



Twitter Sentiment Analysis: FIFA World Cup 2022
Last Updated on December 12, 2022 by Editorial Team
Author(s): Tirendaz Academy
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
A Practical Guide to Sentiment Analysis with Snscrape and Hugging Face
Football is one of the most loved sports worldwide. The FIFA World Cup, a global football sporting event that takes place every four years, is in Qatar this year. The decision to hold the World Cup in Qatar has sparked several controversies, including allegations of corruption and human rights violations.
So, what do football lovers think about the FIFA World Cup 2022? To find out that, I’ll perform a Twitter sentiment analysis using the hashtag #WorldCup2022 on Twitter in this blog post. Here’s what I’m going to talk about:
- What is Sentiment Analysis?
- What is Social Media Scraping?
- How to scrape with Snscrape?
- How to perform Twitter sentiment analysis?
Let’s dive in!
What is Sentiment Analysis?
Sentiment analysis is a type of NLP that aims to label data according to its sentiments, such as positive, negative, and neutral. This analysis helps companies understand how their customers feel about their products or services or identify trends in public opinion about a particular topic. For example, a company like Audi can learn whether people like the colors of its new car by examining Twitter shares like the image below.

What is Social Media Scraping?
With the developing technology, it is now much easier to express all kinds of emotions, feelings, and thoughts through social networking sites. Social media scraping is the process of extracting data from social media platforms. One of the most used social media platforms is Twitter. When we look at the statistics, Twitter has around 450 million monthly active users as of 2022 and 6,000 tweets are posted every second.
Twitter is one of the most important data sources for data scientists. Data scientists can extract data from Twitter with web scraping tools. There are several libraries to do this, such as Tweepy and Snscrape. Let’s take a look at the pros and cons of these libraries.
Tweepy
Tweepy is an easy-to-use Python library that allows you to access the Twitter API. You can connect the Twitter API with this library and scrape the tweets you want. However, this library has some drawbacks. The standard version of the Twitter API only allows you to extract 3200 tweets in a timeline. There are limits to how many tweets you can collect from a user’s account. You can find more information about these limits here.
Snscrape
Another library you can use to collect data from Twitter is Snscrape. Snscrape is a data scraper for social networking services that helps you extract data such as user profiles, tweet contents, hashtags, or searches. It also does not require the use of a Twitter API. With Snscrape, you can also scrape data from other services like Facebook, Instagram, Reddit, and Telegram.
Disclaimer: This article is only for educational purposes. We do not encourage anyone to scrape websites, especially those web properties that may have terms and conditions against such actions.
How to scrape with Snscrape?
In this section, we’ll look at a brief overview of Snscrape to orient ourselves on its structure/philosophy before diving into Twitter sentiment analysis. First, we’re going to install this library with the following command:
!pip install snscrape
Next, let’s retrieve 1000 tweets sent on the first day of the tournament from #WorldCup2022 and then convert this data into Pandas DataFrame. Note that you can use this notebook to follow this analysis.
# Importing necessary libraries
import snscrape.modules.twitter as sntwitter
import pandas as pd
# Creating a list to append all tweet attributes(data)
tweets = []
# Creating query
query = '#WorldCup2022 lang:en since:2022-11-20 until:2022-11-21'
q = sntwitter.TwitterSearchScraper(query)
# Using TwitterSearchScraper to scrape data and append tweets to list
for i, tweet in enumerate(q.get_items()):
if i>1000:
break
tweets.append([tweet.user.username, tweet.date, tweet.likeCount, tweet.sourceLabel, tweet.content])
# Converting data to dataframe
tweets_df = pd.DataFrame(tweets, columns=["User", "Date Created", "Number of Likes", "Source of Tweet", "Tweet"])
tweets_df.head()

Voilà! We easily scraped tweets from Twitter with Snscrape using just a few parameters. Snscrape tweet objects have many parameters. You can see these parameters in the image below.

It’s time to perform a Twitter sentiment analysis to find out what football lovers think of FIFA World Cup 2022.
Twitter Sentiment Analysis with Hugging Face

So far, we’ve covered what sentiment analysis and social media scraping are and then how to collect tweets from Twitter. In this section, In this, we’ll walk you through how to perform a Twitter sentiment analysis. Before I show you this analysis, let me explain a few NLP concepts you need to know.
Transfer Learning
To carry out the sentiment analysis, you can build a model from scratch. When analyzing big data, this approach takes a lot of time and money. When working with big data, I recommend using the transfer learning technique. Transfer learning is a machine learning approach where a model trained on one task is reused on another related task.
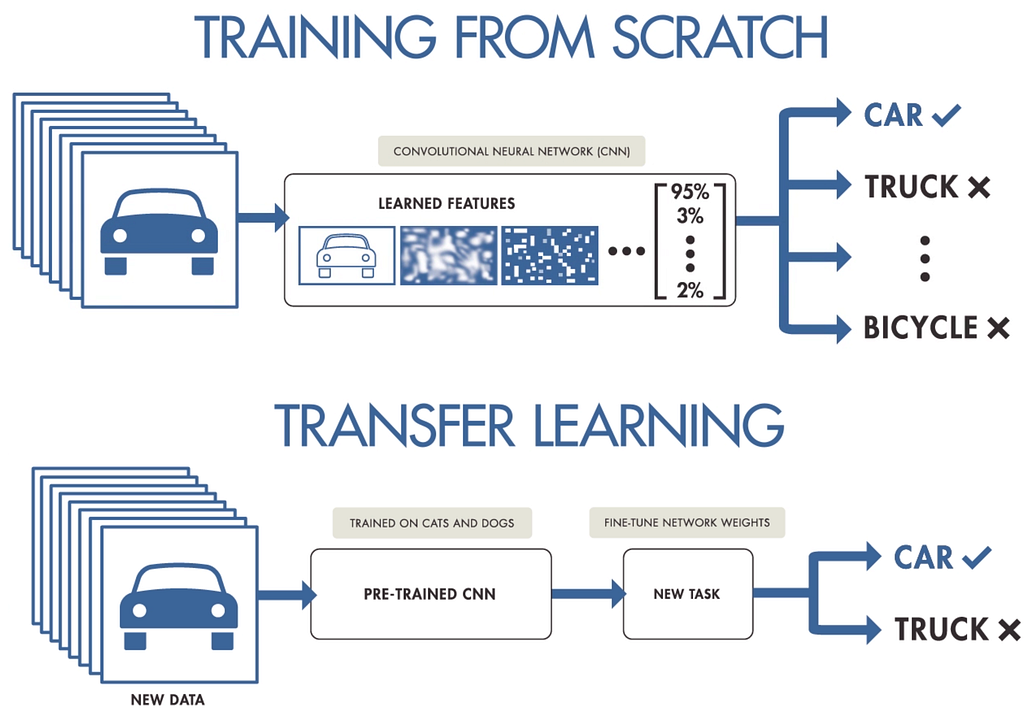
Although transfer learning has become the standard approach in computer vision, this method was not suitable for NLP for many years as it required large amounts of labeled data. After 2017, with the development of models such as BERT and GPT3 based on transformers, the transfer learning technique has also been used for NLP. However, some problems have arisen in the use of these models, for example:
- Using different frameworks, such as PyTorch or TensorFlow, when coding the model architecture.
- Loading the pretrained models from a server.
- Fine-tuning the pretrained models.
To tackle these problems painlessly, the Hugging Face framework was developed.
What is Hugging Face?
Hugging Face is a data science platform and large open-source community that provides tools that help users build, train, and deploy machine learning models. It offers a standardized interface to a wide range of transformer models for adapting them to new usage tasks. You can also use this framework to work with three major deep-learning libraries (PyTorch, TensorFlow, and JAX).
What is Hugging Face Hub?
Hugging Face Hub is an open-source platform where people can easily collaborate and create machine-learning models. For example, you can find over 762 publicly available sentiment analysis models in this hub.
The model we’ll use for this analysis is the cardiffnl/twitter-roberta-base-sentiment-latest model, which is a roBERTa-base. This model was trained on ~124 million tweets from January 2018 to December 2021. The easiest way to load this model is to use a pipeline. Pipelines automatically load the model you want and its preprocessing class. Let’s load our model with the pipeline method:
# Installing transformers library
# !pip install transformers
from transformers import pipeline
sentiment_analysis = pipeline(model="cardiffnlp/twitter-roberta-base-sentiment-latest")
Awesome! Our model is ready to make predicts. If you want, you can also use different models for this analysis.
Running Twitter Sentiment Analysis
Let’s put together what we’ve talked about so far and run a Twitter sentiment analysis. To do this, let’s first scrape tweets from the first day of the tournament in the hashtag #WorldCup2022 and then find the sentiment in each tweet with the for a loop.
# Creating a list to append all tweet attributes(data)
tweet_sa = []
# Creating query
query = '#WorldCup2022 lang:en since:2022-11-20 until:2022-11-21'
q = sntwitter.TwitterSearchScraper(query)
# Preprocess text (username and link placeholders)
def preprocess(text):
new_text = []
for t in text.split(" "):
t = '@user' if t.startswith('@') and len(t) > 1 else t
t = 'http' if t.startswith('http') else t
new_text.append(t)
return " ".join(new_text)
# Predicting the sentiments of tweets
for i, tweet in enumerate(q.get_items()):
if i>30000:
break
content = tweet.content
content = preprocess(content)
sentiment = sentiment_analysis(content)
tweet_sa.append({"Date Created": tweet.date, "Number of Likes": tweet.likeCount,
"Source of Tweet": tweet.sourceLabel, "Tweet": tweet.content, 'Sentiment': sentiment[0]['label']})
We now have the sentiments of the tweets. To find out what football lovers think of FIFA World Cup 2022, let’s first convert the results into a DataFrame and then take a look at the first five rows of this DataFrame.
import pandas as pd
pd.set_option('max_colwidth', None)
# Converting data to dataframe
df = pd.DataFrame(tweet_sa)
df.head()
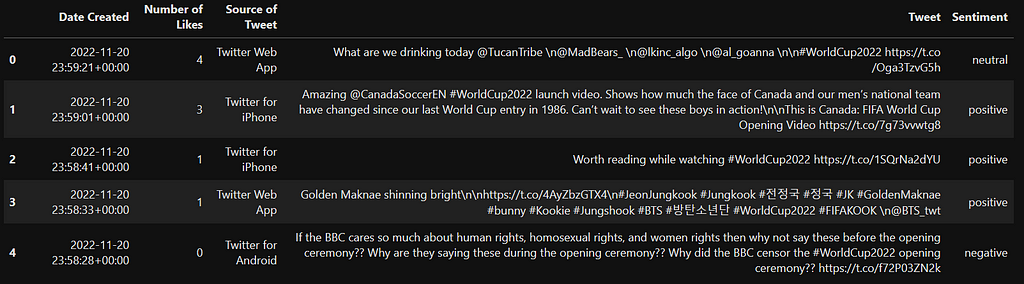
As you can see, we have a Twitter dataset with some information like date, likes, source of tweets, tweets, and sentiments. You can find this dataset here. Let’s go ahead and visualize all these labels with a pie chart.
Data Visualization
After predicting the labels, it’s a good idea to see the distribution of these labels. First, let’s group the data according to the sentiment column and take a look at the sentiments:
import matplotlib.pyplot as plt
# Let's count the number of tweets by sentiments
sentiment_counts = df.groupby(['Sentiment']).size()
print(sentiment_counts)
# Output:
Sentiment
negative 5784
neutral 8251
positive 8489
dtype: int64
Next, let’s draw a pie plot according to these groups.
# Drawing a pie plot
fig = plt.figure(figsize=(6,6), dpi=100)
ax = plt.subplot(111)
sentiment_counts.plot.pie(ax=ax, autopct='%1.1f%%', startangle=270, fontsize=12, label="")
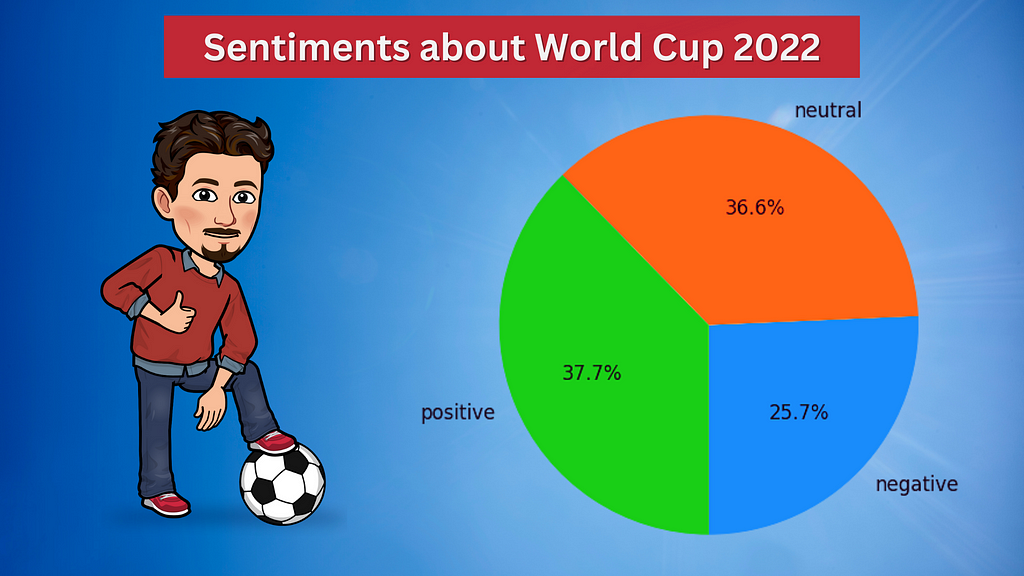
As you can see, the percentage of positive and neutral tweets is close to each other. The percentage of negative tweets is the lowest. It turned out that football fans think more positively about the 2022 FIFA World Cup.
Generating Word Cloud
Now let’s create a word cloud and see which words stand out for each sentiment with the worldcloud library. First, let’s look at the word cloud of positive tweets.
from wordcloud import WordCloud
from wordcloud import STOPWORDS
# Wordcloud with positive tweets
positive_tweets = df['Tweet'][df["Sentiment"] == 'positive']
stop_words = ["https", "co", "RT", "WorldCup2022"] + list(STOPWORDS)
positive_wordcloud = WordCloud(width=800, height=400, background_color="black", stopwords = stop_words).generate(str(positive_tweets))
plt.figure(figsize=[20,10])
plt.title("Positive Tweets - Wordcloud")
plt.imshow(positive_wordcloud, interpolation="bilinear")
plt.axis("off")
plt.show()

Some of the words associated with positive tweets contain FIFA, Canada, Black, Brazil, start, etc. Next, let’s take a look at the word cloud of negative tweets.
# Wordcloud with negative tweets
negative_tweets = df['tweet'][df["sentiment"] == 'negative']
stop_words = ["https", "co", "RT", "WorldCup2022"] + list(STOPWORDS)
negative_wordcloud = WordCloud(width=800, height=400, background_color="black", stopwords = stop_words).generate(str(negative_tweets))
plt.figure(figsize=[20,10])
plt.title("Negative Tweets - Wordcloud")
plt.imshow(negative_wordcloud, interpolation="bilinear")
plt.axis("off")
plt.show()

Some of the words associated with negative tweets: are rights, Qatar, BBC, opening, human, ceremony, etc.
Final Thoughts
Social media are platforms where people freely share their thoughts. Twitter is one of the most used social media platforms. The data on this platform is gold for companies. Companies can make more accurate decisions using this data.
In this blog post, I first showed you how to scrape data from Twitter with Snscrape. Next, I explained how to perform sentiment analysis with a pre-trained model in Hugging Face. We explored the thoughts of football fans about the FIFA World Cup 2022. The model we built predicted more positive labels. It turned out that football fans think more positively about the 2022 FIFA World Cup.
That’s it. Thanks for reading. I hope you enjoy it. You can find the notebook I used on this blog here. Don’t forget to follow us on YouTube | Twitter | Instagram | TikTok 👍
Resources
- Getting Started with Sentiment Analysis using Python
- Twitter Sentiment Analysis
- Web Scraping with Python
- Natural Language Processing with Transformers
Twitter Sentiment Analysis: FIFA World Cup 2022 was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

