



Build and Deploy Custom Docker Images for Object Recognition
Last Updated on March 21, 2023 by Editorial Team
Author(s): Hasib Zunair
Originally published on Towards AI.
Motivation
Several components are involved in building and deploying full-stack ML applications. For example, you have ML frameworks like PyTorch to build your model, FastAPI for making API endpoints, and Gradio for a frontend user interface (UI). Not surprisingly, it is often the case that using all of these tools together work locally on your machine (¯\_(ツ)_/¯), but is not reproducible in others. This is largely due to different versions of libraries, version mismatching of other dependencies, and different operating systems (OS) on those machines.
To address this problem and ensure replicability and reproducibility across different machines, Docker comes to the rescue. It can be used to create and run specific applications in isolation and also connect different applications/services. This is directly related to MLOps since you move towards serving ML models to end users.
The article is organized as follows:
- Goals
- Basic Concepts
- Building backend with PyTorch and FastAPI
- Building frontend with Gradio
- Launch the app in two lines
All code used in this post is available on GitHub.
Goals
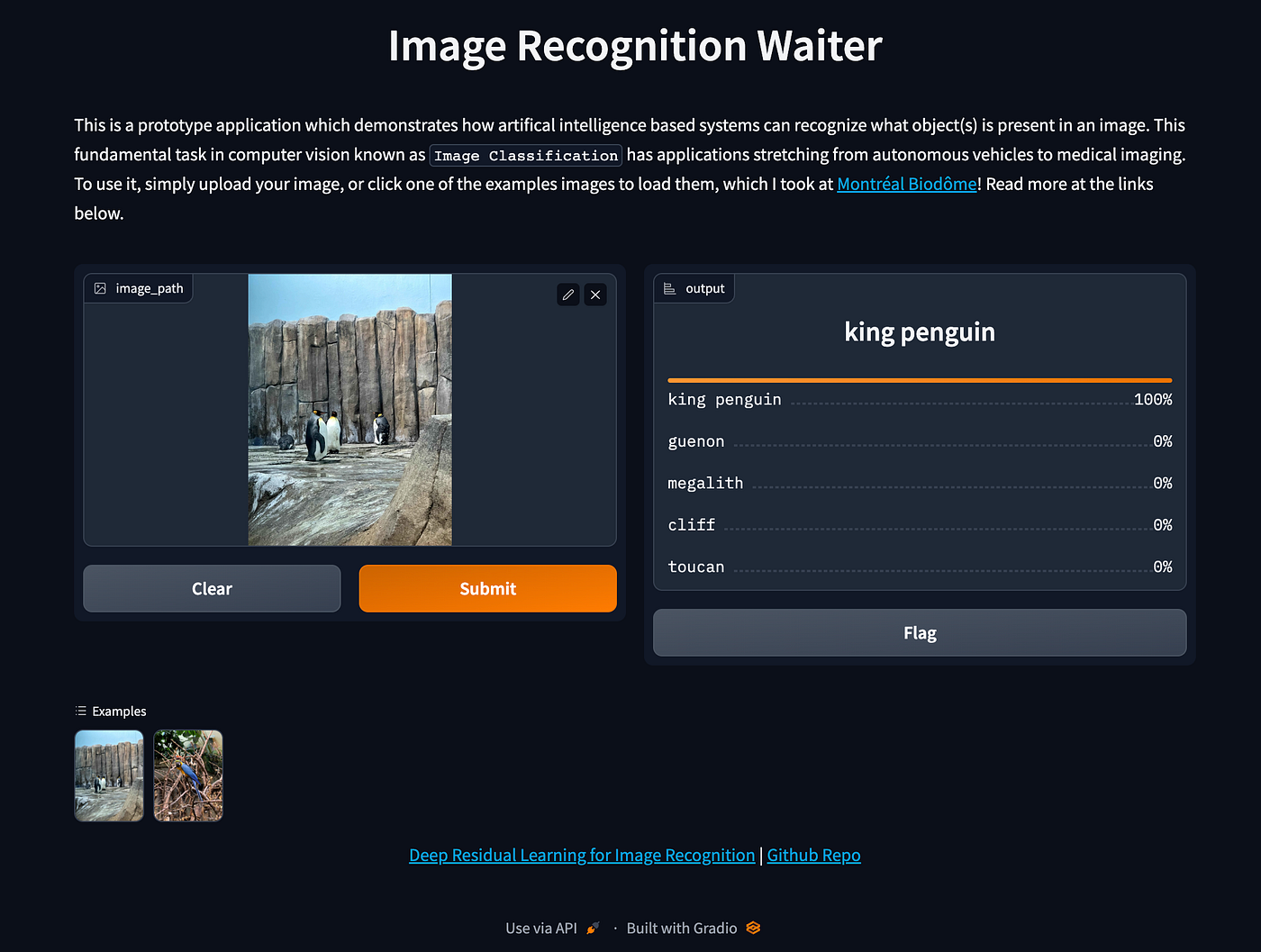
This article shows you how to build and deploy a full stack machine learning image recognition application from scratch that is able to recognize different objects from your own images, not docker images!
After your application is set up and running locally, you’ll see how to containerize it and finally deploy the docker images (i.e., running containers). A custom docker image is built for the machine learning model and the RESTful API that serves as the backend. And another for the frontend with a web UI that accepts input images calls the API endpoint to make a prediction and shows results.
Basic Concepts
Image recognition
Image recognition is the fundamental task in computer vision of recognizing what object(s) is present in an image. This is also known as Image Classification, which has applications stretching from autonomous vehicles to medical imaging.
FastAPI
FastAPI is a modern web framework used for building RESTful APIs with Python. It is fast, easy to understand, and requires minimal code and potentially fewer bugs. While FastAPI can be used for web development, you’ll see how to use it specifically to build APIs.
Gradio
Gradio is used to create and share ML applications. It is a quick way to build proof-of-concept (POC) ML apps with a user-friendly web interface for anyone to use it.
Docker
Docker is for building isolated applications. The core idea behind docker is to build an app that contains the written source code as well as the specifications (e.g., libraries, versions, and OS) to run it. These are used to build a docker image, that can later be stored in Docker Hub for sharing with others. From the docker image, you can run the application in a docker container where the environment of this container is defined by the specifications when creating the docker image.
An image is a snapshot of an environment, and a container runs the software.
Let’s get to the building now!
Building backend with PyTorch and FastAPI
The backend consists of two components: a PyTorch machine learning model and a RESTful API.
Machine Learning model: The pretrained model can predict 1000 different objects. You can find the list of 1000 objects here. Of course, it would work the same if you had trained your own model, let’s say to detect dogs or cats! Specifically, the model is a convolutional neural network (CNN) known as ResNet-18 [1] that is trained on the ImageNet [2] dataset. You can easily load this model in PyTorch using:
import torch model = torch.hub.load(‘pytorch/vision:v0.10.0’, ‘resnet18’, pretrained=True)
For making predictions on your own input images, you would need to preprocess the image to the desired size as well as normalize the input according to how the ResNet-18 model was trained. This is done by:
def preprocess(input_image): preprocess = transforms.Compose([ transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]), ]) input_tensor = preprocess(input_image) input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model return input_batch
Once the input image is preprocessed, it is ready for the model to make a prediction. The predictfunction defined below takes in an image and the ResNet-18 model as input. The model then makes a prediction and returns the top five labels (i.e., object/class names) as well as the probability scores.
def predict(input_image, model):
# Move the input and model to GPU for speed if available
if torch.cuda.is_available():
input_image = input_image.to('cuda')
model.to('cuda')
with torch.no_grad():
output = model(input_image)
# The output has unnormalized scores. To get probabilities, you can run a softmax on it.
probabilities = torch.nn.functional.softmax(output[0], dim=0)
results = {“success”: False}
results[“predictions”] = []
# Read the categories
with open(“imagenet_classes.txt”, “r”) as f:
categories = [s.strip() for s in f.readlines()]
# Show top categories per image
top5_prob, top5_catid = torch.topk(probabilities, 5)
for i in range(top5_prob.size(0)):
r = {“label”: categories[top5_catid[i]], “probability”: float(top5_prob[i].item())}
results[“predictions”].append(r)
results[“success”] = True
return results
Now, you have the model setup. The next component on the backend involves building an API endpoint around this prediction function.
RESTful API: To create an API endpoint, the prediction function is served using FastAPI. This involves loading the model (i.e., downloading and instantiating the model file) and finally creating a function that accepts POST requests. This is as simple as:
@app.post("/api/predict")
async def predict_image(image: bytes = File(...)):
# Read image
image = read_image(image)
# Preprocess image
image = preprocess(image)
# Predict
predictions = predict(image, model)
return predictions
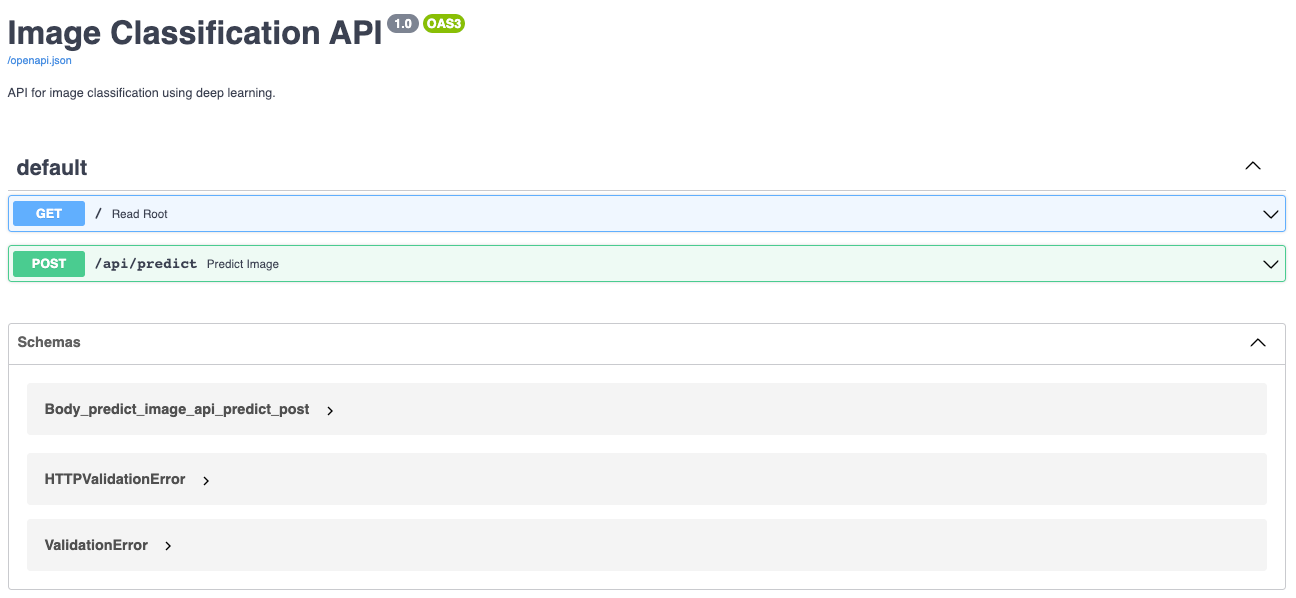
When the server is running, you can send POST requests with an image to the API endpoint, and it will return the top five labels and probability scores. You can also find the documentation page at `http://127.0.0.1:8000/docs` that looks like this:
You’ve got the backend running, which accepts images as inputs and outputs the predicted labels/objects. It’s time to dockerize the entire backend.
Dockerize the backend: To run this API endpoint inside of a docker container, a docker image needs to be created. This requires requirement.txt and a Dockerfile. First, requirement.txt is set up to define all modules needed for the app to work.
torch torchvision Pillow gunicorn fastapi==0.61.1 uvicorn==0.11.8 python-multipart requests==2.24.0
Second, a Dockerfile is created to set up the necessary dependencies. This is what it looks like:
# Use an official Python runtime as a parent image FROM python:3.6-slim
# Copy the requirements file into the image
COPY ./requirements.txt /app/requirements.txt
# Set the working directory to /app
WORKDIR /app
# Install any needed packages specified in requirements.txt
RUN pip install -r requirements.txt
# Copy every content from the local folder to the image
COPY . .
# Run server
CMD [“uvicorn”, “main:app”, “–host=0.0.0.0”, “–port=80”]
Now that requirement.txt &Dockerfile are setup, you can build an image using this specification. Then, you can run an instance of this image in a docker container using:
# build docker build -t classification_model_serving . # run docker run -p 8000:80 --name cls-serve classification_model_serving
The model is deployed as an API endpoint through a docker container in your local machine. To make a request, run:
curl -X POST -F image=@test1.jpeg "http://0.0.0.0:8000/api/predict"
If everything is working correctly, you will see an output like:
{
"success": true,
"predictions":
[
{
"label": "king penguin",
"probability": 0.999931812286377
},
{
"label": "guenon",
"probability": 9.768833479029126e-06
},
{
"label": "megalith",
"probability": 8.01052556198556e-06
},
{
"label": "cliff",
"probability": 7.119778274500277e-06
},
{
"label": "toucan",
"probability": 6.5011186052288394e-06
}
]
}
The backend is now dockerized. You can send a request to the API endpoint with an image, and it returns the labels and probability scores. Let’s now see how you can build the front end.
Make sure the backend docker container is running when you first run the frontend docker container in the next section.
Building frontend with Gradio
The task of the frontend is to accept input images from the user, make a call to the API endpoint (which is our backend that is already running) with the image that returns predictions, and finally show the results to the user. The inference function i) loads the image (whether it is uploaded by the user or an example) ii) makes a POST request to the API endpoint iii) formats the results for visualization, and it looks like this:
def inference(image_path):
# Load the input image and construct the payload for the request
image = open(image_path, "rb").read()
payload = {"image": image}
# Submit the request
r = requests.post(REST_API_URL, files=payload).json()
# Ensure the request was sucessful, format output for visualization
output = {}
if r[“success”]:
# Loop over the predictions and display them
for (i, result) in enumerate(r[“predictions”]):
output[result[“label”]] = result[“probability”]
print(“{}. {}: {:.4f}”.format(i + 1, result[“label”],
result[“probability”]))
else:
print(“Request failed”)
return output
And the layout of the web UI is defined by:
title = "Image Recognition Demo" description = "This is a prototype application which demonstrates how artifical intelligence based systems can recognize what object(s) is present in an image. This fundamental task in computer vision known as `Image Classification` has applications stretching from autonomous vehicles to medical imaging. To use it, simply upload your image, or click one of the examples images to load them, which I took at <a href='https://espacepourlavie.ca/en/biodome' target='_blank'>Montréal Biodôme</a>! Read more at the links below." article = "<p style='text-align: center'><a href='https://arxiv.org/abs/1512.03385' target='_blank'>Deep Residual Learning for Image Recognition</a> | <a href='https://github.com/pytorch/vision/blob/main/torchvision/models/resnet.py' target='_blank'>Github Repo</a></p>"
# Run inference
frontend = gr.Interface(inference,
inputs,
outputs,
examples=[“test1.jpeg”, “test2.jpeg”],
title=title,
description=description,
article=article,
analytics_enabled=False)
# Launch app and set PORT
frontend.launch(server_name=”0.0.0.0″, server_port=7860)
When the web UI is running, it will look like:

Dockerize the frontend: Now, you’d want to also run the frontend application inside of another docker container.
Why? Because we can. Kidding hahah!
This is because let’s say you want to use the API endpoint for different use cases such as in a mobile phone or a desktop application etc. It is nice to keep these separate so that, if for some reason, the frontend web UI fails, the backend will not fail with it and vice versa. Note that there will be scenarios where you’d want them to run in the same container.
Similar to the backend, you will need to make another requirement.txt that has modules needed for the frontend to work.
gradio requests
And, another Dockerfile to set up the necessary dependencies.
# Use an official Python runtime as a parent image FROM python:3.9-slim
# Copy the requirements file into the image
COPY ./requirements.txt /app/requirements.txt
# Set the working directory to /app
WORKDIR /app
# Install any needed packages specified in requirements.txt
RUN pip install -r requirements.txt
# Copy every content from the local folder to the image
COPY . .
# Run server, deafult gradio url is http://127.0.0.1:7860
CMD [ “python3”, “-u”, “/app/main.py” ]
Next, you can build and run the container using:
# build docker build -t frontend_serving . # run container docker run -p 7860:7860 --add-host host.docker.internal:host-gateway --name frnt-serve frontend_serving
The frontend application is live in http://0.0.0.0:7860/ on your local machine. That’s it. Now you can play with the app and give it your own images and see what it says.
Launch the application in two lines
If you simply want to play with the application, I’ve made the docker images public on Docker Hub, and you can run the app with 2 lines of code. First, to copy the command. Second, press enter!
git clone https://github.com/hasibzunair/imagercg-waiter cd imagercg-waiter/backend # this line does not count! sh deploy.sh
The app is live in http://0.0.0.0:7860/ on your local machine. Or, if you simply want to play with the app from your browser, go here.
Conclusion
In this post, you learned how to build and run a full-stack ML application using PyTorch, FastAPI, and Gradio while ensuring replicability and reproducibility using Docker. You built custom docker images for the front and backend, and created a communication link between them using an API endpoint. Finally, as a user, you upload your images to the app that calls the API endpoint to make a prediction and then show the results.
I did this project after completing Docker for the Absolute Beginner — Hands On — DevOps. What have you built after finishing an online course or learning a new skill? Share in the comments!
Aloha! I am a Ph.D. candidate at Concordia University in Montreal, Canada, working on computer vision problems. I also work part-time at Décathlon, where I help build data-driven tools to transform sports images and videos into actionable intelligence. If you’re interested to learn more about me, please visit my webpage here.
References
[1] He, K., et al. “Deep residual learning for image recognition”. In CVPR, 2016.
[2] Deng, Jia, et al. “ImageNet: A large-scale hierarchical image database,” In CVPR, 2009.
Join thousands of data leaders in the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts
")



")


