



Trends in AI — May 2022
Last Updated on July 26, 2023 by Editorial Team
Author(s): Sergi Castella i Sapé
Originally published on Towards AI.
A monthly selection of news and research papers: open-source DALLE·2, Meta openly shares a 175B GPT-3 clone, Video Diffusion Models, Autoregressive Search Engines, Adversarial backdoor attacks, and more.
As we leave behind the ICLR conference and approach the equator of 2022, it’s hard to imagine how the world of AI could be more active. Once again, we’ve had a tough time selecting only the top stories and research out of a vast sea of interesting content. Let’s start with some news:
- A recent paper by Google featuring several high-profile researchers and engineers at the company paints a hopeful picture of the future of Machine Learning’s carbon footprint. The project that emissions related to running ML models will plateau to eventually decrease thanks to the increasing efficiency of training and inference by orders of magnitude. The paper also encourages all researchers to publish carbon footprint data in all their publications to gain a more accurate understanding of the matter.
- LAION-5B: A new era of open large-scale multi-modal datasets is the largest scale dataset of image-text pairs with almost 6 billion samples. Maybe you should check your available storage before clicking on the download button, the dataset size is up to 240TB.
- lucidrains/DALLE2-pytorch: while DALL·E 2 code is not available, lucidrains has god you covered with an open-source implementation of the model you can play around with.
U+1F52C Research
Every month we analyze the most recent research literature and select a varied set of 10 papers you should know of. This time around covering topics such as Adversarial Attacks, Bias, Diffusion Models, Information Retrieval and much more.
1. Video Diffusion Models U+007C Project page
By Jonathan Ho, Tim Salimans, Alexey Gritsenko, William Chan, Mohammad Norouzi, and David J. Fleet.
U+2753 Why → If you’re following this blog series (as you should) you’ll have heard of diffusion models. These models have been kicking ass for the past year; surpassing GANs as the coolest kid in image generation town, and recently being a key ingredient in the sauce that’s made DALL·E 2 undeniably impressive. Well, now diffusion models upgrade from images to videos. Could this be the direction DALL·E 3 will set laser eyes on?
U+1F4A1 Key insights → Diffusion is a generative modeling paradigm that allows you to generate data (image, sound, text) from a noise sample by iteratively reversing a diffusion process (i.e. adding differentiable noise at each step, this video contains a thorough explanation). This work is the first one to apply Diffusion Models successfully to generate videos.
The architecture of the neural network is a standard U-NET¹ — a common architecture for modeling vision that combines convolutional and attention layers adapted to include the frames or temporal dimension. This is trained on short videos of only 16 frames and small resolution (64×64) and they use classifier-free guidance to achieve text-conditional generation. The process is very much analogous to that of diffusion models on images; but to extend the method to longer videos, the novel gradient conditioning method, which lets them interpolate or extrapolate new frames of the video as a conditional diffusion process.
The resulting videos are not quite photorealistic, yet are still a substantial step forward: check them out yourself!

Another relevant work in image generation is VQGAN-CLIP: Open Domain Image Generation and Editing with Natural Language Guidance, which would’ve been a top highlight if it weren’t for DALLE·2⁷ stealing its thunder.
2. Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language U+007C Project Website
By Andy Zeng, Adrian Wong, Stefan Welker, Krzysztof Choromanski, Federico Tombari, Aveek Purohit, Michael Ryoo, Vikas Sindhwani, Johnny Lee, Vincent Vanhoucke, and Pete Florence.
U+2753 Why → Unimodality is sometimes quoted as a weakness of generative Language Models (LMs from now on), there’s only so much you can know about the world by looking at just text. But maybe it doesn’t need to be trained on images to answer about images, maybe it can just interact with another model that has seen images.
U+1F4A1 Key insights → This paper is about having foundation models² trained on different modalities (video, image, audio, text…) interact via a structured dialog to enhance the zero and few-shot multimodal capabilities of these. The motivation behind this idea is that models that learn from different data modalities will learn different and complementary information about the world which can be leveraged in a zero-shot setting, without the need of finetuning all the models together.
The interaction happens in a dialog, hence the name of the framework “Socratic Models”, and broadly speaking it goes a bit like follows. Imagine you want to answer complex questions about a video, a Visual Language Model (VLM) can generate captions for each frame of a video containing information like place and objects in the video. Then an LM can be prompted to generate a first-person (egocentric) summary of the scene and answer complex questions about it. This basic interaction through text can be extended to other modalities such as audio and images.
A lot of the results in this paper are hard to compare apples to apples with existing methods because there aren’t really any benchmarks yet designed to measure the capabilities of such a system. So this is more of a “hey this thing is possible” paper, not so much “this beats existing methods by a parge margin” paper. Still, this presents a potentially impactful direction of research, especially given the current trend of APIzation of Machine Learning.

Deepmind also recently released U+1F9A9 Flamingo: a Visual Language Model for Few-Shot Learning (along with an explainer blog post), which presents their zero and few-shot performance and would be a natural match for Socratic Models.
3. Planting Undetectable Backdoors in Machine Learning Models
By Shafi Goldwasser, Michael P. Kim, Vinod Vaikuntanathan, and Or Zamir.
U+2753 Why → Learning ML algorithms from scratch can be hard, which is why outsourcing to a third party the implementation and training of a model is growing in popularity. What could go wrong?
U+1F4A1 Key insights → This paper is quite theoretical in nature but the gist of it is quite simple. The authors prove that a third party can train and provide a classification model that performs undetectably well for regular data, but that has a computationally undetectable backdoor through which an adversary can add an undetectable perturbation to any input (a digital signature) to change the output to any desired misclassification.
Imagine someone sells your bank a credit scoring model that outputs a binary prediction as to whether a loan should be granted or not. The bank hosts and runs the model, they can see everything it does. Still, they cannot detect it has a backdoor that lets any adversary applicant introduce a digital signature, which will ensure the output is positive.
Looking at more mundane examples, even public pre-trained models which are extremely popular these days could contain undetectable backdoors enabling adversaries to manipulate inference! One can imagine that this also casts some doubt on out-of-the-box ad-hoc explainability methods, which could contain such backdoors as well making them untrustworthy or unreliable.
The paper lays out the formal settings of the problem and investigates various levels of security, it’s quite fascinating. It’s still unclear to which degree all this is feasible; however, these kinds of fundamental security concerns for ML models need to be seriously taken into account as models grow in complexity and their intrinsic interpretability is.
4. The Distributed Information Bottleneck reveals the explanatory structure of complex systems U+007C Code
By Kieran A. Murphy and Dani S. Bassett.
U+2753 Why → The Information Bottleneck principle³ championed by Naftali Tishby is a powerful lens through which one can understand learning in Neural Networks (NNs). What can this perspective elucidate about complex data?
U+1F4A1 Key insights → Representation learning can be understood from the lens of Information Theory. Broadly speaking, representations are subject to an inescapable tradeoff between accuracy and complexity; and learning objectives can be defined in terms of mutual information involving input, output, and latent representations. Tishby formalized this principle in the late 1990s and later applied it to improve our understanding of Deep NNs which is still a topic of debate today.
At the core of this method is the idea that constraints are required to learn anything meaningful about data because to learn one needs to forget. Now when it comes to this paper, proposes to decompose complex interactions into various bottlenecks to more easily model complex interactions. It’s interesting because this paper largely stems from a physics background so it’s motivated by having models learn intelligible interactions an input presents.
In practice, this means a bunch of VAEs⁴ running in parallel for different partitions of an input. The authors showcase how this method works in reverse engineering logical gates, decomposing images, and modeling condensed matter in physics.
This is another case of a constraints-are-a-powerful-inductive-bias work, and as such it’s not really expected to beat existing models in most in-domain benchmarks, yet it’s still a fascinating direction for robust and interpretable learning.

5. Autoregressive Search Engines: Generating Substrings as Document Identifiers
By Michele Bevilacqua, Giuseppe Ottaviano, Patrick Lewis, Wen-tau Yih, Sebastian Riedel, and Fabio Petroni.
U+2753 Why → Language Models + Information Retrieval has been a hot topic from what we’ve seen in 2022. Conceptual barriers are being broken at the intersection of these two domains and the next generation of general-purpose search engines is emerging from it.
U+1F4A1 Key insights → Recently, we discussed the Differentiable Search Index⁵ (DSI) paper in our blog series and in our podcast: having an LM directly output document ids given a query, which worked surprisingly well. In some sense, this paper builds a somewhat related system that leverages LMs for retrieval, overcoming some of the limitations that DSI presented such as scalability, comfortably establishing a new state-of-the-art performance on benchmarks like the KILT benchmark⁶.
In a regular index, document features are precomputed and stored explicitly, like word counts or dense embeddings, such that given a query, a score can be computed as a proxy for passage relevance. In this case, an autoregressive text-to-text LM (aka GPT-like) learns distinctive n-grams for passages as their identifiers. At inference, given a query, the LM outputs the most likely n-grams in a constrained search, such that each n-gram gets a likelihood score that can be interpreted as a measure for passage relevance, resulting in a scalable retrieval. Well, there are actually quite a few more details to make this work, but it does work quite well achieving state-of-the-art on KILT.

After a few years of Neural Information Retrieval based on either cross-encoders or dense retrieval, the possibility of departing from these paradigms is exciting!
6. What Language Model Architecture and Pretraining Objective Work Best for Zero-Shot Generalization?
By Thomas Wang, Adam Roberts, Daniel Hesslow, Teven Le Scao, Hyung Won Chung, Iz Beltagy, Julien Launay, and Colin Raffel.
U+2753 Why → Recent history tells us that training large-scale LMs can yield transformative insights such as the emergence of impressive zero-shot performance in language tasks (e.g. GPT-3). But these insights are somewhat limited when only part of the picture is made public, which is where BigScience shines.
U+1F4A1 Key insights → BigScience is a community-driven effort spearheaded by Huggingface for training a large-scale multilingual language model that is resulting in several publications detailing its design, iterations, and training from an open-source spirit so the community can learn from the nitty-gritty details of what it really takes to train a large LM to the tiniest detail. The insights from this line of research have been published in recent months and this is the latest edition investigating the question of choice of architecture + learning objective.
The authors compare the combinations of architecture and training objectives: causal/non-causal decoder-only or encoder-decoder, and autoregressive vs. masked language modeling. TL;DR for zero and few-shot performance, the usual decoder-only autoregressive Language Modeling is the best choice of architecture and training objective.

7. OPT: Open Pre-trained Transformer Language Models U+007C Code U+007C Blog post
By Susan Zhang, Stephen Roller, Naman Goyal et al.
U+2753 Why → F̶a̶c̶e̶b̶o̶o̶k̶ Meta fully open sources their version of GPT-3 ahead of BigScience, which is training a similar but multilingual model out in the open and is expected to be released sometime in the upcoming months.
U+1F4A1 Key insights → To be honest, there’s not that much to say about it that hasn’t been said already, this is pretty much a GPT-3 clone with the big appeal that it’s the biggest pre-trained Language Model to be made fully public.
You’ll find the most interesting tidbits by browsing around the GitHub repository that contains the code, and instructions to deploy, train and run this model, along with the detailed reports and behind the scenes of training such a model.
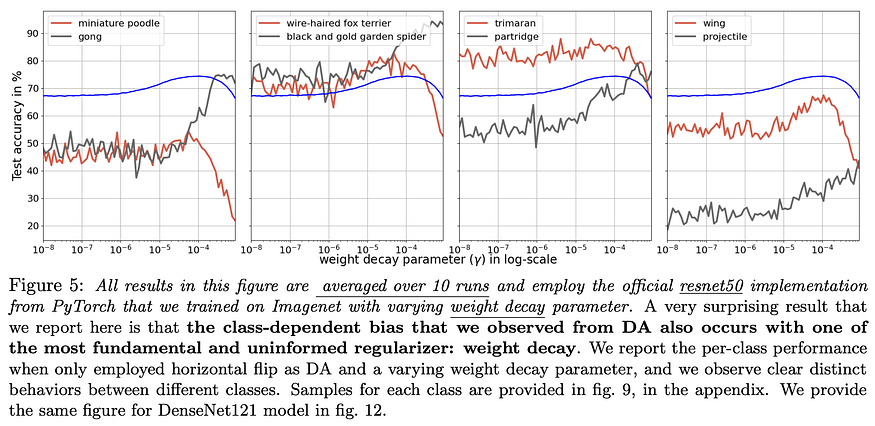
8. The Effects of Regularization and Data Augmentation are Class Dependent
By Randall Balestriero, Leon Bottou, and Yann LeCun.
U+2753 Why → Aggregated performance metrics are useful because they let us compare how various models perform by looking at a single quantitative score such as average performance. While this practice is widespread and useful, it might obscure qualitative behavior that’s highly relevant to the task at hand. In other words, two models with matching average performance might still present dramatically different failure modes, so it’s important to develop a holistic understanding of how a model behaves especially if it’ll be deployed and have an impact on tangible real-world decisions.
U+1F4A1 Key insights → Bias in ML models is often assumed to be caused by the training data; however it’s been shown that it can emerge as a consequence of other choices that might seem innocuous a priori such as the choice of loss/metric, pruning, data augmentation, etc. This paper shows how certain regularization techniques can hurt performance dramatically in a small group of classes while remaining almost undetectable at the aggregate performance metrics such as average accuracy.
This paper explores this phenomenon by training an image classifier with different data augmentation techniques such as random cropping or color jittering affects per-class performance. For instance, heavy color jittering affects negatively the accuracy of detecting a basketball, while zebra detection remains intact; or random cropping is a good augmentation for “nematodes” but terrible for lions when overdone. After an in-depth empirical and theoretical analysis, the paper ends with a call for novel bias-free regularization methods.
Results like these are tangible evidence of how easy it is to fool ourselves into thinking we understand how well an algorithm performs; a reminder that looking deeper than the surface-level metrics is essential particularly when models will be deployed out there. In addition, this paper is also a call for designing bias-free regularization methods.
9. A high-resolution canopy height model of the Earth
By Nico Lang, Walter Jetz, Konrad Schindler, and Jan Dirk Wegner.
U+2753 Why → This paper is just kinda random and cool and interesting.
U+1F4A1 Key insights → Canopy height is pretty much how tall vegetation is, which can be calculated as the elevation of the top of trees minus the elevation of the ground they’re on. It turns out that canopy height throughout the world is a salient quantity to the global carbon cycle, so modeling it more accurately at a global scale is key to the study of environmental phenomena like deforestation, climate change, or biodiversity modeling.
But accurately mapping how tall trees are all around the world is hard. The Global Ecosystem Dynamics Investigation (GEDI) is a mission designed to collect LiDAR data to measure vertical forest structures globally, but it’s constrained to sparse measurements that only account for 4% of the earth’s surface, and moreover, continuous measurement is not possible which makes studying evolution impossible. In contrast, optical satellite imagery such as that coming from Sentinel-2 is readily available. This work proposes to fuse these two data sources with Deep Learning to develop a probabilistic model of the earth’s canopy height.

Other recent works that will interest the environmentally-mindful folks are Machine Learning and Deep Learning — A review for Ecologists and The Carbon Footprint of Machine Learning Training Will Plateau, Then Shrink (Google is hopeful about their own future).
10. Datasets & Benchmarks
Given the amount of interesting dataset and benchmark works this month, we’ve decided to group them into this TL;DR listU+1F447
Benchmarking Generalization via In-Context Instructions on 1,600+ Language Tasks, NATURAL-INSTRUCTIONS v2 → Aims to measure the generalization of models to a variety of unseen tasks given a natural language instruction.
Winoground: Probing Vision and Language Models for Visio-Linguistic Compositionality → Like the Winograd schema challenge but for image-language pairs: ambiguous questions that require world knowledge to disambiguate.
MASSIVE: A 1M-Example Multilingual Natural Language Understanding Dataset with 51 Typologically-Diverse Languages → A new diverse multilingual NLU benchmark.
References:
[1] “U-Net: Convolutional Networks for Biomedical Image Segmentation” by Olaf Ronnenberger et al. 2015.
[2] “On the Opportunities and Risks of Foundation Models“ by Rishi Bommasani et al.
[3] “The information bottleneck method” by Naftali Tishby et al. 1999.
[4] ”Auto-Encoding Variational Bayes” by Diederik P. Kingma et al. 2013
[5] “Transformer Memory as a Differentiable Search Index” by Yi Tay et al. 2022
[6] “KILT: a Benchmark for Knowledge Intensive Language Tasks” by Fabio Petroni et al. 2020.
[7] “Hierarchical Text-Conditional Image Generation with CLIP Latents” by Aditya Ramesh et al. 2022.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

