



The NLP Cypher | 06.06.21
Last Updated on July 24, 2023 by Editorial Team
Author(s): Ricky Costa
Originally published on Towards AI.
NATURAL LANGUAGE PROCESSING (NLP) WEEKLY NEWSLETTER
The NLP Cypher U+007C 06.06.21
Trinity
Welcome back to the simulation U+270C . So ACL 2021 data dump happened and now we have a huge list of repos to get through in the Repo Cypher this week. U+1F601
Also, we are updating the NLP index very soon with 100+ new repos (many of which are mentioned here) alongside 30+ new NLP notebooks like this one U+1F447 . If you would like to get an email alert for future newsletters and asset updates, you can sign-up here.
So let us start with incoming awesomeness. Heard of the Graph4NLP library??? If you want to leverage graph neural networks (GNNs) for your NLP tasks you may want to check them out (they’re in BETA). It runs on top of DeepGraphLibrary. Also, they have an awesome collection of papers on everything deep learning + graphs + NLP U+1F447.
https://github.com/graph4ai/graph4nlp_literature
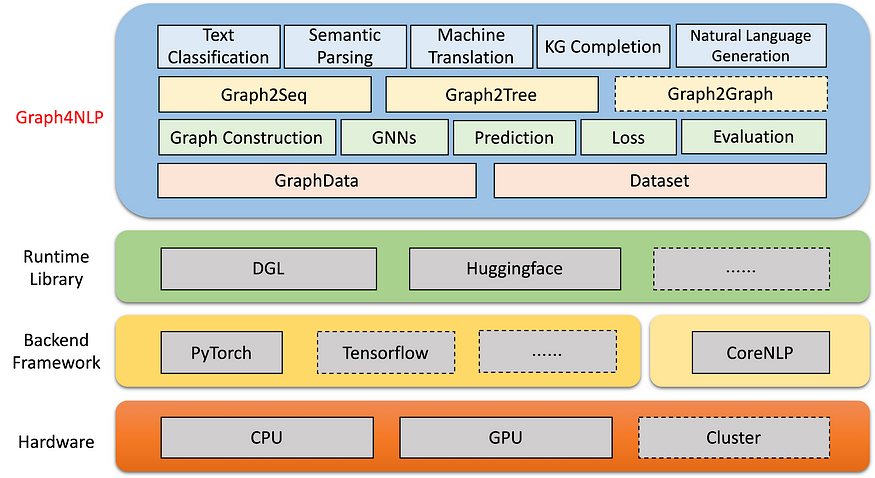
graph4ai/graph4nlp
Graph4NLP is an easy-to-use library for R&D at the intersection of Deep Learning on Graphs and Natural Language…
github.com
But wait, we need a simulation gut check
Oh… just an FYI. Aliens can’t be ruled out as the reason for all the aerial phenomena (~120 events) in the US according to sources in the Pentagon. The New York Times got an inside scoop on the upcoming UFO report being made ready by the DNI (Director of National Intelligence). Bottom-line, no-one has a clue of what is going on and it may be aliens. You can read the full article here:
U.S. Finds No Evidence of Alien Technology in Flying Objects, but Can’t Rule It Out, Either
If you want to do your own investigative work, the FAA has a database of unmanned aircraft sightings. Some involve military encounters. U+1F937U+2642️
FAA Data Shows Ongoing Pattern Of Military Encounters With Unidentified Aircraft In Sensitive…
Apart from the coastal events, an entirely separate cluster of incidents have been reported in a concentrated area in…
www.thedrive.com
Data:
UAS Sightings Report
Reports of unmanned aircraft ( UAS) sightings from pilots, citizens and law enforcement have increased dramatically…
www.faa.gov
So…
To conclude the intro: I’d like to welcome everyone to the halfway mark of the glorious year that is… 2021U+1F496U+1F496. A year where Elon runs crypto, aliens are real, and everyone wears masks. U+1F44D
and now… a word from our sponsors:
Important to Note: Elon Musk’s crypto shitposting is so lit that it got the attention of the hacker group Anonymous. I’m guessing they weren't too keen on Elon’s tweets swaying the crypto markets. As a result, they decided to G check him on sight. U+1F976U+1F976
Tokenizers Go Bye Bye: ByT5 Model
No need for intro: Google already gives one in their repo:
“ByT5 is a tokenizer-free extension of the mT5 model. Instead of using a subword vocabulary like most other pretrained language models (BERT, XLM-R, T5, GPT-3), our ByT5 model operates directly on UTF-8 bytes, removing the need for any text preprocessing. Beyond the reduction in system complexity, we find that parameter-matched ByT5 models are competitive with mT5 across a range of tasks, and outperform mT5 on tasks that involve noisy text or are sensitive to spelling and pronunciation. This repo can be used to reproduce the experiments in the ByT5 paper.”
google-research/byt5
ByT5 is a tokenizer-free extension of the mT5 model. Instead of using a subword vocabulary like most other pretrained…
github.com
… already merged in Transformers:
Binary Passage Retriever (BPR)
From the peeps that rolled out the LUKE model dropped ACL bombs on Twitter. They reduced the mem size of the Dense Passage Retriever (DPR) model w/o losing QA accuracy. U+270C
“Compared with DPR, BPR substantially reduces the memory cost from 65GB to 2GB without a loss of accuracy on two standard open-domain question answering benchmarks: Natural Questions and TriviaQA.” U+1F525U+1F525
studio-ousia/bpr
Binary Passage Retriever (BPR) is an efficient neural retrieval model for open-domain question answering. BPR…
github.com
The Good, the Bad and the Mysterious: GPT-3
Across a multi-scale paradigm, a change in quantity on one scale, is a change in quality in another.
Stanford decided to investigate GPT-3’s emergent phenomenon of few-shot learning. Warning Power laws incoming….

Extrapolating to Unnatural Language Processing with GPT-3's In-context Learning: The Good, the Bad…
In mid-2020, OpenAI published the paper and commercial API for GPT-31, their latest generation of large-scale language…
ai.stanford.edu
DoT: Double Transformer Model
Google has a new architecture for using transformers to parse table data.
“DoT, a double transformer model, that decomposes the problem into two sub-tasks: A shallow pruning transformer that selects the top-K tokens, followed by a deep task-specific transformer that takes as input those K tokens.”
Repo Cypher U+1F468U+1F4BB
A collection of recently released repos that caught our U+1F441
SemEval2021 Reading Comprehension of Abstract Meaning
Task is designed to help evaluate the ability of machines in representing and understanding abstract concepts. Multiple-choice dataset.
boyuanzheng010/SemEval2021-Reading-Comprehension-of-Abstract-Meaning
This is the repository for SemEval 2021 Task 4: Reading Comprehension of Abstract Meaning. It includes code for…
github.com
Connected Papers U+1F4C8
Directed Sentiment Analysis in News Text
A dataset and code for extracting sentiment relationships between political entities in news text.
bywords/directed_sentiment_analysis
This repository provides a dataset and code for extracting sentiment relationships between political entities in news…
github.com
Connected Papers U+1F4C8
SapBERT: Self-alignment pretraining for BERT
Introduces a novel cross-lingual biomedical entity task (XL-BEL), establishing a widecoverage and reliable evaluation benchmark for cross-lingual entity representations in the biomedical domain in 10 languages.
cambridgeltl/sapbert
This repo holds code, data, and pretrained weights for (1) the SapBERT model presented in our NAACL 2021 paper…
github.com
Connected Papers U+1F4C8
CIDER: Commonsense Inference for Dialogue Explanation and Reasoning
CIDER — a manually curated dataset that contains dyadic dialogue explanations in the form of implicit and explicit knowledge triplets inferred using contextual commonsense inference.
declare-lab/CIDER
This repository contains the dataset and the pytorch implementations of the models from the paper CIDER: Commonsense…
github.com
Connected Papers U+1F4C8
Transformer-based Text Classifier: Simple yet Identifiable
Source code for observing the identifiability of attention weights.
declare-lab/identifiable-transformers
This repository helps: Someone who is looking for a quick transformer-based classifier with low computation budget…
github.com
Connected Papers U+1F4C8
DynaEval
DynaEval serves as a unified framework for both turn and dialogue level evaluation in open-domain dialogue.

e0397123/DynaEval
conda env create -f environment.yml conda activate gcn processed datasets can be found at…
github.com
Connected Papers U+1F4C8
NeuralLog: Natural Language Inference with Joint Neural and Logical Reasoning
A symbolic and neural inference system that improves accuracy on the NLI task and can achieve state-of-art accuracy on the SICK and MED datasets.
eric11eca/NeuralLog
Deep learning (DL) based language models achieve high performance on various benchmarks for Natural Language Inference…
github.com
Connected Papers U+1F4C8
Lightweight Adapter Tuning for Multilingual Speech Translation
formiel/fairseq
This is the codebase for the paper Lightweight Adapter Tuning for Multilingual Speech Translation (ACL-IJCNLP 2021)…
github.com
Connected Papers U+1F4C8
Commit Autosuggestions
Using CodeBERT, newly
patch_type_embeddingsare introduced that can distinguish between added and deleted code.

graykode/commit-autosuggestions
Have you ever hesitated to write a commit message? Now get a commit message from Artificial Intelligence! CodeBERT: A…
github.com
Connected Papers U+1F4C8
MPC-BERT: A Pre-Trained Language Model for Multi-Party Conversation Understanding
MPC-BERT, a pre-trained model for Multi-Party Conversation (MPC) understanding that considers learning who says what to whom in a unified model with several elaborated self-supervised tasks.
JasonForJoy/MPC-BERT
This repository contains the source code for the ACL 2021 paper MPC-BERT: A Pre-Trained Language Model for Multi-Party…
github.com
Connected Papers U+1F4C8
U+1F9A6 OTTers: One-turn Topic Transitions for Open-Domain Dialogue
A new dataset of human one-turn topic transitions.
karinseve/OTTers
Data analysis scripts coming soon! You can download the data already divided in the two in-domain and out-of-domain…
github.com
Connected Papers U+1F4C8
U+1F333 Fingerprinting Fine-tuned Language Models in the Wild
Experiments conducted to demonstrate the limitations of existing fingerprinting approaches in language models.
LCS2-IIITD/ACL-FFLM
This is the code and dataset for our ACL 2021 (Findings) Paper – Fingerprinting Fine-tuned Language Models in the wild…
github.com
Connected Papers U+1F4C8
SpanNER: Named Entity Re-/Recognition as Span Prediction

neulab/SpanNER
Two roles of span prediction models (boxes in blue): as a base NER system as a system combiner. This repository…
github.com
Connected Papers U+1F4C8
COM2SENSE: A Commonsense Reasoning Benchmark with Complementary Sentences
A new commonsense reasoning benchmark dataset comprising natural language true/false statements, with each sample paired with its complementary counterpart, resulting in 4k sentence pairs.
PlusLabNLP/Com2Sense
Models for the Commonsense Dataset Construction project Please download the model weights from Google-drive, and place…
github.com
DialoGraph
Incorporating interpretable strategy graph networks into negotiation dialogues.
rishabhjoshi/DialoGraph_ICLR21
Code, Data, Demo coming soon!! Please cite the following paper if you use this code in your work. @inproceedings{…
github.com
Controllable Abstractive Dialogue Summarization with Sketch Supervision
salesforce/ConvSumm
Chien-Sheng Wu*, Linqing Liu*, Wenhao Liu, Pontus Stenetorp, Caiming Xiong Please cite our work if you use the code or…
github.com
Connected Papers U+1F4C8
Zero Shot Fact Verification by Claim Generation

teacherpeterpan/Zero-shot-Fact-Verification
Please cite the paper in the following format if you use this dataset during your research.
github.com
Connected Papers U+1F4C8
TransQuest: Translation Quality Estimation with Cross-lingual Transformers
TharinduDR/TransQuest
The goal of quality estimation (QE) is to evaluate the quality of a translation without having access to a reference…
github.com
Connected Papers U+1F4C8
CitationIE
This work augments text representations by leveraging a complementary source of document context: the citation graph of referential links between citing and cited papers. This is used for information extraction in science papers.

viswavi/CitationIE
This repository serves two purposes: Provides tools for joining the SciREX dataset with the S2ORC citation graph.
github.com
Connected Papers U+1F4C8
HERALD: An Annotation Efficient Method to Train User Engagement Predictors in Dialogs
HERALD, an annotation efficient framework that reframes the training data annotation process as a denoising problem.

Weixin-Liang/HERALD
This repo provides the PyTorch source code of our paper: HERALD: An Annotation Efficient Method to Train User…
github.com
Connected Papers U+1F4C8
Discriminative Reasoning for Document-level Relation Extraction
This new method outperforms the previous state-of-the-art performance on the large-scale DocRE dataset.
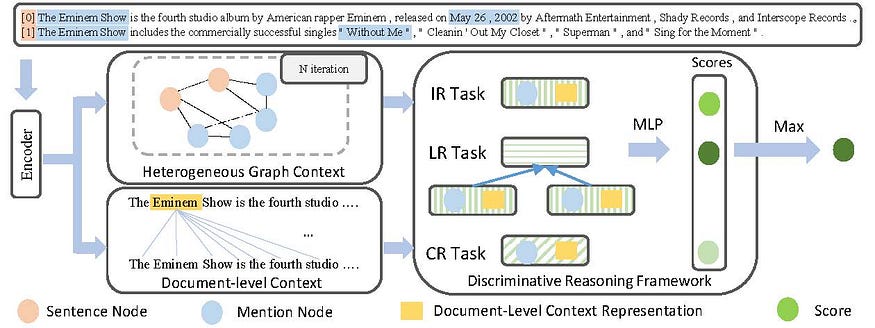
xwjim/DRN
PyTorch implementation for ACL 2021 Findings paper: Discriminative Reasoning for Document-level Relation Extraction…
github.com
Connected Papers U+1F4C8
ConvoSumm: Conversation Summarization Benchmark
A total of four datasets evaluating a model’s performance on a broad spectrum of conversation data. This is for summarization.
Yale-LILY/ConvoSumm
Data, code, and model checkpoints for the ACL 2021 paper ConvoSumm: Conversation Summarization Benchmark and Improved…
github.com
Connected Papers U+1F4C8
OntoGUM: Evaluating Contextualized SOTA Coreference Resolution on 12 More Genres
A dataset consistent with OntoNotes, with 168 documents (∼150K tokens, 19,378 mentions, 4,471 coref chains) in 12 genres, including conversational genres.
yilunzhu/ontogum
This repository contains the code for building up the OntoGUM dataset from: Python >= 3.6 Download GUM from…
github.com
Connected Papers U+1F4C8
Attention-Based Contextual Language Modeling Adaptation
amazon-research/contextual-attention-nlm
This project provides the source to reproduce the main methods of the paper “Attention-Based Contextual Language Model…
github.com
Connected Papers U+1F4C8
MedNLI Is Not Immune: Natural Language Inference Artifacts in the Clinical Domain
crherlihy/clinical_nli_artifacts
This repository contains the source code required to reproduce the analysis presented in the paper “MedNLI Is Not…
github.com
Connected Papers U+1F4C8
Dataset of the Week: CoDesc
What is it?
Dataset consisting of 4.2M Java source code and parallel data of their description from code search, and code summarization studies.
Where is it?
csebuetnlp/CoDesc
This is the public release of code, and data of our paper titled "CoDesc: A Large Code-Description Parallel Dataset"…
github.com
Every Sunday we do a weekly round-up of NLP news and code drops from researchers around the world.
For complete coverage, follow our Twitter: @Quantum_Stat
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

