



Understand your Customer Better with Sentiment Analysis
Last Updated on April 8, 2022 by Editorial Team
Author(s): Simoni Tyagi
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
“Your most unhappy customers are your greatest source of learning.” — Bill Gates
In this cut-throat business world, companies look for strategies to keep their customer base satisfied and possibly attract new customers by launching offers or new products. It has become inevitable to keep a track of whether customers are liking or disliking a product and how they are reacting to a certain offering to improve the service to stay ahead of the competitors. In this blog, the focus will be on the NLP use case ‘Sentiment Analysis’ that categorizes customer reviews according to customers’ sentiments for a product that benefits the businesses by keeping the track of customers’ reviews on a product.
We’ll follow step by step process of performing sentiment analysis on a dataset having reviews of smartphones and data labels as ‘Positive’ and ‘Negative’ sentiment for these reviews. You can download the data from Kaggle and follow along. We’ll cover some basic and beginner-level concepts of the Word2Vec algorithm and its architecture to better understand the working of NLP in processing text data.
Dataset Used
To perform sentiment analysis, the process followed is:

1. Text Pre-processing
Data pre-processing is required to remove unnecessary information from the text that may result in a less accurate model. The steps followed for text pre-processing are:
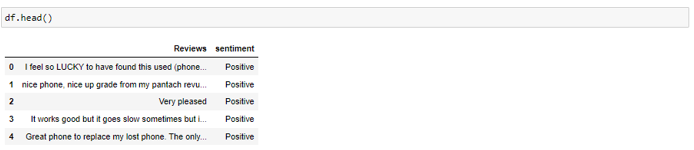
· Lower casing — It is one of the most common text pre-processing steps and is used based on the problem statement. If you are dealing with text that is being used to recognize the emotions of people then this step can be skipped as doing it will result in loss of information like using upper case words to show anger or excitement.
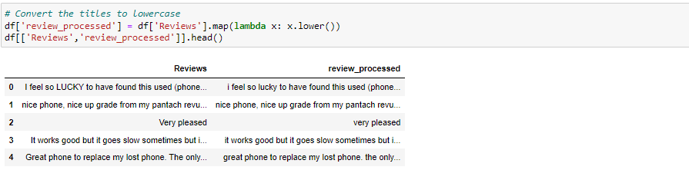
· Tokenization — Tokenization is breaking down the text into smaller chunks (sentences or words) called tokens. This process is required as tokens interpret the context of a sentence based on the sequence of words that is pivotal for the word2vec model.
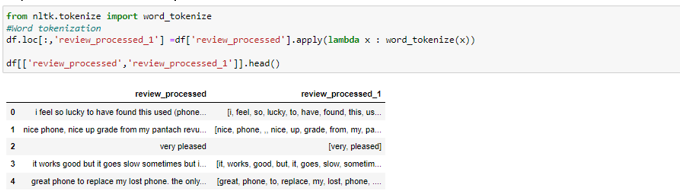
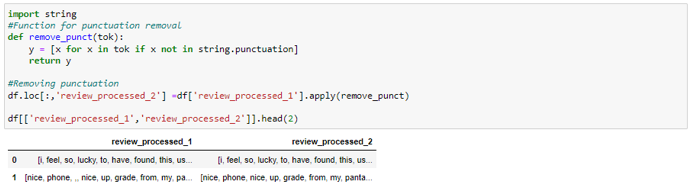
· Special Characters Removal — Special characters like brackets, commas, etc., do not add any value to the text and they can be removed using Python’s string library which contains a pre-defined list of punctuations that can be used to remove punctuations.
· Lemmatization — Lemmatization remove the prefixes and suffixes and transform the word to its basic form for eg.- ‘changes’ and ‘changing’ will be converted to ‘change’.
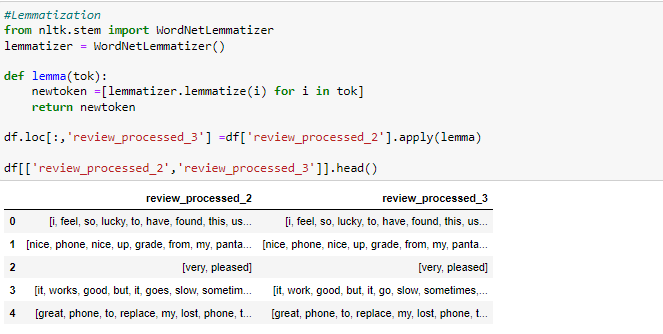
· Stop words removal — Stop words are the most common words used in textual data and do not carry any valuable information about the topic of focus in the text. Words like my, myself, we, our are stop words, and the NLTK library contains a pre-defined list of stop words that you can use and you can also create a user-defined list of stop words according to project requirements. For example, in our dataset ‘What’ might be a stop word but if we are dealing with a customer queries dataset then ‘What’ will be an important word.
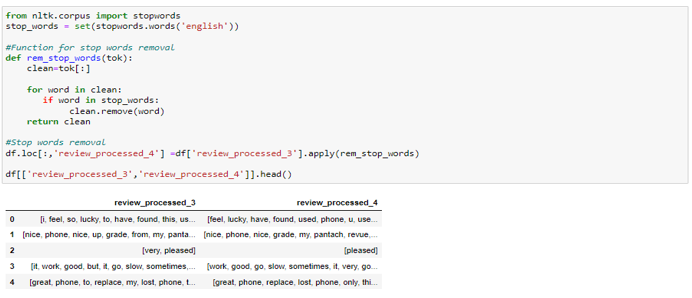
2. Word Embeddings
ML models do not comprehend the raw text directly. So, text data is required to be converted into vectors that encode the contextual meaning of words and hold similar words closer to each other in dimensional space. For Example, words like phone, mobile, and cellphone will appear closer to each other in dimensional space and far away from non-related words like ‘nice’, ’good’ etc. This process of converting text into vectors is called word embedding and the Word2Vec algorithm is used to produce these embeddings.
Working of Word2Vec
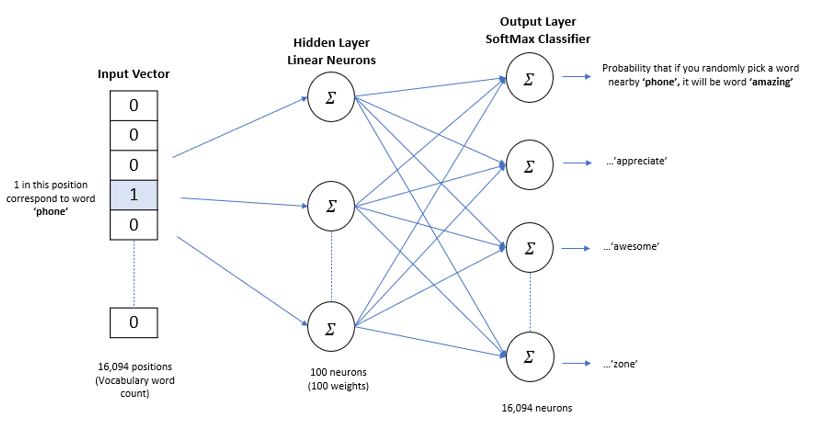
Word2Vec leverages a neural network with a single hidden layer to predict the probability of each word in text corpus being closer to the input word in dimensional space. Now, the intuition here is that similar words are used in a similar context, and they appear closer to each other in dimensional space so the probability for similar words should be more but the goal of training a neural network in the Word2Vec algorithm is not to use the resulting neural network itself but learn weights of the hidden layer. These weights are our word vectors which give us the address of words in a dimensional space.
Below is the visual diagram and architecture of the skip-gram neural network which takes one word as input and tries to predict the context words.
Genism is an open-source python library for NLP which provides Word2Vec model algorithms for learning word associations from a large corpus of text. Below is the code for training the word2vec model on text data.
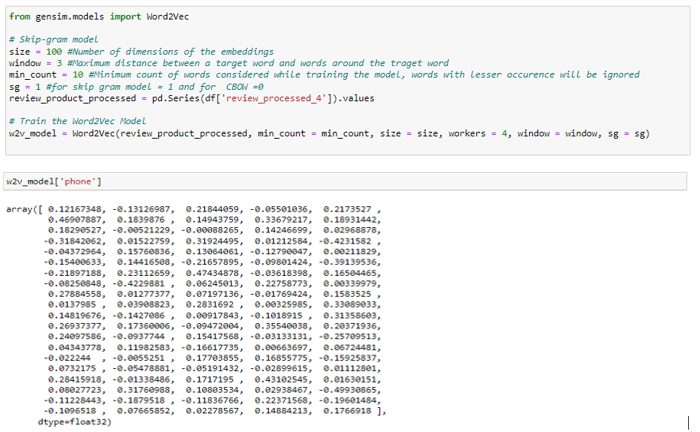
Now, that we have vectors for each word in our corpus we will take the average of all the words’ vectors in a sentence and that will result in an average array of 100 dimensions for that review statement.
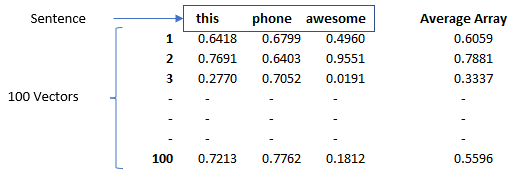
This 100-dimension average array will represent our statement’s features for the classification model to predict the sentiments. It is stored in ‘word2vec_df’ which is leveraged for the classification model to classify the sentiments.
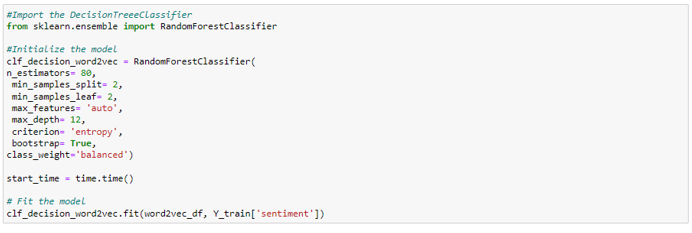
3. Classification
Once we have the features of reviews, we can train a classification model on the data to predict the sentiments. The model’s accuracy is improved by hyperparameter optimization using Random Search CV.
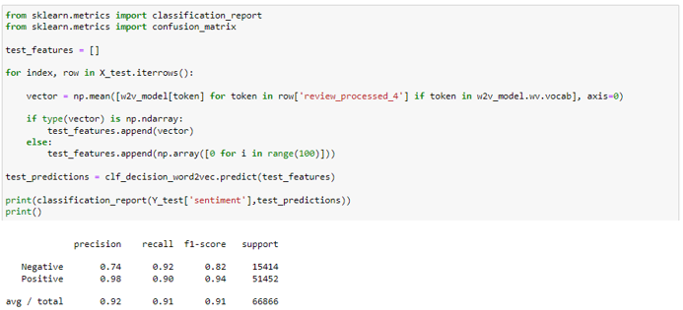
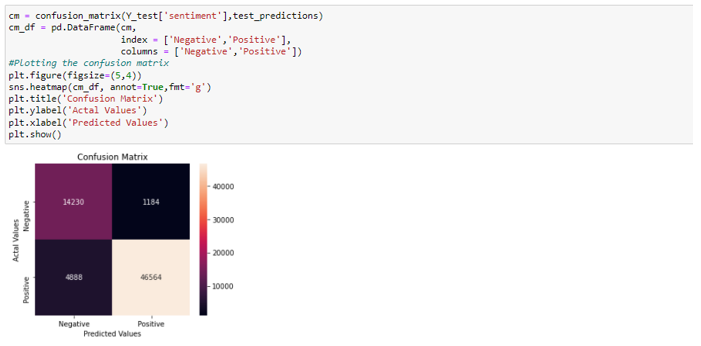
Evaluation of Trained Model on Test Set
A classification report and confusion matrix was generated to see the performance of the model. Gensim word2vec embedding method and Random Forest classification model were able to generate a high accuracy for 2 class text classification problem. The reason for choosing Random Forest for this problem statement was that it performs better than other classification algorithms (Support Vector Machines, Logistic Regression) when we compare all the evaluation metrics like Precision, Recall, and F1.
Business Use
Let’s say your company has recently launched a product and they want to understand the product reception in the market. This model will help you predict the sentiments by leveraging the product reviews and seeing how many people have given positive reviews and how many have disliked the product.
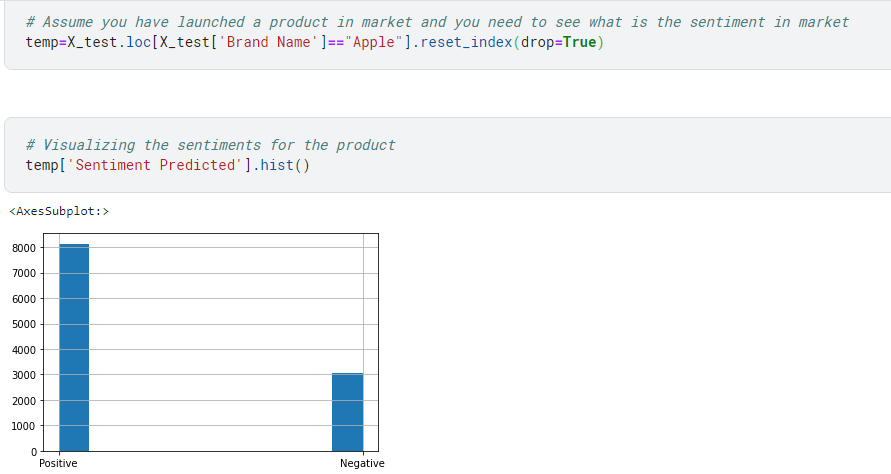
3000 reviews are negative and you might want to check exactly what is it that customers are not liking about the product. You can do that by making a word cloud of negative reviews


As you can see, people are not happy with the product’s battery, screen, and seller they bought the product from. This information can be useful in improving the product and overall customer experience.
Conclusion
This blog focuses on the sentiment analysis use case of NLP for beginners and once you have a hold on the understanding of the word2vec algorithm, it is best to move towards more advanced techniques of text classification, like building neural networks as the drawback of the above method is it might not perform very well for multiclass text classification, so, deep learning neural networks can be explored for these kinds of problems.
Code Link
Code can be referred from here
References
https://machinelearningmastery.com/develop-word-embeddings-python-gensim/
2. Reference for working of skip-gram — https://towardsdatascience.com/word2vec-skip-gram-model-part-1-intuition-78614e4d6e0b
Understand your Customer Better with Sentiment Analysis was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts
")



")


