


Zomato Sentiment Analysis
Last Updated on July 15, 2023 by Editorial Team
Author(s): Roli Trivedi
Originally published on Towards AI.
A Journey through EDA and Data Preparation
In this article we will define the objective, Load data, Perform Exploratory Data Analysis and do data preparation
Steps to be followed for our model :
- Define the objective of the problem statement.
- Data Gathering
- Exploratory Data Analysis(EDA)
EDA is basically where we use techniques to understand the data better to give visual representation to other - Data Preparation
Data might not be in the correct format. There might be outliers or missing values. So you need to scan the set of inconsistencies and fix them
NOTE: The data Preparation step and EDA goes hand in hand - Build Machine Learning model
- Model Evaluation & Optimization
- Prediction/ Deployment
Now, it’s time to dive into the implementation!
Objective
The project aims to analyze Zomato restaurant data in India to understand customer sentiments through reviews and visualize the data for insights.
Load Libraries
Dataset: Link
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
import warnings
warnings.filterwarnings("ignore")
import datetime as dt
from wordcloud
Load data
review = pd.read_csv("Zomato Restaurant reviews.csv")
Exploratory Data Analysis
More than anything, EDA is the state of mind. It is the first step you can perform before making any changes to the dataset. The process of EDA contains contain summarizing, visualization, and getting deeply acquainted with important traits of the dataset.
What does data look like?
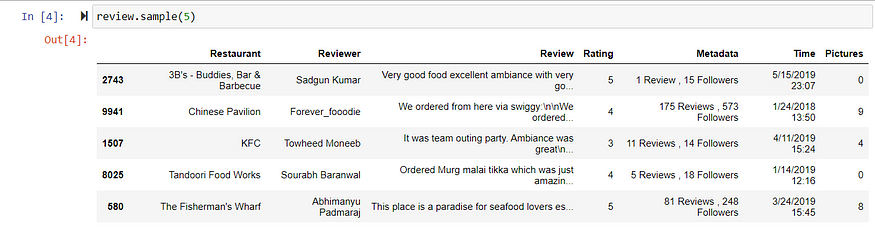
review.random(5): to get random 5 records
review.tail(): to get the last 5 records
review.head(): to get first 5 records
Metadata contains the number of followers and reviews on restaurants.
How big is the data?

There are 10000 records(or reviews) given with 7 features.
Columns in our dataset

What is the data type of columns?
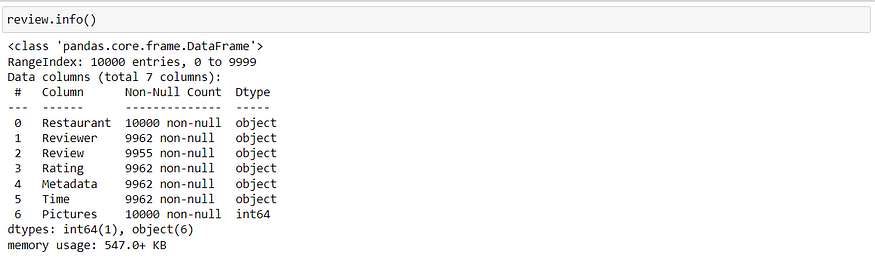
It gives us non-null count and datatype information. Also, given how much it is occupying space in memory
What does mathematically our data look like?
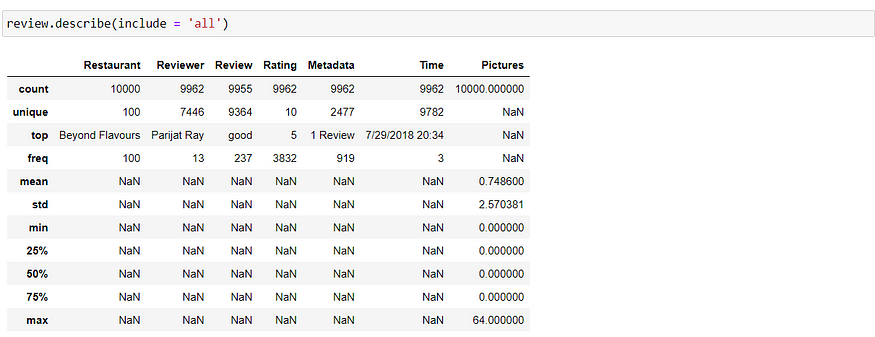
Are there any duplicates?

We have 36 duplicates. Let’s have a look at its duplicates
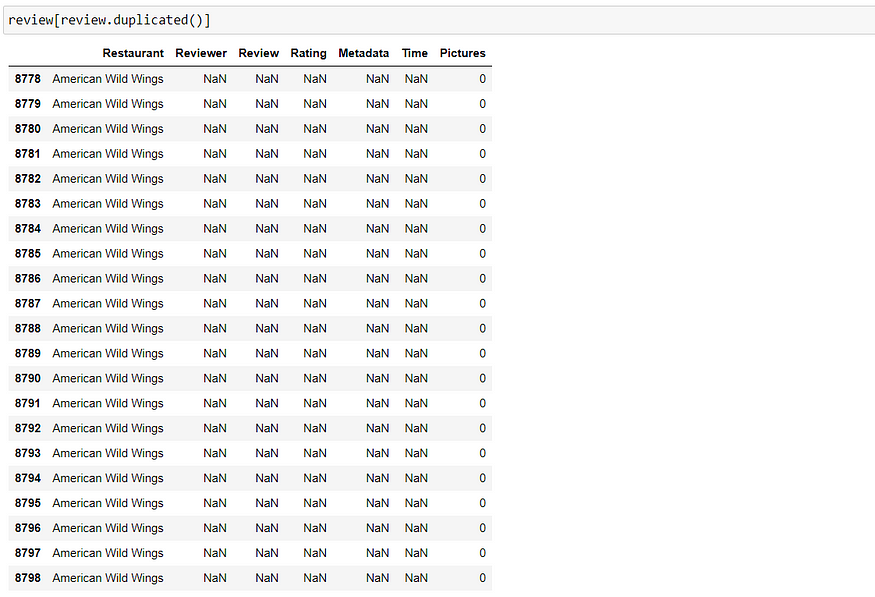
Since all the duplicated rows are null values. We can drop them off later when we do preprocessing.
Are there any missing values?
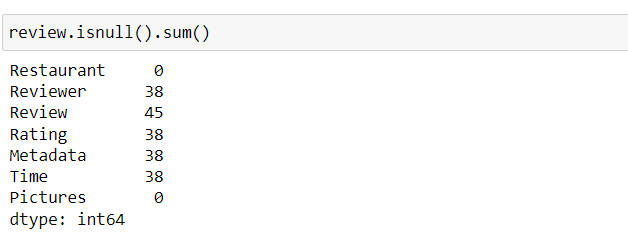
We have many null values.
Check Unique Values for each variable in the review dataset.

We will check the unique value for rating as we have 10 unique ratings

The ratings are given by the customer as 1,1.5,2,2.5,…5, and ‘like’ while there are some missing values.
Findings:
- The rating should be an integer, but it contains the value ‘like,’ indicating that it is of the object data type.
- Timings are provided in text format, making them an object data type.
- We have duplicate values, but since they are null values, we can eliminate them.
- The dataset consists of a total of 10,000 reviews, encompassing 7 features.
- With the exception of restaurant names and the number of pictures posted, most values are null.
- Based on the review dataset’s description, we can deduce that 100 restaurants have received customer reviews.
- The rating can be considered a categorical variable ranging from 0 to 5. We can replace missing values with the median rating for that specific restaurant. Since ‘like’ is not a rating, we can replace it with a rating of 4, as it represents people like the taste.
- Customers have posted pictures with 36 distinct values.
Data Preparation
You must have noticed you had not done any cleaning or transformation by the time we finished the EDA section. However, we have determined what cleaning is required and what needs to be cleaned.
Note: Feature Engineering is the data preprocessing step. It basically makes raw data into more meaningful data or data that can be understood by ML.
Drop duplicate values as they are null
review.drop_duplicates(inplace = True, keep = False)
inplace = True: we are modifying the DataFrame rather than creating a new one.
keep = False: dropping all duplicates
Replace Rating ‘Like’ with rating 4 and convert the column to float type
Note: Series.str can be used to access the values of the series as strings and apply several methods to it
review['Rating']=review['Rating'].str.replace("Like",'4').astype('float')

Fill null values in the ‘Followers’ column with 0
review['Followers'].fillna(0,inplace = True)
Convert the column “Time” to datetime and extract the hour and year
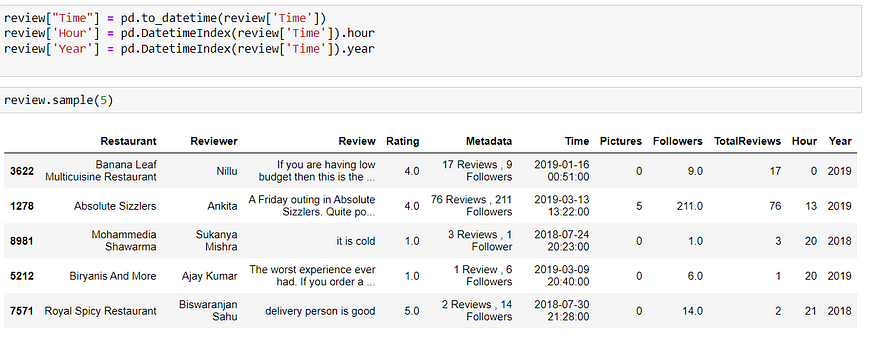
Now we have null values in the ‘Review’ column only therefore we can drop them as we do not require records with no reviews. (Since the number of missing values was less in number, therefore, it didn’t affect )
Splitting the metadata into Reviews and Followers
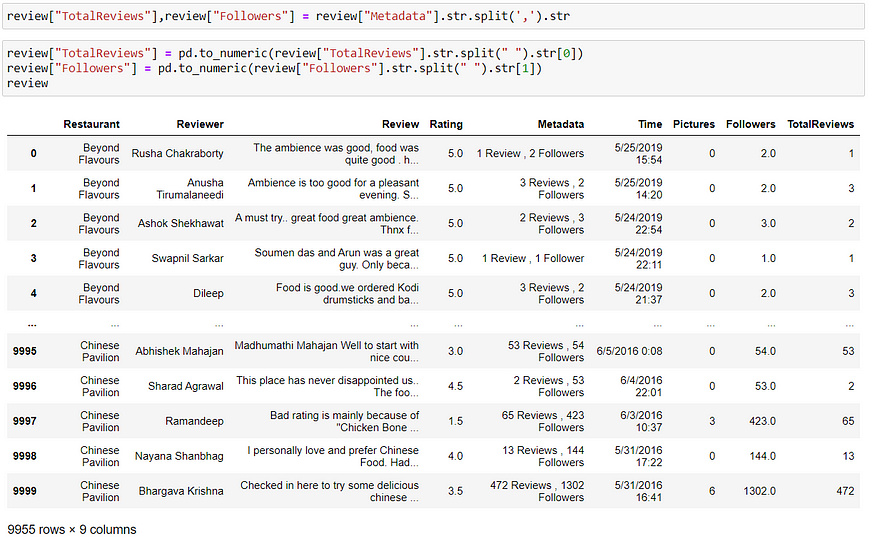
Replacing Missing Values in “Followers” with 0 and converting Time to date time, extracting Hour and year
review['Followers'].fillna(0,inplace = True)
review["Time"] = pd.to_datetime(review['Time'])
review['Hour'] = pd.DatetimeIndex(review['Time']).hour
review['Year'] = pd.DatetimeIndex(review['Time']).year
Average rating and the total number of reviews given to restaurants
avg_rating = review.groupby('Restaurant').agg({'Rating' : 'mean', 'Reviewer' : 'count'}).reset_index().rename(columns = {'Reviewer' : 'Total_Review'})
avg_rating

“Thank you for joining me on this journey! Stay tuned for my upcoming updates as we dive deeper into the world of Zomato sentiment analysis. Exciting things are yet to come, so stay connected for the next steps and insights. Together, we’ll unravel the hidden stories within the data. See you soon!”
Thanks for reading! If you enjoyed this piece and would like to read more of my work, please consider following me on Medium. I look forward to sharing more with you in the future.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

