



What Sets GENSIM Apart from Other NLP Tools: A Comprehensive Guide
Last Updated on July 17, 2023 by Editorial Team
Author(s): Tushar Aggarwal
Originally published on Towards AI.
{This article was written without the assistance or use of AI tools, providing an authentic and insightful exploration of GENSIM}
The GENSIM library is an open-source package that provides an efficient and robust implementation of unsupervised topic modeling and other natural language processing functionalities using modern statistical machine learning. This comprehensive guide aims to introduce you to the main features and capabilities of the GENSIM library, including document indexing, retrieval by similarity, and much more. Let’s get started!
Table of Contents
- Introduction to GENSIM
- Installation and Setup
- Document Processing and Tokenization
- Creating a Dictionary and Corpus
- Unsupervised Topic Modeling
5.1 Latent Semantic Indexing (LSI)
5.2 Latent Dirichlet Allocation (LDA)
5.3 Hierarchical Dirichlet Process (HDP)
6. Document Indexing and Retrieval by Similarity
7. Word Embeddings with Word2Vec
8. Doc2Vec: Document Embeddings
9. Text Summarization with GENSIM
10. Additional Resources and Tutorials
1. Introduction to GENSIM
The GENSIM library is a powerful Python package for topic modeling, document indexing, and retrieval by similarity. Developed by Radim Řehůřek, GENSIM offers an extensive set of tools for natural language processing and machine learning. Some of its key features include:
- Unsupervised topic modeling algorithms
- Document similarity analysis
- Word and document embeddings
- Text summarization
- Scalability and efficient memory usage
With the GENSIM library, you can process large volumes of text data and extract valuable insights, making it an essential tool for researchers, data scientists, and developers working in the fields of machine learning and natural language processing.
2. Installation and Setup
To get started with GENSIM, you need to install the library. You can do this using pip:

You may also want to install some optional dependencies for enhanced performance:
Once GENSIM is installed, you can import it into your Python script or notebook:

3. Document Processing and Tokenization
Before diving into the machine learning capabilities of GENSIM, you need to preprocess your text data. This typically involves tokenizing the text into words, removing stop words, and converting words to lowercase. GENSIM provides a utility function called simple_preprocess to help with this task:


This will convert each document into a list of tokens (words).
4. Creating a Dictionary and Corpus
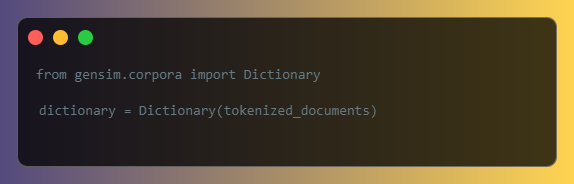
After preprocessing your text data, the next step is to create a dictionary and corpus. A dictionary is a mapping of words to unique integer IDs, which GENSIM uses to represent documents internally. You can create a dictionary using the Dictionary class from the gensim.corpora module:
A corpus is a collection of documents, where each document is represented as a bag-of-words (BoW) vector. You can create a corpus using the doc2bow method of the Dictionary class:

5. Unsupervised Topic Modeling
Unsupervised topic modeling is one of the core features of the GENSIM library. It allows you to uncover hidden patterns and topics within your text data. GENSIM supports several topic modeling algorithms, including Latent Semantic Indexing (LSI), Latent Dirichlet Allocation (LDA), and Hierarchical Dirichlet Process (HDP).
5.1. Latent Semantic Indexing (LSI)
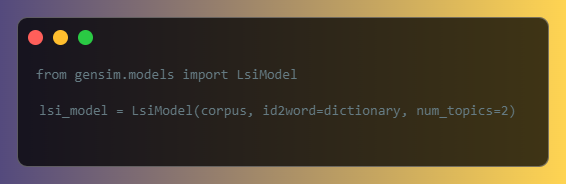
LSI is a linear algebra-based method for unsupervised topic modeling. It uses singular value decomposition (SVD) to identify relationships between words and documents. You can use the LsiModel class from the gensim.models module to create an LSI model:
5.2. Latent Dirichlet Allocation (LDA)
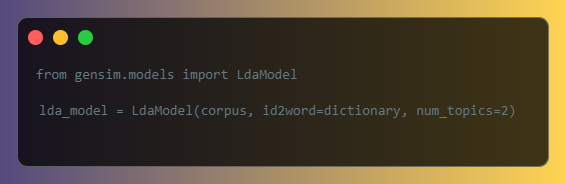
LDA is a generative probabilistic model for unsupervised topic modeling. It assumes that each document is a mixture of a small number of topics, and each word in the document is attributable to one of the document’s topics. You can use the LdaModel class from the gensim.models module to create an LDA model:
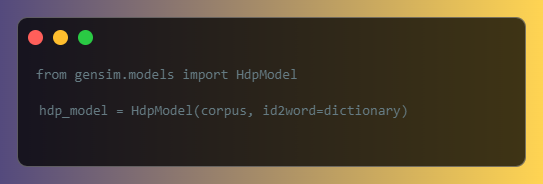
5.3. Hierarchical Dirichlet Process (HDP)
HDP is a non-parametric Bayesian approach for unsupervised topic modeling. Unlike LSI and LDA, HDP does not require you to specify the number of topics beforehand. You can use the HdpModel class from the gensim.models module to create an HDP model:
6. Document Indexing and Retrieval by Similarity
GENSIM provides tools for indexing documents and retrieving similar documents based on their content. The Similarity class from the gensim.similarities the module allows you to perform fast approximate similarity searches. You can create an index using an existing topic model (e.g., LDA, LSI) and query it for similar documents:

7. Word Embeddings with Word2Vec
Word2Vec is a popular algorithm for learning continuous word embeddings from large text corpora. GENSIM provides an efficient implementation of the Word2Vec algorithm using the Word2Vec class from the gensim.models module:

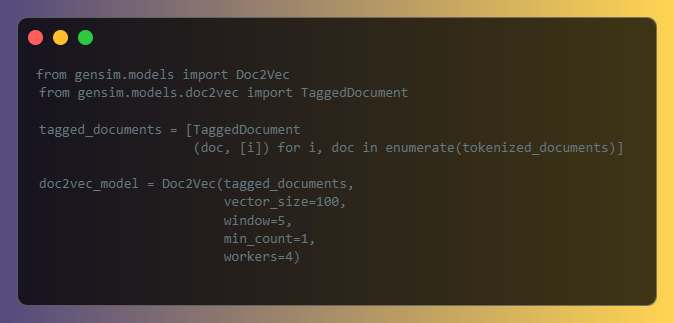
8. Doc2Vec: Document Embeddings
Doc2Vec extends the Word2Vec algorithm to generate continuous embeddings for entire documents. GENSIM provides an implementation of the Doc2Vec algorithm using the Doc2Vec class from the gensim.models module:
9. Text Summarization with GENSIM
GENSIM also provides a built-in text summarization algorithm based on the “TextRank” algorithm. You can use the summarize function from the gensim.summarization module to generate extractive summaries of your text data:

10. Additional Resources and Tutorials
For further information on using the GENSIM library, you can explore the following resources:
This practical guide to the GENSIM library has introduced you to the core features and capabilities of the package, including unsupervised topic modeling, document indexing, retrieval by similarity, and other natural language processing functionalities using modern statistical machine learning. With this knowledge, you can now confidently explore and analyze large volumes of text data using the powerful GENSIM library.
U+1F916I write about the practical use of A.I. and life with it.
U+1F916My country isn’t supported by Medium Partner Program, so consider buying me a beer! https://www.buymeacoffee.com/TAggData
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

