


Unlocking the Power of Cross-Validation
Last Updated on July 17, 2023 by Editorial Team
Author(s): Roli Trivedi
Originally published on Towards AI.
A Comprehensive Guide to Optimizing Model Performance
Cross-validation is a popular technique in machine learning and statistical analysis that involves dividing a dataset into subsets to assess and validate the performance of a model. The main purpose of cross-validation is to assess how well a model generalizes to unseen data. It is mainly used to evaluate the performance of a machine learning model.
Why do we need Cross Validation?
Your machine-learning process involves the following steps :
1. Gathering your dataset
2. Preprocess + EDA + Feature Selection
3. Extract input and output columns
4. Train Test Split
5. Scaling
6. Train the model
7. Evaluate model/ model selection
8. Deploy the model
Let us understand by an example, here we are trying to do a train test split step after completing the prior steps. So we have given test_size = 0.3 which means you are dividing your data in such a manner that 70% will be training data and 30% will be your testing data. Once you have trained your model on that 70% of data, you are going to use the remaining 30% of data to check the accuracy.
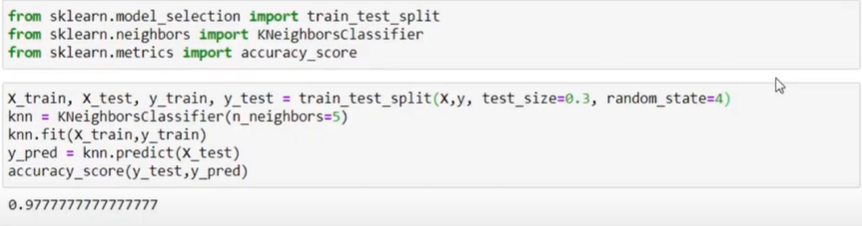
Note: When we are doing train test split then we are randomly selecting; therefore 70% of data in the training set is randomly selected. This random selection can cause a disadvantage: there can be a case where we have too much variance in test data i.e. class proportion can be like one class came nine times and one class came 1 time only. In this case, the evaluation process will not be feasible.
Now if we change the random_state parameter again, we will see our accuracy will change.

We can keep changing random_state and we will keep on getting different accuracy. So the real question resides here on which one you will put your trust in, like which split is giving us better results? You can’t tell what exact accuracy your model is giving.
Therefore the solution to this is Cross Validation, where you can do a couple of train test split and then find the mean score of it.
Types of Cross-Validation
1. Leave One Out Cross Validation(LOOCV)
Suppose you have 100 records. Now LOOCV says that in experiment 1 it will take one dataset as a test and the remaining will train. Accuracy will be tested on this single data. Then in experiment 2, the next dataset will be used for testing and the remaining will be used for training your model and you will repeat the same process for the next one.
You are always leaving one dataset out.
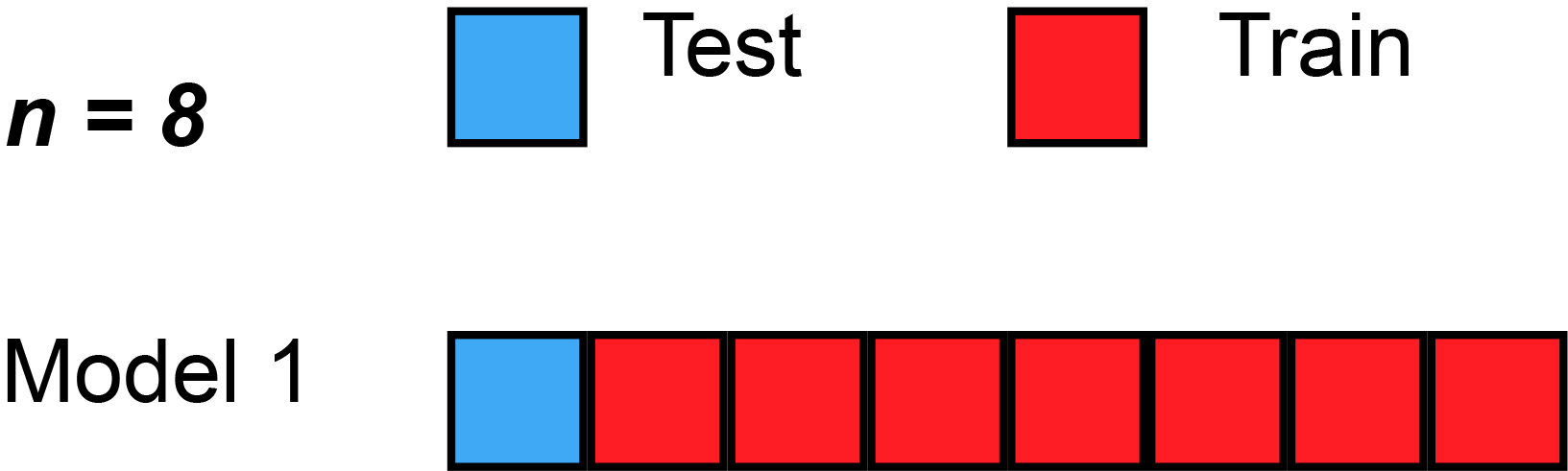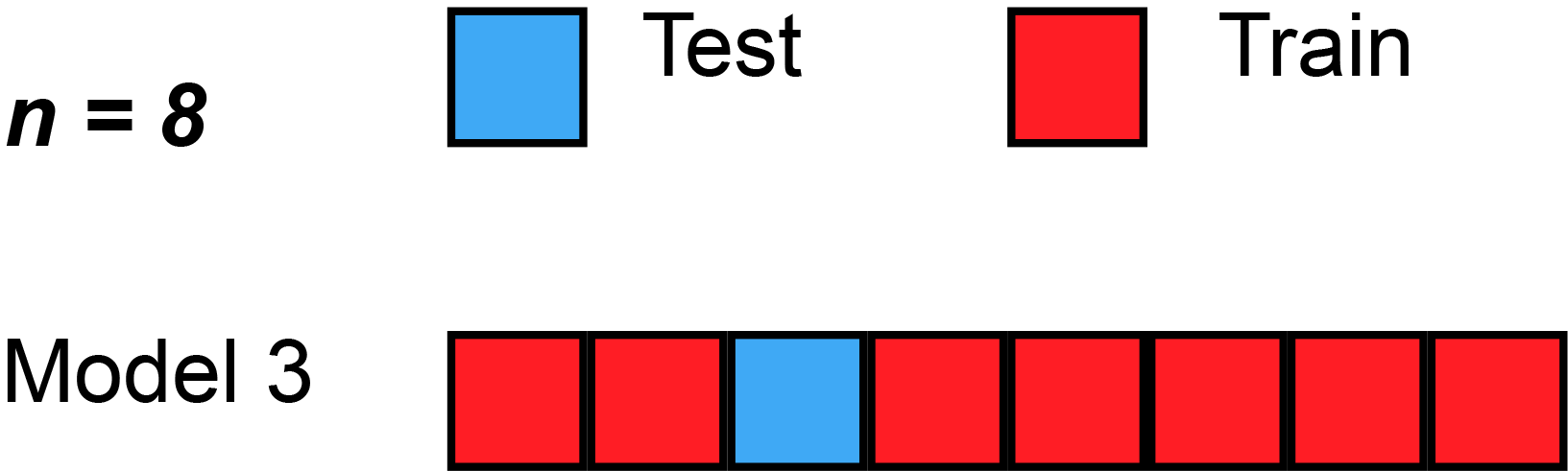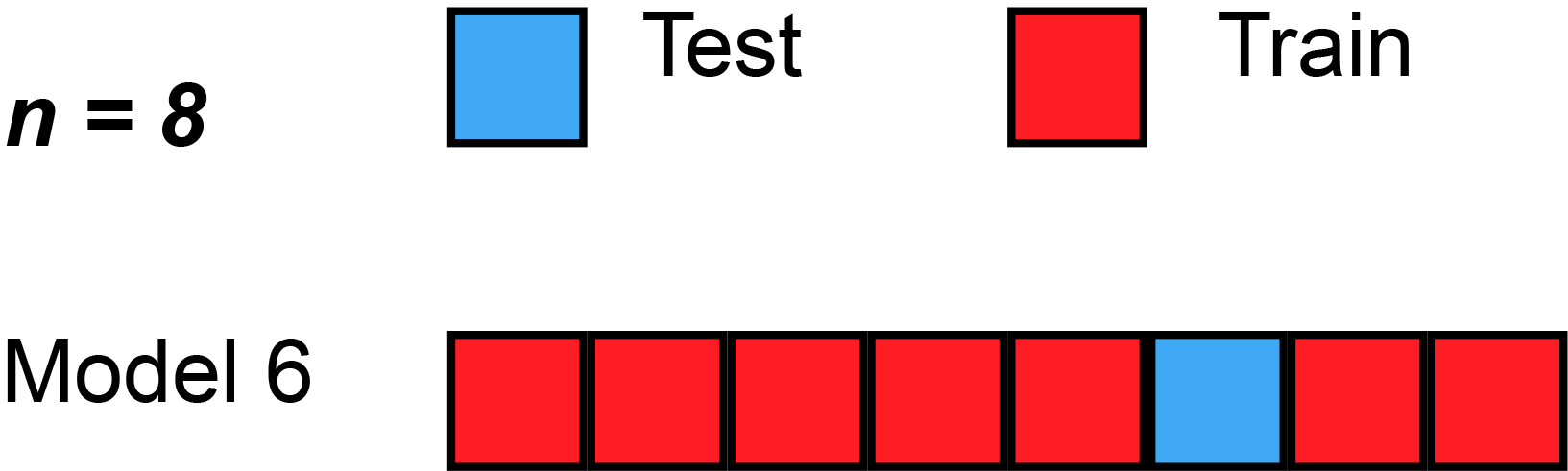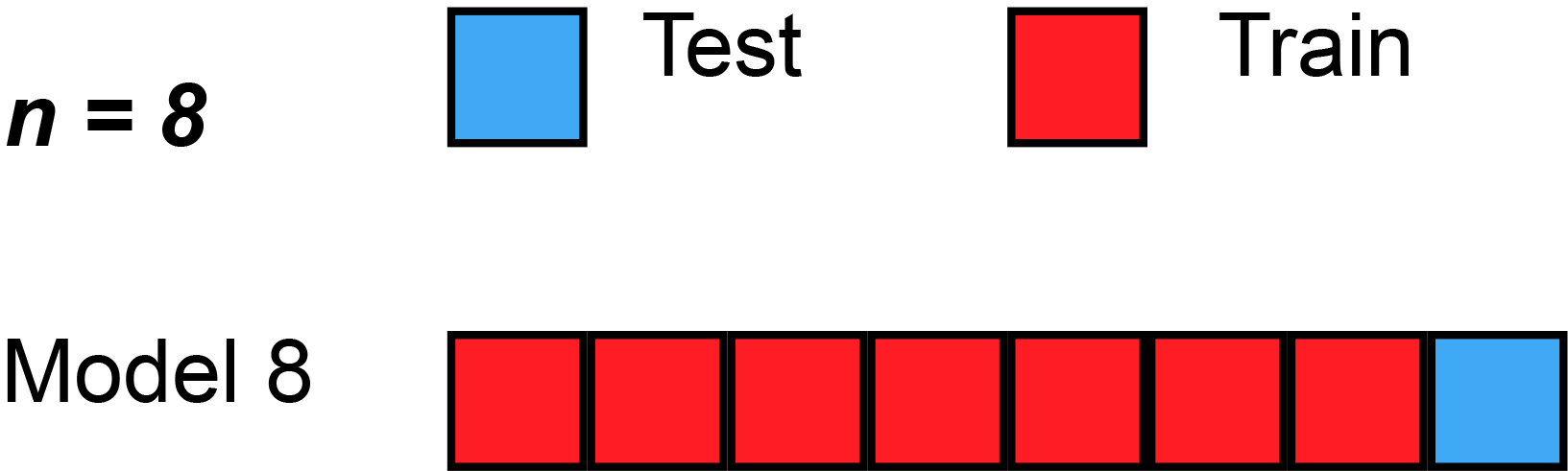
Disadvantage:
1. A lot of computation power will be used: Since we are taking one record for 100 records, therefore, you will have to perform many iterations. So you need to cover each dataset then you will have to run 100 iterations.
2. It will lead to low bias: On the training dataset it will be performing well but will not work well on the test dataset. The accuracy will go down and the error rate will go high.
Note: Nowadays nobody is using it. But still, I just wanted to put it out there.
2. K Fold Cross Validation
Here you select the K value. Suppose you have 1000 records and you select the K value as 5. This K means no of the experiments you will be performing. Since we are taking K= 5 therefore, we will perform 4 experiments.
For each experiment, based on the K value, it will decide what will be our test data.
1000/5 = 200: this means the first 200 will be your test data and the remaining 800 will be your train data in the first experiment and your accuracy will be recorded for the same. In the second experiment the next 200 records will be your test data and the remaining will be your training data and then your accuracy will be recorded for the same. This will continue until your whole 5 iterations are completed and for each iteration, you will have different accuracies.

From all these accuracies recorded, you can see the minimum accuracy and the maximum accuracy. Also, you can take out the mean of your accuracies and then it can be said that your model is giving this much mean accuracy after applying K fold CV.
Disadvantage:
You might not get the correct accuracy for your model: there can be a scenario that the 200 datasets which have been selected as test data can have only one kind of class and the same can happen with your train dataset as well as the data is getting randomly distributed which can cause an imbalance.
Therefore to solve this problem we have the Stratified Cross Validation technique.
3. Stratified Cross Validation
All the steps in Stratified Cross Validation are the same as K Fold Cross Validation. The key distinction lies in the selection of test data and training data for each experiment. This ensures that the number of instances from each class is appropriately considered in both the training and testing phases of every experiment. It makes sure that the training set consists of the same proportion of classes as it was in the dataset and so with the testing set. The proportion here is maintained.
Note: Obviously, you need to fix the imbalance issue in the feature engineering step but after that, in case you get imbalanced data after the train test split, then you will use Stratified Cross Validation to get better accuracy.
knn = KNeighborsClassifier(n_neighbors = 5)
final = cross_val_score(knn, X, y, cv = 10, scoring ='accuracy')
final.mean()
cross_val_score = function we use for Stratified Cross-Validation.
X = input data
y = target
cv = This parameter will contain your k value which you want to pass
scoring = mention any evaluation metrics here according to your model( it was my classification problem so I went with accuracy but you can mention anything according to your model)
So basically, this code will divide your dataset into 10 parts. Every part will be trained on knn model and will give your accuracy for each part. You can calculate the mean of the accuracies which you got for each part.
In similar way you can do for regression problem as well
To get a list of scoring functions which you can use above:
from sklearn.metrics import Scorers
list(Scorers.keys())
Thanks for reading! If you enjoyed this piece and would like to read more of my work, please consider following me on Medium. I look forward to sharing more with you in the future.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

