



The Ever-evolving Pre-training Tasks for Language Models
Last Updated on December 28, 2022 by Editorial Team
Author(s): Harshit Sharma
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
Self-Supervised Learning (SSL) is the backbone of transformer-based pre-trained language models, and this paradigm involves solving pre-training tasks (PT) that help in modeling the natural language. This article is about putting all the popular pre-training tasks at a glance.
Loss function in SSL
The loss function here is simply the weighted sum of losses of individual pre-training tasks that the model is trained on.
Taking BERT as an example, the loss would be the weighted sum of MLM (Masked Language Modelling) and NSP (Next Sentence Prediction)
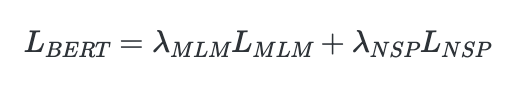
Over the years, there have been many pre-training tasks that have come up to solve specific problems. We will be reviewing 10 of the interesting and popular ones along with their corresponding loss functions:
- Causal Language Modelling (CLM)
- Masked Language Modelling (MLM)
- Replaced Token Detection (RTD)
- Shuffled Token Detection (STD)
- Random Token Substitution (RTS)
- Swapped Language Modelling (SLM)
- Translation Language Modelling (TLM)
- Alternate Language Modelling (ALM)
- Sentence Boundary Objective (SBO)
- Next Sentence Prediction (NSP)
(The loss functions for each task and the content is heavily borrowed from AMMUS : A Survey of Transformer-based Pretrained Models in Natural Language Processing)

- It's simply a Unidirectional Language Model that predicts the next word given the context.
- Was used as a pre-training task in GPT-1
- The loss for CLM is defined as:
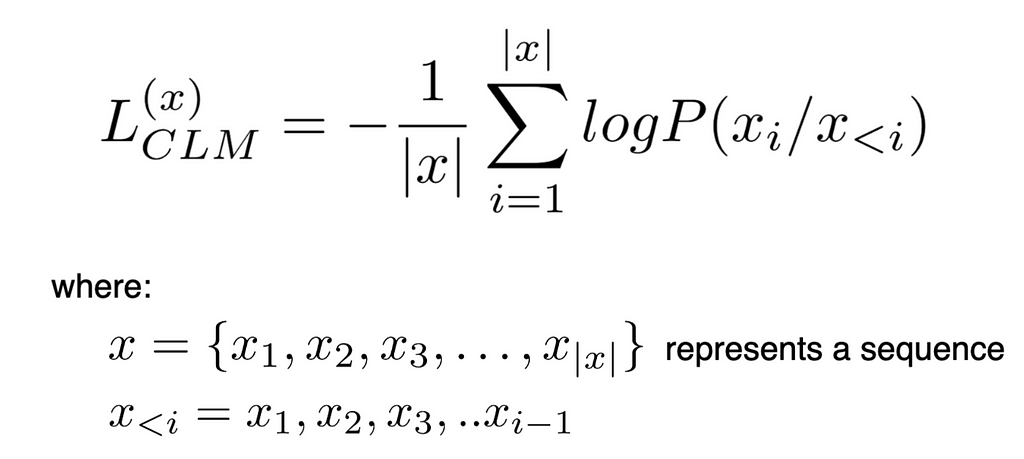

- An improvement over Causal Language Modelling (CLM), since CLM only takes unidirectional context into consideration while predicting text, whereas MLM uses bi-directional context.
- It was first used as a pre-training task in BERT
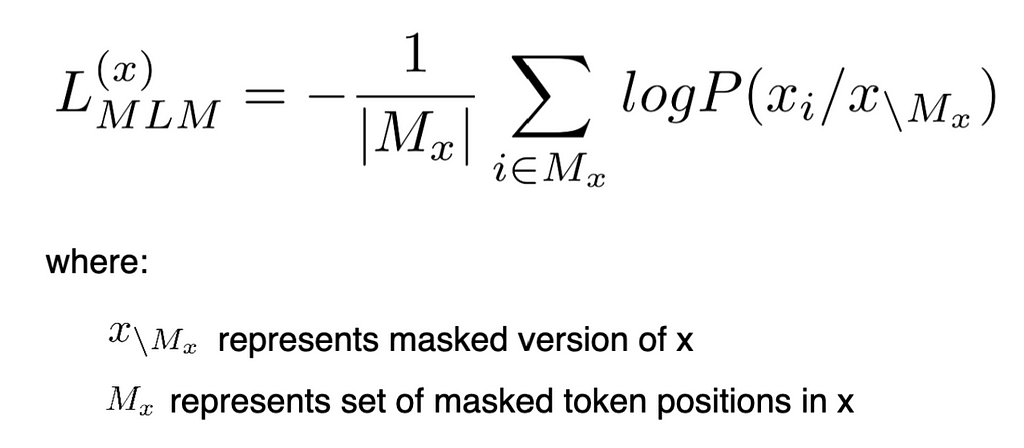

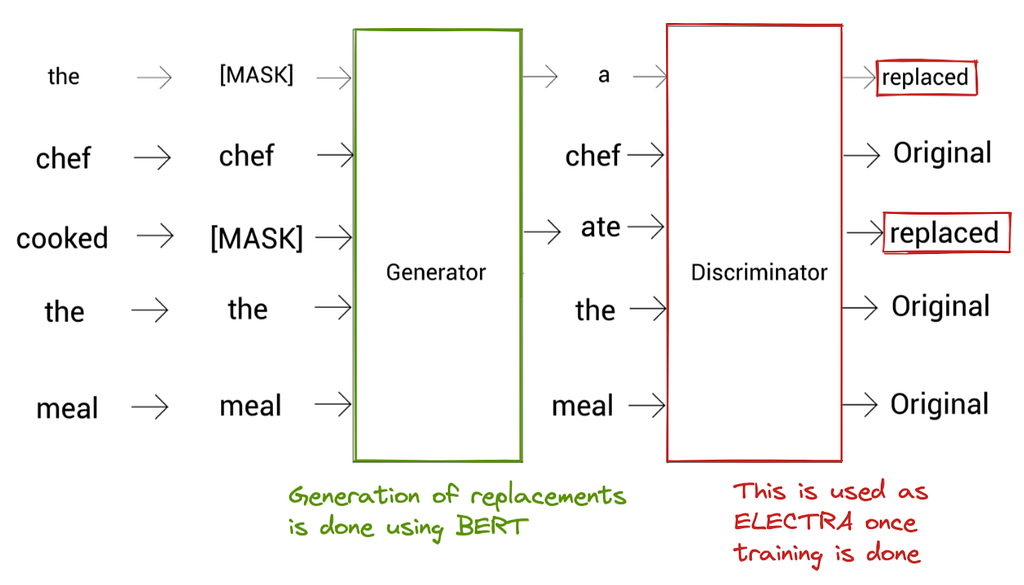
- Instead of masking tokens with [MASK], RTD replaces a token with a different token (using a generator model) and trains the model to classify whether the given tokens are actual or replaced tokens (using a discriminator model)
- Improves over 2 of the following drawbacks of MLM:
Drawback 1:
[MASK] token appears while pre-training but not while fine-tuning — this creates a mismatch between the two scenarios.
RTD overcomes this since it doesn’t use any masking
Drawback 2:
In MLM, the training signal is only given by 15% of the tokens since the loss is computed just using these masked tokens, but in RTD, the signal is given by all the tokens since each of them is classified to be “replaced” or “original”
- RTD was used in ELECTRA as a pre-training task. The ELECTRA architecture is shown below:


- Similar to RTD, but the tokens here are classified to be shuffled or not, instead of replaced or not (shown below)
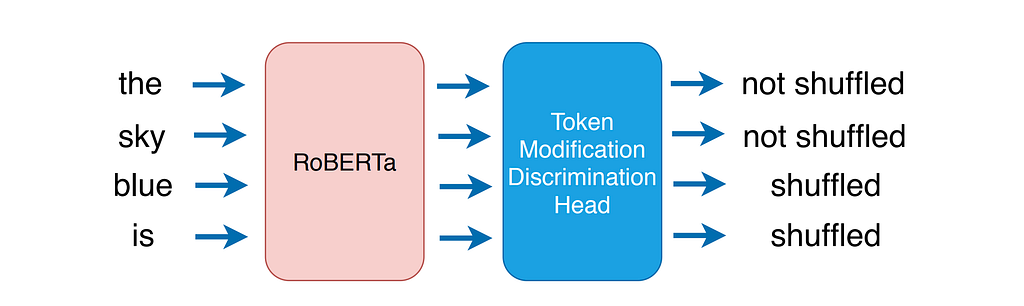
- Achieves similar sample efficiency as in RTD compared to MLM
- Loss is defined as:


- RTD uses a generator to corrupt the sentence, which is computationally expensive.
RTS bypasses this complexity by simply substituting 15% of the tokens using tokens from the vocabulary while achieving similar accuracy as MLM, as shown here.


- SLM corrupts the sequence by replacing 15% of tokens with random tokens.
- It's similar to MLM in terms of trying to predict corrupted tokens, but instead of using [MASK], random tokens are used for masking
- It's similar to RTS in terms of using random tokens for corrupting, but unlike RTS, it's not samply efficient, since only 15% of tokens are used for providing training signal.
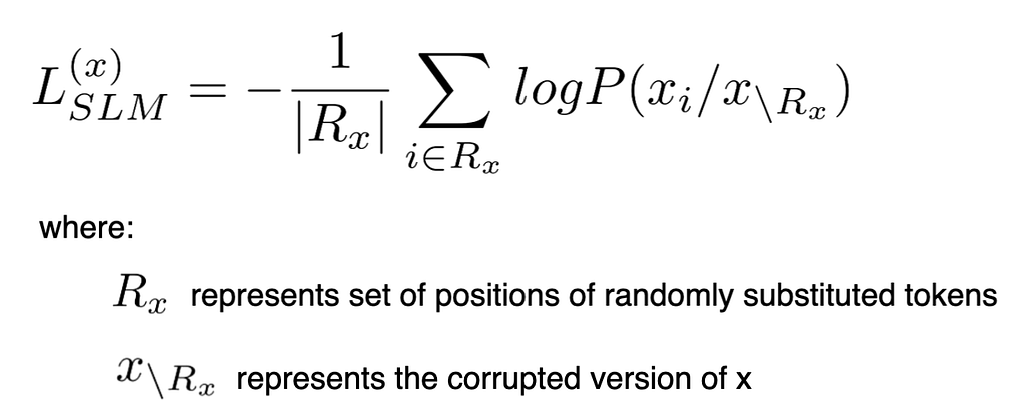

- TLM is also known as cross-lingual MLM, wherein the input is a pair of parallel sentences (sentences from two different languages) with the tokens masked as in MLM
- It was used as a pre-training task in XLM, a cross-lingual model to learn cross-lingual mapping.
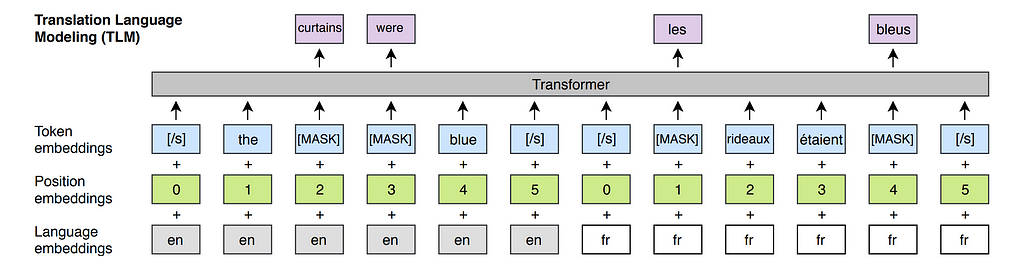
- TLM loss is similar to MLM loss:


- It's a task to learn a cross-lingual language model just like TLM, where the parallel sentences are code-switched, as shown below:

While code-switching, some phrases of x are substituted from y, and the sample thus obtained is used to train the model.
- The masking strategy is similar to MLM.


- Involves masking of a contiguous span of tokens in a sentence and then using the model to predict the masked tokens based on the output representations of boundary tokens
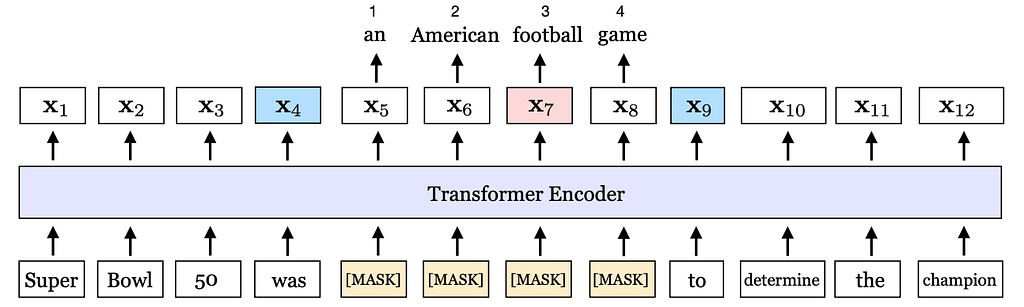
- Was used as a pre-training task in SpanBERT
- Loss is defined as:


- It's a sentence-level task that helps the model in learning the relationship between the sentences.
- It's a binary classification task that involves identifying if the two sentences are consecutive, using the output representation of [CLS] token.
- The training is done using 50% positive and 50% negative samples where the second sentence is not consecutive to the first sentence.
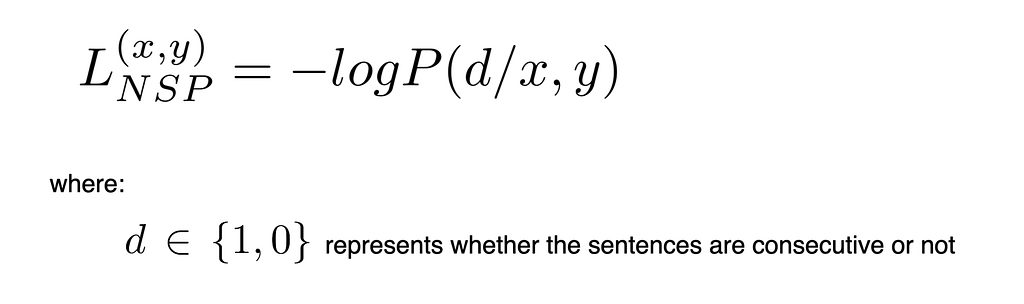
There are many other interesting tasks that are summarized in AMMUS !! Kudos to the authors, and please give it a read if you find this interesting)
The Ever-evolving Pre-training Tasks for Language Models was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

