


Understanding K-Nearest Neighbors: A Simple Approach to Classification and Regression
Last Updated on June 2, 2023 by Editorial Team
Author(s): Pranay Rishith
Originally published on Towards AI.
What is KNN
Definition
K-Nearest Neighbors (KNN) is a supervised algorithm. The basic idea behind KNN is to find K nearest data points in the training space to the new data point and then classify the new data point based on the majority class among the k nearest data points.
How KNN works
KNN is a non-parametric, simple yet powerful supervised algorithm that can be used for both regression and classification tasks. This works by finding K nearest neighbors to the new, unlabeled data and making a prediction of the value or class that the new data point belongs to.
Classification:
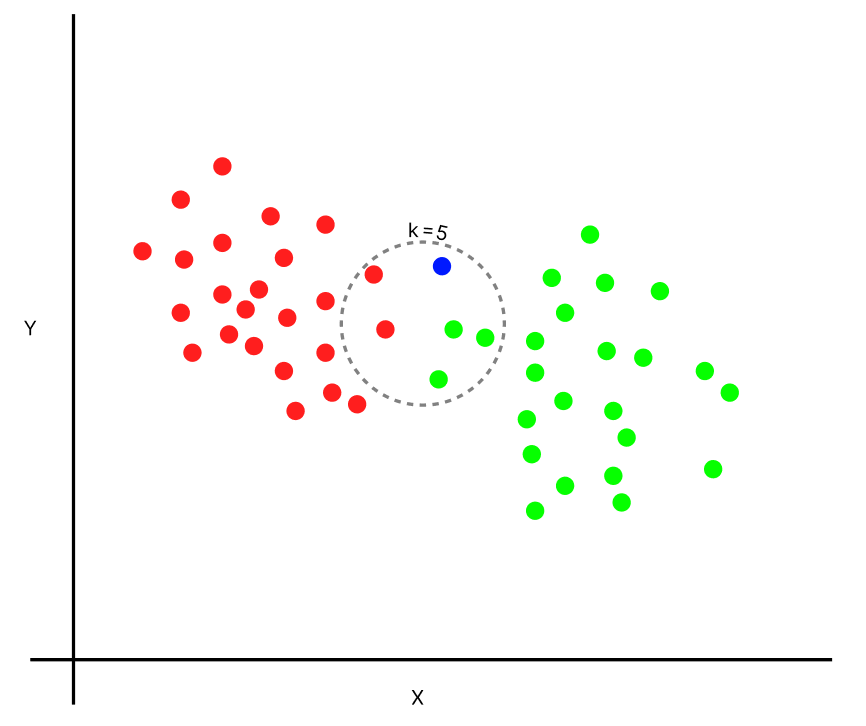
Visually observing, there are two classes, red and green. When there is a new data point (blue), and K = 5, we can see that the blue point has 3 green neighbors and 2 red neighbors; this says that the blue point is classified as the green class as the majority voting is 3. Similarly, when the K value changes, the number of neighbors increases, and the new data point is classified into its corresponding majority voting class.
Regression:
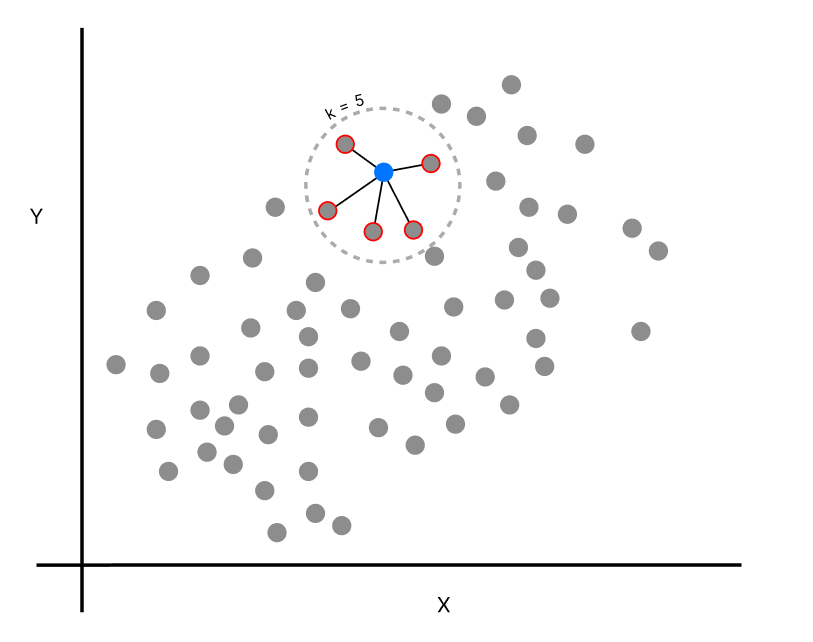
KNN regressor is quite different from the classifier. As in a regressor, the dependent variable is continuous, it is scattered throughout the coordinate plane. When there is a new data point, the number of neighbors (K) is found by any of the distance metrics. After finding the neighbors, the predicted value of the new data point is the average of all the neighbor’s values combined.
For example, consider House price prediction. There is price as the dependent variable and the square feet of the house as an independent variable. Now after mapping all the data points on the Cartesian plane, when there is a new data point in square feet feature, the K neighbor’s average price value of their square feet of the house is the price of the new data point. So instead of predicting a class, the regressor uses the average of all the neighbor values.
Understanding the KNN algorithm
Choosing the k value
The K value is the main part of KNN and choosing the right k value might be troublesome. But there are some methods to find the best and optimal k value:
- Split the dataset as training and testing.
- Choose a range of k values: select a range of k values. You can start from k = 1 and increase the value.
- Train the model: Train the KNN model for each k value.
- Evaluate the performance: Evaluate the performance of the model that has been trained using a range of k values. We can use precision, Accuracy, recall, F1 score, etc, to measure the performance.
It is important to note that the choice of the k value depends on the dataset and the problem. A smaller k value can lead to overfitting, while a larger value of k can lead to underfitting. Therefore, it is recommended to experiment with different values of k to find the optimal value for a specific dataset.
Types of Distance metrics
Euclidean
- This is the most widely used distance metric in KNN, and this is the default distance metric for SKlearn library in Python. This is the straight line distance between two data points in the Euclidean space.
- It is the square root of the sum of squares of data points.
- The formula is calculated as follows,
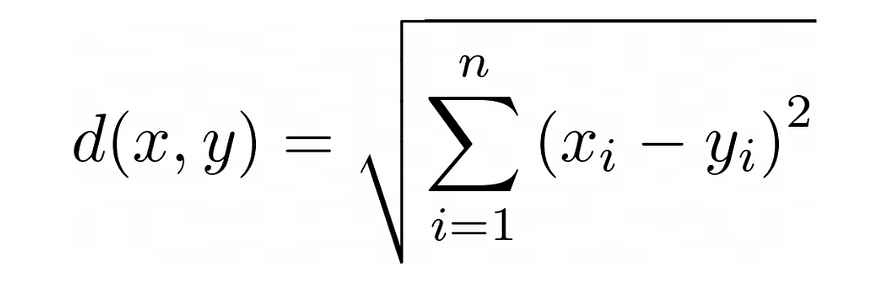
Manhattan
- Manhattan distance, also known as taxicab distance, is a measure of the distance between two points. It is named after a grid-like layout of Manhattan, where the distance between the two points is the shortest path a taxi could take. It is the sum of the absolute difference of the coordinates.
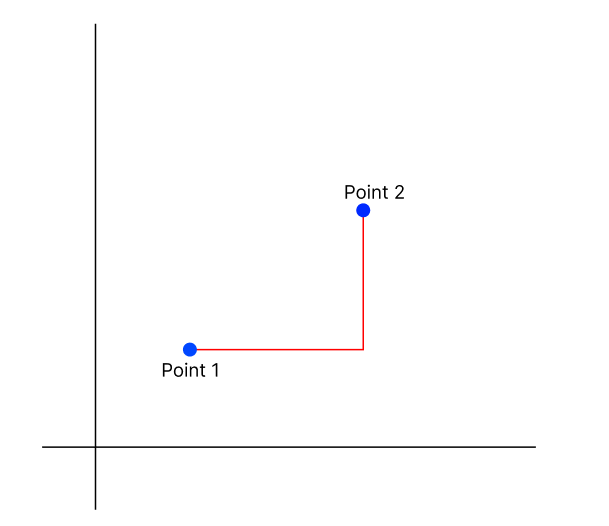
- The formula is calculated as follows,

Minkowski
- This is a metric used to measure the distance between the points in multidimensional space. This metric generalizes the Manhattan and Euclidean distance metrics. This is computed as the pth root of the sum of absolute difference raised to the power of p.
- We can manipulate the above formula to give us different distance metrics like:
— if p = 1, we get the Manhattan distance
— if p = 2, we get Euclidean distance - There are a few conditions that the distance metric must satisfy:
— Non-negativity: The distance between any two points cannot be negative.
— Identity: The distance between a point and itself is zero.
— Symmetry: The distance between two points A and B should be the same as the distance between B and A.
— Triangle Inequality: The distance between two points A and C should always be less than or equal to the sum of the distances between A and B, and between B and C. - The formula is as follows,
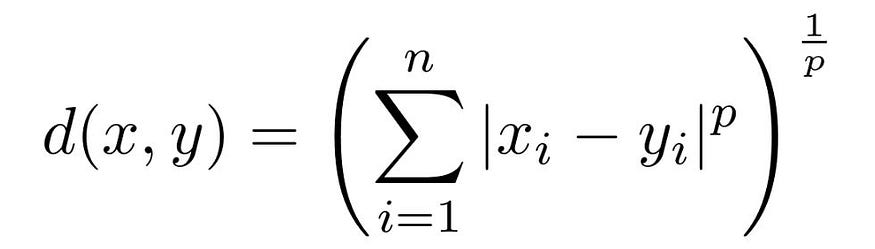
Cosine
- This distance metric is used for calculating the cosine angle between the vectors. This distance metric is commonly used for computing the similarity between vectors in various applications, including text analysis. The cosine distance metric is often preferable in combination with other distance metrics to improve the performance of the model.
- The formula is as follows,
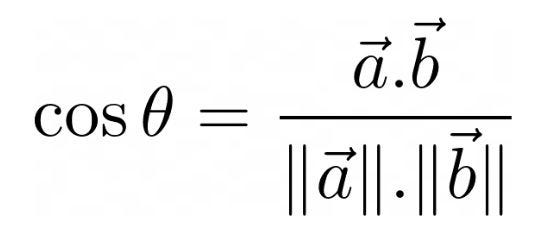
Weighted vs Un-weighted KNN
Unweighted KNN is where all the data points are assigned equal weights while making the prediction of new data point. For example, if the K=5 nearest neighbors of a new data point are three belonging to class A and two belonging to class B, the new data point is classified as class A.
Weighted KNN assigns weight to each of the data points. These weights are the inverse of the distance of the data point from the new data point. So the neighbors near the new data point have high weight and far ones have less weight. For example, if the K=5 nearest neighbors of a new data point are two belonging to class A and three belonging to class B, but the two neighbors belonging to class A are closer to the new data point than the three neighbors belonging to class B, the new data point is classified as class A with a higher weight.
Advantages and Limitations of KNN
Advantages
- Flexibility: KNN can be used for both regression tasks and classification tasks.
- No training: KNN does not require any training, which saves computational resources.
- Robust to noisy data: KNN is robust to noisy data, as it relies on majority vote of nearest neighbors. This makes it less vulnerable to outliers.
- Works well with small data: KNN works well on small datasets. It does not require a large amount of data to make predictions.
- Non-parametric: KNN is non-parametric algorithm, meaning it does not require to have any assumptions about the data.
- Simple: KNN is a simple and easy-to-understand algorithm.
Limitations
- Optimal K value: Choosing the right k value is important. it will impact the performance of the model. There is no universal k value and this value depends on the characteristics of the dataset features.
- Imbalanced data: KNN can be biased to imbalanced data, where one class might have more examples than the other. KNN may predict the majority class for the test examples.
- Curse of dimensionality: KNN can suffer from the curse of dimensionality, which occurs when the number of features are large. As the number of dimensions increases, the distance between any two points in the data tends to become larger, making it difficult to find meaningful nearest neighbors.
Applications of KNN
- Classification: KNN can be used for classification like spam detection, image recognition, sentiment analysis, etc. Here KNN will classify the new data point based on the training dataset and assigns a class to it.
- Regression: KNN can be used for regression like house price prediction etc. Here KNN will predict the new data point using the k nearest neighbor average value.
- Text Classification: KNN can be used to classify text documents based on their content. For example, KNN is used to classify a text document based on its category, like sports, crime, etc.
- Recommendation Systems: KNN can be used in recommendation systems to recommend products based on the user’s similarity to other users. For example, Netflix uses recommendation system to recommend movies that are enjoyed by users that have similar interests. (This is just to explain).
Conclusion
So to conclude, KNN is a simple and easy-to-learn algorithm that can be used for both regression and classification. It works by using a hyperparameter k value which finds the nearest neighbors to the new data point.
References:
- Internet
Well, that’s the end of KNN. More advanced concepts for another article. Let us meet at the next one. If you enjoy this content, giving it some clapsU+1F44F will give me a little extra motivation.
You can reach me at:
LinkedIn: https://www.linkedin.com/in/pranay16/
GitHub: https://github.com/pranayrishith16
Kaggle: https://www.kaggle.com/pranayrishith16
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

