



Unveiling and Addressing Bias in Natural Language Processing
Last Updated on July 17, 2023 by Editorial Team
Author(s): Yunzhe Wang
Originally published on Towards AI.
Understanding and mitigating bias in word embeddings and their implications on AI fairness
The rapid growth of artificial intelligence (AI) and natural language processing (NLP) in recent years has transformed various industries, from healthcare to finance. As AI systems continue to weave themselves into the fabric of our daily lives, ensuring that these systems are fair, transparent, and unbiased becomes increasingly important. Bias in AI and NLP can emerge in different ways — from the data collection and training process to the algorithms' design, and can inadvertently perpetuate or even amplify existing societal biases and stereotypes.
Within NLP, biases can be encoded in word embeddings, which are mathematical representations of words that capture their meaning and semantic relationships. When biases find their way into word embeddings, they can unintentionally affect the AI systems that utilize them, leading to unfair or discriminatory outcomes. For example, gender bias present in word embeddings can reinforce gender stereotypes and contribute to unequal treatment of different genders in AI applications, such as recommendation systems, translation services, and resume scoring.
In this post, we will delve into the various types of biases found in word embeddings, examine the methodologies used to detect them and explore the techniques that can help mitigate or eliminate them.
Identifying Bias in Word Embeddings
The first step in addressing bias in NLP systems is to identify and measure the presence of biases in word embeddings. In the field of psychology, the Implicit Association Test (IAT) has been widely used to measure implicit biases in humans by examining the latency in reaction times to presented pairs of words. For example, the IAT might measure the response times when associating “man” with “math” and “woman” with “art.” The differences in response times can reveal underlying biases in how we perceive and associate these concepts.
In a similar vein, we can apply the concept of the IAT to word embeddings. Word embeddings, such as Word2Vec and GloVe, are trained on large text corpora and encode semantic relationships between words as vectors. These vectors can then be used to perform analogy tests that reveal potential biases in the embeddings. For example, if the analogy “man is to computer programmer as woman is to homemaker” holds for a given word embedding, the model encodes a gender stereotype.

Researchers have developed the Word Embedding Association Test (WEAT) to detect biases in word embeddings systematically. WEAT compares two sets of target words (e.g., male and female names) and two sets of attribute words (e.g., career and family-related words) and tests the null hypothesis that there is no difference in the semantic similarity between the target sets and attribute sets. By permuting all combinations of target sets and attribute sets, WEAT calculates a test statistic that quantifies the degree of association between target and attribute word sets. If there is no bias present, the difference in association scores should not be significant. On the other hand, if a bias is detected, we can identify which pairs of input and target words contribute to the observed bias.
WEAT has successfully identified biases in various dimensions, such as gender, race, and age, in popular word embeddings like Word2Vec and GloVe. The results of these tests have shed light on how biases present in the training data can inadvertently become embedded in the word vectors, leading to the potential reinforcement of stereotypes and discriminatory behavior in AI systems built on top of these word embeddings.
Gender Bias in Word Embeddings
A particularly pervasive form of bias in word embeddings is gender bias, which can have significant implications for AI fairness and the perpetuation of stereotypes. Using the Word Embedding Association Test (WEAT), researchers have uncovered gender biases in popular word embeddings, such as Word2Vec and GloVe, revealing that women are more associated with family-related words, while men are more associated with career-related words.
These findings highlight how cultural history and societal norms can become embedded in the usage and associations of words in a language. As word embeddings are trained on large text corpora, essentially reflections of human language and cultural history, it is unsurprising that they may inadvertently capture and perpetuate existing biases.
One notable implication of these findings is that AI systems built on biased word embeddings can inadvertently reinforce stereotypes and contribute to biased behavior. For example, a machine translation system trained on biased embeddings might translate a sentence about a doctor to use a male pronoun in one language and a female pronoun in another, thus perpetuating gender stereotypes associated with certain professions.
Detecting Bias in Sentence Embeddings
While word embeddings have shown evidence of bias, examining whether these biases are also present in sentence embeddings is crucial. Sentence embeddings are capable of capturing the context and semantics of an entire sentence. Researchers have developed the Sentence Encoder Association Test (SEAT) to detect potential bias in these embeddings.
SEAT is an extension of the WEAT and is applied to simple sentence templates where the target word is inserted. For example, given the template “This is <word>”, it could compare embeddings of sentences like “This is Adam” and “This is Jasmine” to measure potential gender bias. Researchers can identify any inherent biases within the model by analyzing these sentence embeddings.
In addition to examining gender bias, SEAT has been employed to uncover other types of biases. One such bias is the “angry black woman” stereotype, where black women are portrayed as loud, angry, and imposing. Another example is the “double bind” women face in professional settings. This bias states that if women succeed in male-dominated professions, they are often perceived as less likable and more hostile than their male counterparts who perform at a similar level.
It is essential to note that the results of SEAT may not generalize beyond the specific words and sentences used in the dataset. Additionally, cosine similarity, a common metric used to measure representational similarity in word embeddings, may not be suitable for newer models like BERT. Despite these limitations, SEAT provides valuable insights into potential biases present in sentence embeddings and helps us understand how these biases may impact the performance and fairness of NLP systems.
Debiasing Techniques and Their Limitations
In our pursuit of creating fairer NLP systems, various debiasing techniques have emerged to address the biases present in word embeddings. In this section, we will discuss two primary methods for debiasing word embeddings and explore their limitations.
Method 1: Post-processing Debiasing
One approach to debiasing is to process the word embeddings after they have been trained. By defining gender bias as the projection of a word on the “gender” direction, we can zero out the gender component for each word. This method aims to eliminate gender bias by effectively removing gender-related information from the embeddings. However, this technique has its limitations. As we will see later in this section, biases often remain even after post-processing.
Method 2: Modifying the Loss Function During Training
Another approach involves training debiased word embeddings from scratch by modifying the loss function of the training algorithm, such as GloVe. In this method, we attempt to concentrate gender information in the last coordinate of the word embeddings by splitting the embeddings into gendered and non-gendered components. Neutral gender words are made orthogonal to the gendered components. When using these word embeddings, we can ignore the last coordinate, effectively removing gender information. However, this method has also been shown to be insufficient in completely eradicating bias.
Limitations of Debiasing Techniques: Although these debiasing methods show some promise, they have several limitations that hinder their effectiveness.
- Bias by Neighbors: A word that is biased toward a gender may have neighboring words that are also biased toward that gender. Simply debiasing the relationship between a word and gender doesn’t eliminate the bias from its neighboring words. For example, if “nurse” is associated with females, its neighboring words like “receptionist” or “caregiver” might also be associated with females. As a result, even after debiasing the direction from the word to the gender, the bias may still persist due to the relationships between neighboring words and gender.
- Incomplete Bias Removal: Studies have shown that with both debiasing methods, some bias still remains. Most word pairs maintain their previous similarity, which indicates that the biases have not been entirely removed. To further investigate this issue, researchers have clustered the most biased words in the vocabulary before and after debiasing. The analysis of these clusters revealed that there was still a strong association with gender even after the debiasing process.
- Classifier Performance: Another way to evaluate the efficacy of debiasing techniques is to train a classifier to predict the gender of a word based on its embeddings. Using the 5,000 most biased gendered words, researchers trained a support vector machine (SVM) classifier on 1,000 random samples and predicted the gender for the remaining 4,000 words. The results showed that the prediction accuracy dropped only marginally with both debiasing methods, suggesting that the debiased embeddings still carry significant gender information.
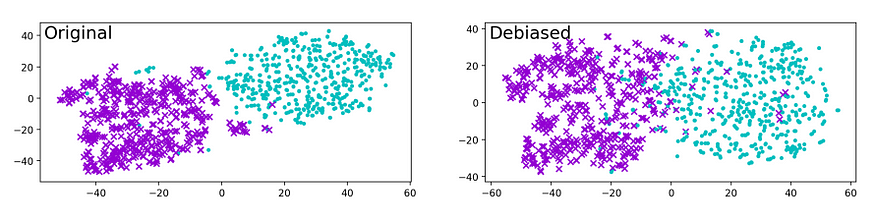
These limitations highlight the challenges faced in addressing biases in NLP systems. Despite the progress made in developing debiasing techniques, they have not yet proven to be completely effective in eliminating biases from word embeddings. It is essential for researchers and AI practitioners to continue exploring new methods and refining existing techniques to address bias in NLP better and build fairer AI systems.
Towards Fairer NLP Systems
As we have explored the presence of bias in word and sentence embeddings, it becomes clear that addressing these biases is crucial in developing fair and unbiased AI systems. To this end, we must consider various strategies to mitigate bias and promote ethical AI development.
One of the primary approaches to reducing bias is incorporating diverse training data. By including a wide range of text sources that represent different genders, races, cultures, and perspectives, we can create a more balanced foundation for AI models to learn from. This can lead to more representative word and sentence embeddings that better reflect the true diversity of human language.
In addition to diversifying training data, ethical AI frameworks can guide developers in designing and evaluating their systems. By adhering to guidelines and best practices that prioritize fairness, accountability, and transparency, AI practitioners can create more robust and unbiased models. Collaborating with ethicists and social scientists can provide valuable insights into the ethical implications of AI systems and help identify potential pitfalls in their development.
Interdisciplinary collaboration can also play a significant role in mitigating biases. By combining the expertise of linguists, computer scientists, psychologists, and sociologists, we can develop a more comprehensive understanding of the cultural and societal factors that contribute to bias in NLP systems. This collaborative approach can lead to novel debiasing techniques and more effective measurements of bias in AI models.
In conclusion, addressing bias in natural language processing systems is paramount for ensuring fairness and ethical AI applications. As we have seen, biases in word embeddings and sentence encodings can reinforce existing stereotypes and perpetuate harmful beliefs. While researchers have made progress in detecting and mitigating these biases, existing debiasing techniques are not yet perfect and may still leave some residual bias in the system.
As AI practitioners, it is our responsibility to be aware of our work's biases and seek ways to minimize their impact actively. By incorporating diverse training data, adopting ethical AI frameworks, and fostering interdisciplinary collaboration, we can move closer to creating fair and unbiased NLP systems. Ultimately, our efforts to tackle bias in AI will result in more accurate and useful technologies and contribute to a more equitable and just society.
References
[1] Caliskan, Aylin, Joanna J. Bryson, and Arvind Narayanan. Semantics derived automatically from language corpora contain human-like biases. (2017) Science 356.6334: 183–186.
[2] Bolukbasi, Tolga, et al. Man is to computer programmer as woman is to homemaker? debiasing word embeddings. (2016) Advances in neural information processing systems 29.
[3] May, Chandler, et al. On measuring social biases in sentence encoders. (2019) arXiv preprint arXiv:1903.10561.
[4] Gonen, Hila, and Yoav Goldberg. (2019) Lipstick on a pig: Debiasing methods cover up systematic gender biases in word embeddings but do not remove them. arXiv preprint arXiv:1903.03862.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

