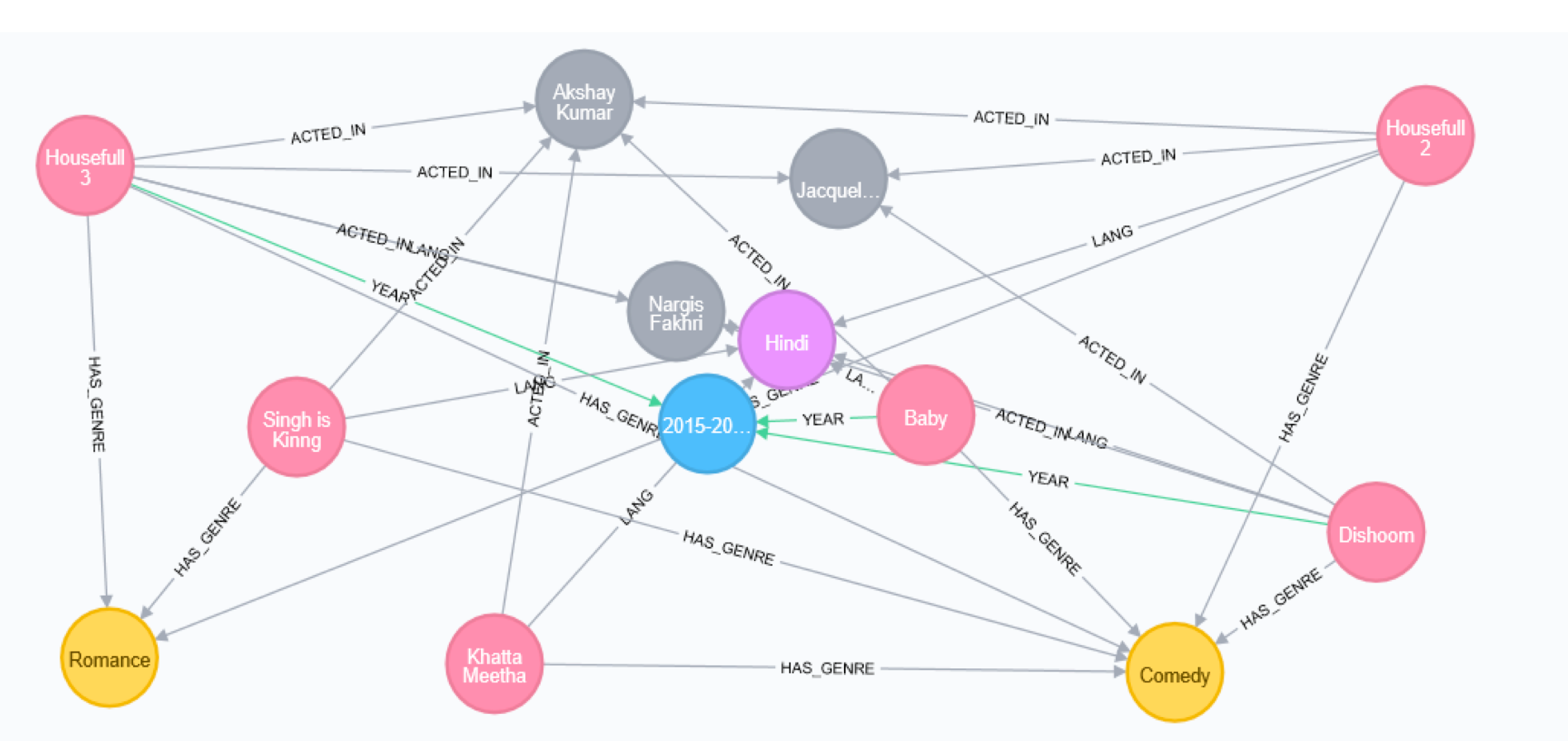
Since I have sufficient features/metatags of a movie, I used Cosine Similarity, i.e., the cosine of the angle between the 2 vectors of the item vectors of A and B. Closer the vectors, the smaller will be the angle and larger the cosine and thus higher in the recommendation list. It turned out to be a 9000*9000 matrix for cosine similarity, and I had to make use of Google Cloud /Big Query to process the data.
Stage 3: Visualization
I had to do quite a research between Apache Superset, Neo4j, and Tableau as a final hosting platform and preferred tableau owing to its ease of handling by Non-technical audiences and free hosting/database connections (Who doesn’t like free stuff!)
Feel free to ask for any doubts about integration and embed it on your website with due credits to Arjun Goswami or me. https://www.linkedin.com/in/arjunsg/
Source Credits: IMDB.com, YouTube.com
Idea Inspiration: Prime Video, Hotstar, and Netflix
Build Your own Recommendation Engine-Netflix Demystified was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts





")
