



Adversarially-Trained Deep Nets Transfer Better
Last Updated on August 1, 2020 by Editorial Team
Author(s): Francisco Utrera
Machine Learning
What is the practical impact?
We discovered a novel way to use adversarially-trained deep neural networks (DNNs) in the context of transfer learning to quickly achieve higher accuracy on image classification tasks — even when limited training data is available. You can read our paper at https://arxiv.org/abs/2007.05869.
What is adversarial training?
Adversarial training modifies the typical DNN training procedure by adding an adversarial perturbation δᵢ on each input image xᵢ with the objective of generating DNNs robust to adversarial attacks. In particular, for a DNN with m input images, a loss function ℓ(⋅), a model-predicted response h(⋅) parametrized by θ, and the true label for the iᵗʰ image yᵢ, the optimization objective of adversarial training is described mathematically in Equation 1. For more details, please see Section 3: “Explaining the Adversarial Training Process” in our paper.
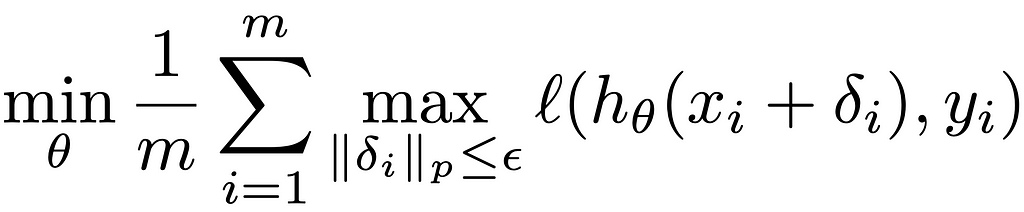
What is transfer learning in the context of DNNs?
Transfer learning typically trains DNNs on a rich dataset like ImageNet and then re-trains (fine-tunes) some of the last layers with the target dataset. Empirically, this method allows us to obtain higher accuracy than DNNs trained from scratch, as it was first shown by Yosinski et. al. in How transferable are features in deep neural networks? [2]. Also, this higher accuracy is attained much quicker compared to DNNs trained from scratch.
What motivated us?
Two key insights explained in Tsipras et. al. Robustness may be at odds with accuracy [1]:
- Adversarially-trained DNNs typically have lower test accuracy than naturally-trained models. However,
- Adversarially-trained DNNs tend to have more humanly aligned features, as we explained below in the “Why does this work” Section below. Thus, we wondered:
Is it possible that these humanly-aligned representations will give adversarially-trained models an advantage over naturally-trained ones when they’re fine-tuned to new datasets?
What is our experiment and what are our results?
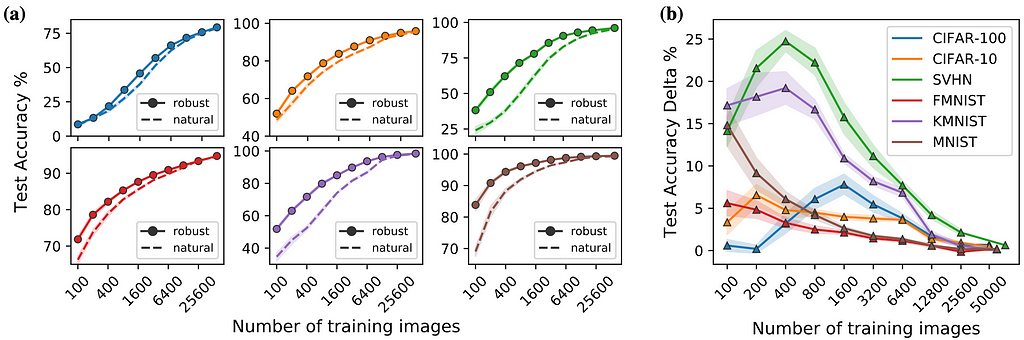
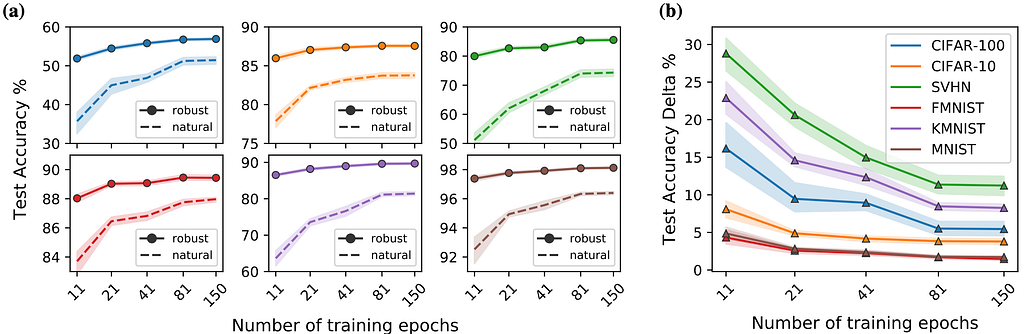
We comprehensively study the testing accuracy obtained from naturally fine-tuning ResNet-50 models originally trained on ImageNet either adversarially or naturally. After fine-tuning 14,400 models over 6 different variables, we concluded that adversarially-trained DNNs learn faster and with less data than naturally-trained ones. In some cases, we see a 4x reduction in training images and a 10x speedup in training speed to achieve the same accuracy benchmark as a naturally-trained source model.
Figures 1(a) and 2(a) show the test accuracy on each of the target datasets as a function of the number of training images and training epochs used for fine-tuning, respectively. Figures 1(b) and 2(b) show the test accuracy delta, defined as the robust minus the natural test accuracy on the target datasets. Both (a) and (b) are consistently colored by dataset, the shaded area shows the 95% confidence interval, and the points are the mean over multiple random seeds. For more details, please see Section 5: “Results and Discussions” in our paper.
Has anyone else studied this?
To the best of our knowledge, there are only two papers that study this phenomenon directly:
- In Adversarially Robust Transfer Learning [3], Shafahi et. al. found that adversarially-trained models transferred worse than naturally-trained. However, this seemingly contradictory conclusion can be explained by the fact that they used much larger robustness levels than us: They use ε=5 while we use ε=3.
- Microsoft Research and MIT came to a similar conclusion in their very recent paper Do Adversarially Robust ImageNet Models Transfer Better? [4] and a related blogpost by Salman et.al. They focus on the effects of different network architectures, fixed feature transfer, and comparing adversarial robustness to texture robustness.
Why does this work?

To give some insight into the question of why robust transfer learning works, we can look to human perception. When we perceive objects in real-life, we infer the label of the object from the semantic properties of the object being viewed. So, for instance, when given the task of identifying the object in Figure 3, most people recognize that the tall ears, elongated snout, and brown fur pattern allude to the object being a German Shepherd dog. What makes this method of cognition powerful is that it allows humans to learn to recognize a vast amount of objects. After learning to spot German Shepherds, one may have an enhanced ability to recognize wolves, since they share visual properties.
Consider that the dog image in Figure 3 is fed into a naturally-trained DNN and into an adversarially-trained DNN. How does each network internally represent this image? This can be visualized in Figure 4, which shows the sensitivity of the loss function given a small change in the pixels of the input image of the dog. The loss function measures how “good” are the predictions of our model. The left image shows a highly irregular and non-smooth representation, while the right one shows a representation that is humanly recognizable as a dog. Intuitively, we can say that the adversarially trained model sees the forest (i.e., features such as ears, eyes, arms, etc.), while the naturally trained model is lost in the trees (i.e. the image pixels).

We can also investigate this phenomenon from the perspective of influence functions, as described in Koh and Liang’s Understanding black-box predictions via influence functions paper [5], which essentially ask:
Which images from the training dataset are most helpful for classifying this input image?
Since adversarially-trained models contain human aligned features, we expected that the most influential images for an input image to actually look similar to the input image. We obtain results that are consistent with this theory.

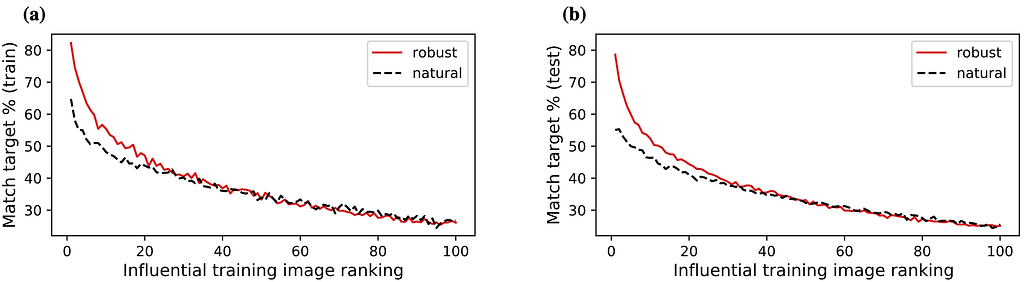
Figure 5 shows a collection of test images for a transferred DNN, with the most influential training images in the target dataset shown for both adversarial and natural trained source models. It is clear that the robust models produce the most influential images that appear more similar to the test image compared to the naturally trained source models. Figure 6 extends the notion shown in Figure 5 to quantitatively measure how much better the adversarially-trained DNN is compared to the naturally-trained DNN. In particular, it shows that highly influential images get classified correctly more often in robust models. These results show that similar-looking images get grouped together in the feature space of adversarially-trained source models, indicating that adversarially-trained models have internal feature representations better aligned with human cognition. For more details, please see Section 6: “Interpreting Representations using Influence Functions” in our paper.
How can you use this?
In contrast to many other complicated and non-standard training procedures, our adversarial transfer learning procedure is easy to implement.
The first step is to acquire an adversarially-trained ImageNet model, either through a 3rd party or with scratch adversarial SGD training (for more details, please see Section 3: “Explaining the Adversarial Training Process” in our paper). We recommend using the models from the robustness library linked in the README.txt. Next, re-initialize the last fully-connected layer and then fine-tune the model using the target dataset as described in Section 4 of our paper.
Lastly, we’d like to share some tips and tricks learned as we fine-tuned more than 14,000 models:
- If you have less training data, fine-tune fewer layers to avoid overfitting
- Consider using our hyperparameters as a starting point and perform grid-search to improve accuracy by ~1–3%
- Adversarially-trained models with an ℓ-2 norm worked best for us
- Keep in mind that this method should work fairly well even in the low data regime
To see the code associated with our research, check out our GitHub.
What’s next?
From a practical standpoint, we’re interested in finding ways to further increase the transfer learning accuracy and/or reduce the computational expense required to train the source model adversarially. Different source models and architectures could have a big impact on the behavior of the transfer learning process. Also, while ImageNet has become common in transfer learning as a source dataset, there are many issues with the dataset that might be at odds with transfer learning. Some issues with ImageNet include overlapping labels in images, insufficient dataset length, low-resolution photos, and outdated images (by today’s standards). Some datasets have attempted to address these concerns. In 2019, Tencent released a publicly available dataset containing 18 million images and 11 thousand classes, making it the largest annotated image dataset in the world.
From a theoretical standpoint, we should explore why this phenomenon occurs in the first place. Even though we’ve looked at robust transfer learning behavior through the lens of influence functions, we cannot definitively explain why adversarially-trained models transfer better. It’s possible that this phenomenon is related to representation-based learning and/or semi-supervised learning. Perhaps we can leverage some of the theory in these related fields to gain an even deeper understanding that explains why adversarially-trained DNNs transfer better.
Acknowledgments
I’d like to thank my blog co-author Evan Kravitz, as well as helpful comments and edits from Benjamin Erichson, Rajiv Khanna, and Michael Mahoney.
Sources
[1] Dimitris Tsipras, Shibani Santurkar, Logan Engstrom, Alexander Turner, and Aleksander Madry. Robustness may be at odds with accuracy. ICLR (2019).
Relevance to our work — Adversarially-trained models underperform naturally-trained ones when they’re evaluated on the same source dataset (i.e. not transferred). However, “the representations learned by robust models tend to align better with salient data characteristics and human perception”.
[2] Jason Yosinski, Jeff Clune, Yoshua Bengio, and Hod Lipson. How transferable are features in deep neural networks? NeurIPS (2014).
Relevance to our work — Landmark transfer learning paper finding that “initializing a network with transferred features from almost any number of layers can produce a boost to generalization that lingers even after fine-tuning to the target dataset”.
[3] Ali Shafahi, Parsa Saadatpanah, Chen Zhu, Amin Ghiasi , Cristoph Studer. Adversarially Robust Transfer Learning. ICLR(2020).
Relevance to our work — First paper studying transfer learning of adversarially-trained DNNs showing that DNNs trained with a high tolerance for adversarial perturbations (i.e. ε=5) do not transfer as well as naturally-trained models [Table 3].
[4] Hadi Salman, Andrew Ilyas, Logan Engstrom, Ashish Kapoor, Aleksander Madry. Do Adversarially Robust ImageNet Models Transfer Better? ArXiv (2020)
Relevance to our work — Most recent work further validating our conclusion that Adversarially-trained models transfer better by analyzing different network architectures width, fine-tuning the entire DNN, and fixed feature transfer.
[5] Pang Wei Koh and Percy Liang. Understanding black-box predictions via influence function. ICML (2017).
Relevance to our work — Provides the influence function framework we used to better understand why Adversarially-trained models transfer better.
Adversarially-Trained Deep Nets Transfer Better was originally published in Towards AI — Multidisciplinary Science Journal on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

