


Transposed Weight Matrices in TensorFlow
Last Updated on June 4, 2024 by Editorial Team
Author(s): Malcolm Lett
Originally published on Towards AI.
I’ve been working through DeepLearning.AI’s “Machine Learning Specialization” course on Coursera. In one lab, we are asked to create a simple model within TensorFlow and to examine the shape of the weights produced by the model. But something caught my eye — the shape of the weights are in the wrong order.
The model is constructed as follows:
model = Sequential(
[
tf.keras.Input(shape=(2,)),
Dense(3, activation='sigmoid', name = 'layer1'),
Dense(1, activation='sigmoid', name = 'layer2')
]
)
The training data set contains 200 samples, with 2 features. Looking at the model summary we get the following:
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
layer1 (Dense) (None, 3) 9
layer2 (Dense) (None, 1) 4
=================================================================
Total params: 13
Trainable params: 13
Non-trainable params: 0
_________________________________________________________________
Here, “None” indicates that the model supports being run against batches of data. The model summary doesn’t give you the details of the input layer, but it too is represented as (None, …), eg:
tf.keras.Input(shap=(2,))
# Out: <KerasTensor: shape=(None, 2, 1) dtype=float32>
So for example, we could treat the activations from these layers as having dimensions:
- Input: (200, 2)
- Layer 1: (200, 3)
- Layer 2: (200, 1)
So far so good. The problem comes when we choose to look at the weights of a layer. The standard formula for calculating the output of a given layer follows this equation, where x is the input to the layer, and g(z) is some activation function:
Our first layer takes a feature vector of size 2 and outputs 3 values. Thus we’d expect the weight matrix W to be of size 3×2. However, if we examine the model we get the opposite:
W1 = model.get_layer("layer1").get_weights()
W1.shape
# Out: (2,3)
What’s going on? This doesn’t make any sense. If you plug that into the standard equation, you get an incompatible matrix dot product:
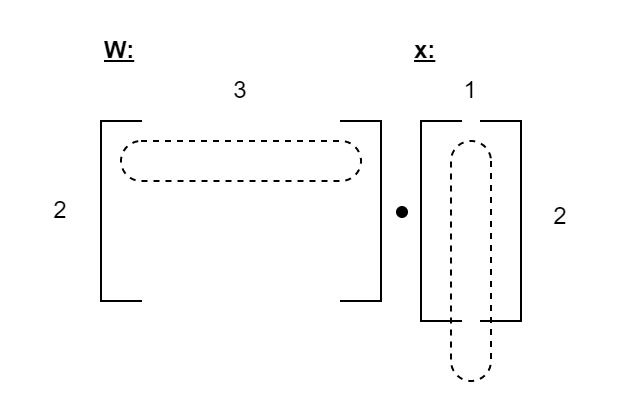
You can’t multiply a 2×3 matrix by a 2×1 matrix or vector, because there are not enough values in the vector.
TensorFlow weight representation
It turns out that TensorFlow doesn’t use the standard format in the same form used in the typical training material. It transposes W and then re-orders the components of the equation, which becomes:
The reason comes down to practicality, efficiency, and accuracy.
I wanted to understand why this is being done.
Vectorized computation revisor
Firstly, let’s look at a single dense NN layer. Let’s say that x has M features, and we have N samples, though we’ll consider just one sample to begin with. Our single layer has K neurons, producing K outputs. Ignoring the bias and activation function, the computation of the output is thus represented by:
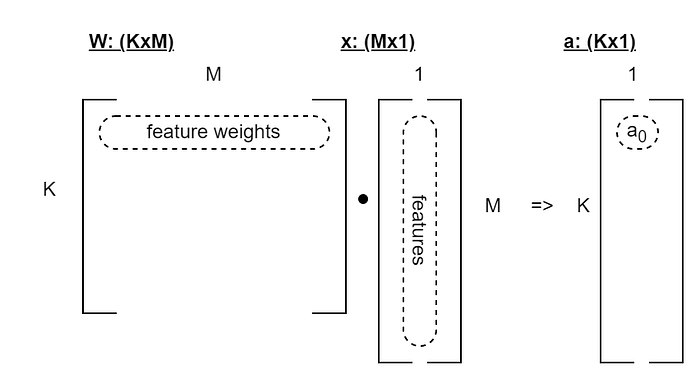
I’ve highlighted one row in the W matrix, the single column in the vector, and the resultant output cell in the activation vector. One important feature as I see it is that the highlighted row and column represent the input features to this layer. They must have the same size as each other. Additionally, the orientation of that highlighted row and column are always this way — because that’s how matrix dot products work. For example, you can’t just put x before W and flip the orientation.
When we do a prediction, say, using only a single data sample, then we just have that list of features and nothing else. But, importantly, those features are all equally part of the one data sample.
Now, consider a real data set. By the convention of data science, rows are the samples, and columns are the features of each sample. Thus, we have a matrix like this:

Notice that for a typical data set, you’ll have up to tens of features and many thousands of data samples.
TensorFlow was designed for large data sets. In particular, it is usually run in “batch mode”, calculating the results across multiple samples in parallel. If we take the same a=W⋅x + b pattern and lay that out, we get a dot product between two matrices and an activation matrix as a result:
Visually, the dot product part is represented as follows:
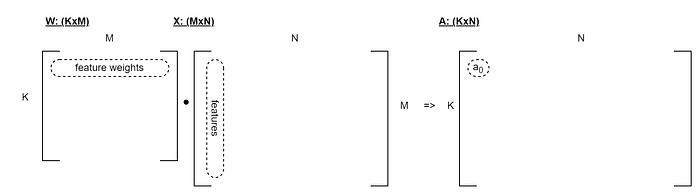
Notice that we’ve got very wide X and A matrices, for the N samples, which might be in the thousands or more.
There are two problems that I see with that:
Problem #1 — Transposing original dataset X before use:
- Matrices are internally stored as a flattened 1D array, with each row concatenated.
- To transpose a large matrix, you have to construct a brand new 1D array (think: memory consumption), and then run through the source array in a weird to-and-frow order, copying over values to form newly shaped rows (think: computation time). For small matrices, this is fine, but for large datasets, it’s a problem.
Problem #2 — Batching splits on the wrong axis
- For large data sets, the input rows are typically split up into batches of, say, 32 rows at a time. That enables us to maximize the use of the GPU’s internal capacity, but also to handle data sets that are larger than would fit in the GPU memory.
- That batching works on the rows in the data representation, because a) it’s designed to split up data sets in which each sample is a row, and b) you can efficiently select a subset of rows in the underlying 1D memory representation.
- If the X matrix has been transposed, then we’ll be batching across the rows in the transposed matrix, which means that we’ll be splitting it out at 32 features per batch, and still representing all N samples across its columns, eg: a (32×10000) matrix. Never mind the fact that this won’t fit in the GPU, because we’ve corrupted our data — splitting up the features for each sample into completely unrelated computations. The alternative would be to batch against the original X, and then copy each batch at a time, but it’s still just a mess of extra computations.
Transposed weights
The solution:
- Keep X as is, and transpose W instead.
- If we always operate on W in the transposed form, then we never need to transpose it back and forward, so we just eliminate that problem altogether.
This gives the revised equation as:
Furthermore, by following the convention that we always store and operate against the transposed W, we can forget about the transpose altogether. Visualizing, we now have:
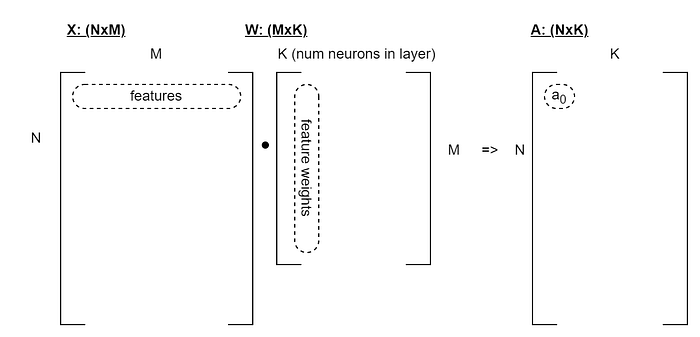
Extensions
To highlight how much better this is, consider how we can split out the data when there’s too much to fit into the GPU in a single go. Firstly, we can easily batch the data set 32 rows at a time. Secondly, because each neuron in a layer is independent of the others, we can calculate them in parallel — or in batches. So if we’ve got too many neurons in the layer, we can split them out into batches too. Thus we can split this operation as follows, without causing problems:
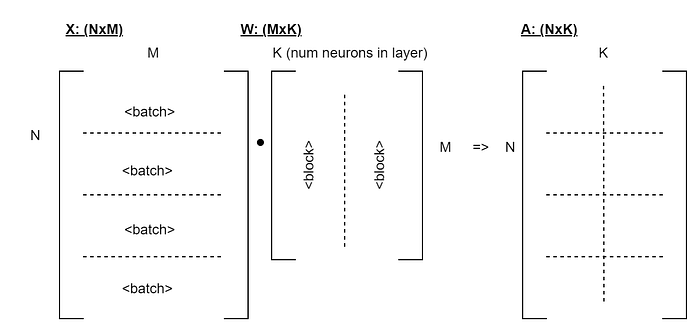
I’m not sure if that’s generally supported by TensorFlow, but I’m sure some have done it.
Conclusion
Neural networks operate on very simple principles, with very simple equations at their heart, but it can take a lot of work to mentalize what those equations are doing once you start dealing with vectorized data structures.
Here I have attempted to explain one small component of how typical neural networks are implemented. I hope you found it enlightening.
What strategies do you use to understand the data structures involved with machine learning?
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

