


 🧟♂️")
A Visual Walkthrough of DeepSeek’s Multi-Head Latent Attention (MLA) 🧟♂️
Last Updated on June 23, 2024 by Editorial Team
Author(s): JAIGANESAN
Originally published on Towards AI.
A Visual Walkthrough of DeepSeek’s Multi-Head Latent Attention (MLA) 🧟♂️
Exploring Bottleneck in GPU Utilization and Multi-head Latent Attention Implementation in DeepSeekV2.
In this article, we’ll be exploring two key topics. First, we’ll discuss and understand the bottleneck problems that transformer models, also known as Large Language Models (LLMs), encounter during training and inference.
Then, we’ll delve into a specific bottleneck issue in LLM architectures regarding KV cache, and how DeepSeek’s innovative approach, Multi-Head Latent Attention, addresses this problem.
Disclaimer 🛑: This article is not sponsored or affiliated with DeepSeek in any way. The content is inspired by publicly available information.
The topics we’ll be covering in this article are:
✨ The bottleneck problem in GPU processing
🪄 Multi-Head Latent Attention (MLA)
1. The bottleneck problem in GPU processing: 🦈
In recent years, there has been a surge in research and investment in Graphics Processing Units (GPUs). In fact, when I wrote this article, I came across the news that NVIDIA had become the second most valuable public company, with a staggering valuation of $3 trillion.
But why is that? The answer lies in the fact that AI models need to run lots of mathematical operations, and GPUs are instrumental in making that happen to run faster. They have become incredibly efficient at performing calculations, and, unsurprisingly, they’re in high demand.
GPUs have become too fast. They can perform calculations at an incredible rate, measured in floating-point operations per second (FLOPs).
But there’s an issue— the speed of computation has far outpaced the memory bandwidth (GB/s), which is the speed at which data is transferred between different memory areas in GPUs. This mismatch has created a bottleneck that slows down the entire process.
To help illustrate the bottleneck problem, let’s take a look at images 1 and 2.
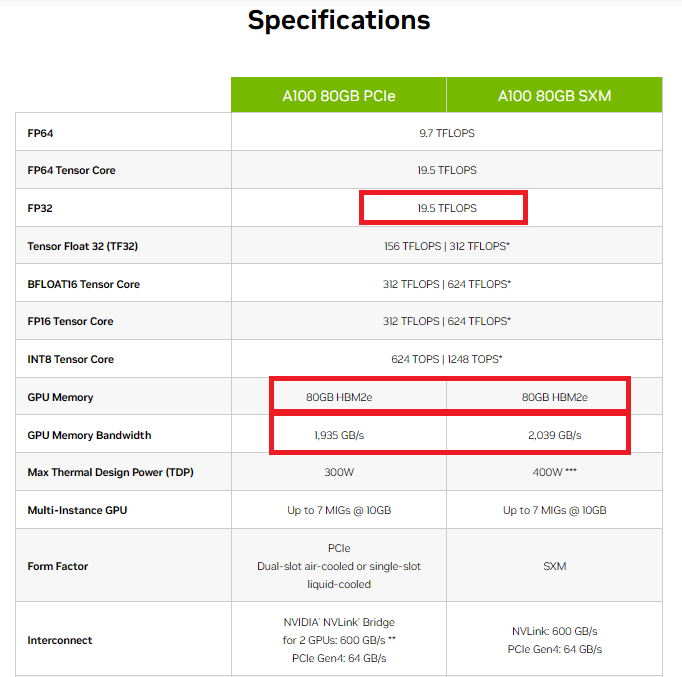
Image 1 shows the specifications of NVIDIA’s A100 GPU. As you can see, this powerful GPU can perform an impressive 19.5 TFLOPs (tera floating-point operations) in FP32 mode. However, its GPU memory bandwidth is limited to around 2 TB/s. Though these two are two different things, there is a connection.
This highlights a crucial point, the bottleneck isn’t always about how many operations we can perform, but rather how quickly we can transfer data between different parts of the GPU. If the number of data transfers increases with high memory the latency will also increase.* The size and quantity of tensors involved in our calculations play a significant role in this.
For example, computing the same operation on the same tensor multiple times might be faster than computing the same operation on different tensors of the same size. This is because the GPU needs to move the tensors around, which can slow things down. So, our goal shouldn’t just be to optimize the number of operations (KV cache, MQA, GQA) we perform but also to minimize the memory access and transfers we need to make.
Image 2 will help clarify these concepts and give you a better understanding of how these operations work. Image 2 illustrates how Attention operation happens in GPU.

Now that we’ve explored the bottleneck problem, it’s clear that it can significantly increase latency. To tackle this issue and reduce latency during inference, researchers have proposed various approaches, including flash attention, multi-query attention, grouped query attention, KV cache method, rolling buffer KV cache, and more. Even the recently popularized method, MAMBA, addresses this problem indirectly.
Take a closer look at Image 1, and you’ll notice that the GPU memory is 80 GB HBM2e (High Bandwidth 2nd Generation enhanced). However, when training and inferencing large language models (which have grown exponentially in parameters in recent years, especially with the rise of LLM and multi-modal models), this HBM memory can quickly become a limiting factor, creating a bottleneck in the process and increasing latency.
1.1 So, what bottleneck problem does DeepSeek address? 😵💫😵
As we’re all aware, KV cache inference is a solution that helps reduce the computational load in the attention mechanism (The vanilla transformer — attention is all you need paper architecture). It works by caching tokens in Key and value to generate the next token. However, in real-life scenarios where we’re dealing with long sequences, the KV caches become extremely large and memory-intensive. This limits the maximum batch size and sequence length, creating a bottleneck.
In an effort to solve this bottleneck and reduce latency, the researchers at DeepSeek came up with a new approach called Multi-Head Latent Attention. This new method aims to mitigate the bottleneck problem and speed up the inference process.
2. Multi-Head Latent Attention (MLA) 🧞♂️🧞♂️
I assume you are familiar with self-attention and multi-head attention in large language models. If not, please familiarize yourself with these concepts.
Large Language Model (LLM)🤖: In and Out
Delving into the Architecture of LLM: Unraveling the Mechanics Behind Large Language Models like GPT, LLAMA, etc.
pub.towardsai.net
In simple terms, researchers have made a breakthrough with multi-head latent attention by reducing the space complexity, or memory usage, to decrease time complexity, ultimately leading to lower latency.
I want to give a small description of what a Latent vector is. A latent vector represents an underlying or unobservable factor influencing or contributing to a model's observed data or outcome.
In some models, like Mistral, the dimension of the model is set to 4096. This means that all vectors, layer outputs, and embedding dimensions will be the same size as the model dimension.
However, researchers working on DeepSeek took a different approach. They reduced the model dimension to store the KV cache efficiently.
For example, they shrunk the vector dimension from 4096 to 1024. This allows the KV cache to store in the 1024 dimension, while other layers still use the original model dimension. Let’s dive deeper into how this works, both mathematically and visually.

The architecture of multi-head latent attention is shown in Image 3. This architecture shows how the latent vector is created and how the hidden input is passed through the RoPE (Rotary Positional Embedding) module.
2.1 Low-Rank Projection

""" I want to Give a Latent vector illustration with model dimension of 4096
and Latent dimension of 1024 """
# dim = 4096 , latent_dim = 1024
self.c^KV_t = nn.Linear(dim, latent_dim, bias=False) # Equation 1
self.k^C_t = nn.Linear(latent_dim, dim, bias=False) # Equation 2
self.v^C_t = nn.Linear(latent_dim, dim, bias=False) # Equation 3
The core idea behind MLA (Multi-Head latent attention) is the low-rank joint compression for key and value to reduce the KV cache.
Note: (1) In this example, I’ve used a latent vector size of 1024 for simplicity. (2) The numbers you see in the images (illustration images) are just random examples and don’t represent actual numbers in the model. (3) The weight matrices shown in the images and equations are learnable parameters, which means they get updated during the backpropagation in training.
c^KV_t is a Compressed Latent Vector for keys and values (Equation 1). This is a Lower-dimensional representation of the original key and value vectors. (As I mentioned earlier this dimension will be like 1024 (d_c — Compressed dimension), The Latent vector is low compared to the model dimension. It is Cached during Inference.
In Equation 1 from Image 4, the down-projection weight Matrix W^DKV projects the input vector(h_t) from a model dimension (4096) to a latent dimensional (1024).

Image 5: illustrates Equation 1 in Image 4. I took 9 tokens with a model dimension of 4096
When we’re making predictions with our model (inference), we don’t need to store the original high-dimensional key and value vectors. Instead, we can store a compressed latent key and value vectors, called c^KV_t. This is much more efficient because c^KV_t has only 1024 elements (Each vector), compared to the original 4096(model dimension) elements. This approach reduces the amount of memory we need and also speeds up the process.
The equations shown in image 4 (equations 2 and 3) are used to up-project the compressed key and value vector representation(c^KV_t). This means we’re taking the compressed latent vector and projecting it back into the model dimension.
The resulting key and value vectors, k^C_t and v^C_t, are now in the model dimension (h_d * n_h). We achieve this up-projection using linear layer weight matrices W^UK and W^UV.
But, During inference the up-projection matrices W^UK and W^UV can be absorbed (Associative law of matrix multiplication) into the query(W^Q) and output(W^O) projections matrices, eliminating the need to compute keys and values explicitly.
This approach is different from the traditional method where we project the key and value vectors separately and then multiply them with the head’s weight matrices, such as W^Q, W^K, and W^V. Instead, we project the k^C_t and v^C_t directly into the heads’ key and value matrices. I will illustrate this with the image below.

From Image 6 you can understand that the lower dimensional kv representation(c^KV_t) is projected into 32 Value and 32 key vectors with each size of (9, 128) using two weight matrices (W^UK) and (W^UV). W^UK and W^UV size is ( d_h X n_ h X d_c (latent vector dimension)). These queries and Values are used in Multi-head attention.
d_h → Head’s dimension, n_h → Number of heads
Note: I Projected again into the model dimension. But We can Up Project into any dimension( d_h X n_ h) as needed. But It will affect the Attention layer output projection. So we may need an adjustment in the output weight matrix to project into the model dimension.
Now we need to look into the Query Compression

In Image 7, Equation 4 denotes that the query is compressed into Latent vector space(From 4096 to 1024). and Equation 5 is the up-projection Equation (From 1024 to d_h X n_h).
Equations 4 and 5 are the same as the illustration you have seen in Images 5 and 6.
Till now we have seen the Down Projection and Up projection of Query, key, and Value vectors. But We have to see one important topic, how we integrate the Rotary positional Embedding into these vectors.
2.2 Decoupled Rotary Positional Embedding
RoPE (Rotary Positional Embedding) introduces the positional information to the keys and queries by rotating the vectors in multi-dimensional space. RoPE is Both Relative and absolute.
I will give a simple illustration, of how RoPE rotates the vectors.

Image 8 gives the equation about how the vector got rotated in 2-dimensional space. m is the position of the token/ vector in the sequence. theta is the angle (same for all tokens/vectors). The rotation matrix (cos m.theta, sin m.theta) is usually detonated as r.

In Image 9, I took an example sequence as we enjoy music. In this sequence, ‘we’ is 1st token so Position m becomes 1 and for enjoy and music position becomes 2 and 3. Theta is the same for all vectors. In most of the architecture (python), sequence position starts with 0, for illustrating how vector rotation happens in 2 dimensions I have taken the position from 1.
We Only Rotate the Vector using the RoPE method. We know vectors have magnitude and direction. In RoPE we only change the direction by the angle of m * theta, and the magnitude of the vector remains the same. It gives both absolute (Position of that particular token) and relative (Position with respect to other tokens in the sequence) Positional information to key and value vectors. This enhances the attention output.
We only Rotate the Query and Key, Not the Value vectors. So Rotary positional Embedding helps to enhance the attention mechanism between inputs. In vanilla transformer architecture there is a Problem, It adds the positional information(sinusoidal function) to Word embeddings, which changes the magnitude of all vectors, Even the same words have different vectors(different magnitude) in the Input.
But in RoPE the same words Magnitude didn’t change after the rotation. The rotation gives the information, so the attention between the vectors has enhanced attention (Semantic and syntactic relationship) output. But Value vectors didn’t go through any rotation (True word embeddings), so the attention layer output has rich information about the sequence of tokens.
But there is a problem When RoPE is position-sensitive for both keys and values. If we apply RoPE in equations 1 and 2 (Image 4), It will be coupled with position-sensitive weight matrices. As a result, W^UK cannot be absorbed into W^Q anymore because the multiplication does not commute. This requires recomputing the keys for all prefix tokens during inference, which is inefficient.
To address this, a decoupled RoPE strategy is proposed. This strategy uses additional multi-head queries and shared keys to carry the RoPE information separately from the compressed keys and queries. Then these decoupled RoPE queries and Keys are concatenated with Up-projected Queries and keys.

Image 10: W^QR and W^KR are weight matrices to produce the decouples Queries and key as shown in Equations 6 and 7. RoPE (.) denotes an operation that applies RoPE Rotation matrices, as You can compare with Image 8. Equations 8 and 9 denote the Concatenation of Decoupled RoPE applied Queries and Key vectors with Up-projected query and key vectors.
Note: The RoPE didn’t change the magnitude or dimension of the vector. The Weight matrices W^QR and W^KR change the input vector compatible for q^C_t and k^C_t.
The size of q^R_t and k^R_t will be less dimension compared to latent vectors. The size will be (d^R_h * n_h) for queries (n_h RoPE vectors) and d^R_h for key. q^R_t is calculated from a compressed query vector c^Q_t. But k^R_t is calculated from the input vector h_t itself.
The concatenation preserves the positional information in both queries and key. The Query and Key vectors should be in the same dimension to happen attention operation as shown in Image 11.

Image 11: u_t is nothing but an attention layer output with the model dimension. W_O weight matrix attention Layer output projection matrix.
2.3 comparing the key-value cache with other methods 🤼
To Prove Multi-Head Latent attention works better, researchers at DeepSeek Compared KV cache Per token among different attention mechanisms as shown in Image 12. We can understand that only a small amount of memory for KV cache is required for MLA, But it can achieve stronger performance than MHA (Multi-Head Attention).

Image 12: n_h denotes the number of attention heads, d_h is the dimension of attention heads, l denotes the number of decoder layers in the LLM architecture, and n_g is the number of groups in Grouped query attention.
Complete Computation process of MLA (Summary):
📌 Equation 4 (Image 7) → The input vector(h_t) is projected into the latent dimension (compressed version for queries).
📌 Equation 5 (Image 7) → The latent vector is then projected into multiple queries( Multiple Heads).
📌 Equation 6 (Image 10) → To Capture the Positional Information of input vectors for queries, the Researcher used Decoupled Rotary Positional Embeddings that create Positional vectors.
📌Equation 8 (Image 10) → The Positional Vectors are concatenated with queries
📌 Equation 1 (Image 4) → The input vector(h_t) is projected into the latent dimension (compressed version for keys and Values) [Cached During inference].
📌 Equation 2 (Image 4) → The latent vector for keys and Values projected into compressed keys using a linear layer weight matrix.
📌 Equation 7 (Image 10) → For Positional Information for keys, The RoPE has been applied to the input vector (h_t) to create the Positional Vectors [Cached During Inference].
📌Equation 9 (Image 10) → The Positional Vectors are concatenated into compressed key vectors.
📌 Equation 3 (Image 4) → The Latent vector for Keys and Values is projected into compressed value vectors using a linear layer weight projection matrix.
📌 Equation 10 (Image 11) → The attention Mechanism happens in all heads.
📌 Equation 11 (Image 11) → Attention heads are Concatenated. This Concatenated output is then Linearly projected using a weight Matrix called W_O.
📌 The Final output is then fed into the MoE (Fine-grained expert and shared Expert isolation) Layer.
I wrote a series of articles exploring new innovative approaches in LLM. Actually, this article is a continuation of my Previous Article, Where I explored DeepSeek's Innovation in the Mixture of Experts (Fine-Grained Expert and Shared Expert Isolation) that solves the knowledge hybridity and knowledge redundancy in Existing MoEs’ if you want to know more check out this article.
Revolutionizing AI with DeepSeekMoE: Fine-grained Expert, and Shared Expert isolation 🧞♂️
Optimizing MoE with Fine-Grained and shared expert isolation for enhanced precision and efficiency in Large Language…
pub.towardsai.net
I conclude this article. I believe I have made you understand how MLA Works. If you don’t understand, reread it or read the original research paper. I am just trying my best to give you my perspective and what I have understood.
Thanks for reading this article 🤩. If you found my article useful 👍, give it a clap👏😉! Feel free to follow for more insights.
Let’s keep the conversation going! Feel free to connect with me on LinkedIn: www.linkedin.com/in/jaiganesan-n/ 🌏❤️
and join me on this exciting journey of exploring AI innovations and their potential to shape our world.
References:
[1] DeepSeek-AI, Aixin Liu, Bei Feng, Bin Wang, Bingxuan Wang, Bo Liu, Chenggang Zhao, Chengqi Dengr, DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model (2024), Research paper (arxiv)
[2] Flash Attention Conceptual Guide, Huggingface.co
[3] Exploring the GPU Architecture, vmware.com
[4] Jianlin Su, Yu Lu, Shengfeng Pan, Ahmed Murtadha, Bo Wen, Yunfeng Liu, RoFormer: Enhanced Transformer with Rotary Position Embedding (2021), Research Paper (arxiv)
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

