



The Curious Case of How MS-excel Was a Nightmare for Bioinformatics
Last Updated on August 3, 2022 by Editorial Team
Author(s): Salvatore Raieli
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
An example of how Ms-Excel can be deleterious in data science
How do we have no power in front of Excel’s habit of arbitrarily changing the format to what it does like?
The unforgettable sin of Ms-Excel of deciding by itself
There is no shortage of science fiction films where machines decide to ignore human orders and rebel (2001: A Space Odyssey, to name the most famous). Anyone who has worked with Ms-Excel might think that this dystopian future is not such an impossible eventuality.
Dave: Open the pod bay doors, HAL.
HAL: I’m sorry, Dave. I’m afraid I can’t do that.
2001: A space Odissey
I don’t know why, but Ms-Excel is fascinated by dates, and this passion results in randomly turning numbers and acronyms into dates. In 2016, a scientific article conducted an analysis on the phenomenon and realized that around 20% of the articles in the literature contain errors related to Ms-Excel. For example, SEPT2 (Septin 2) and MARCH1 (Membrane-Associated Ring Finger (C3HC4) 1, E3 Ubiquitin Protein Ligase) are converted by default to ‘2-Sep’ and ‘1-Mar’. Sometimes, MS-Excel does even better: it transforms SEPT2 in ‘2006/09/02’. There is no way you can turn off this auto-format feature and correcting it is a painstaking process.
In the same article, they analyzed more than 35,000 articles from 2005 to 2015, showing that every journal was impacted. Ironically, the most impacted journal in the analysis is Nature, which is considered the bible of science journals.
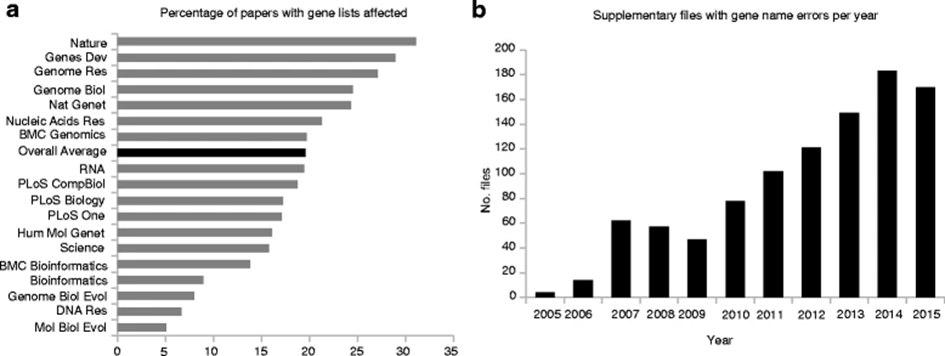
The omics revolution
The right panel also show how the problem increased dramatically year after year. In fact, the Omics revolution started in the 2000s when next-generation sequences started to be much cheaper and widespread. Nowadays, few articles have not performed some omics analysis (like RNAseq, ChipSeq, and so on). Why? Because these new techniques are able to provide a snapshot of a tumor or tissue. To date, they have achieved single-cell resolution (e.g., single-cell RNAseq).
Since you can obtain a huge amount of information, these analyses are becoming ubiquitous. From cancer research to clinical trials, scientists are relying more on the output of some sequencing. These large sequencings generate terabytes of data each year, and to analyze them, it is necessary to use Bash scripts, R, and python.
Considering the need to use sophisticated scripts to analyze all this data, one would think that the situation has improved and that we no longer have to worry about Ms-Excel. Instead, an article from 2021 shows that we have not learned our lesson and MS-Excel is more alive than ever.

As can be seen, the number of errors did not decrease (it remained constant if not increased).
Why spreadsheet are so spread?
It is difficult to associate Ms-Excel with biology or other scientific disciplines, yet it is everywhere. Not just because it is generally installed by default on all computers in laboratories and hospitals. Its success lies in the fact that, in spite of all its bugs and other farfetched annoyances, it allows a lot of analysis to be conducted quickly. Students and professors can open a plethora of files and do basic analysis and visualizations within minutes. In addition, it is also one of the accepted formats when submitting a publication to a scientific journal.
Certainly, R and Python are much better performers, allowing for a much more sophisticated and complex analysis of a huge amount of data and graphs. On the other hand, you have to know the syntax and install libraries, and you waste a lot of time in a series of errors. So when you are tired, that green icon on the desktop is… so so inviting.

Can we solve it?
In 2017, the HUGO Gene Nomenclature Committee (HGNC) decided to rename 27 genes to avoid confusion. Since these committees are generally really difficult to organize and normally conservative in their choices, imagine how much annoyed they were to decide to rename genes just to make them Excel-friendly. However, as we have seen, this was not enough.
Researchers proposed different solutions: in fact, the 2016 article already proposed a script to solve the issue. In 2022 (which shows that this problem still matters) other researchers proposed a web tool to autocorrect Excel misidentified gene names (which you can find here).
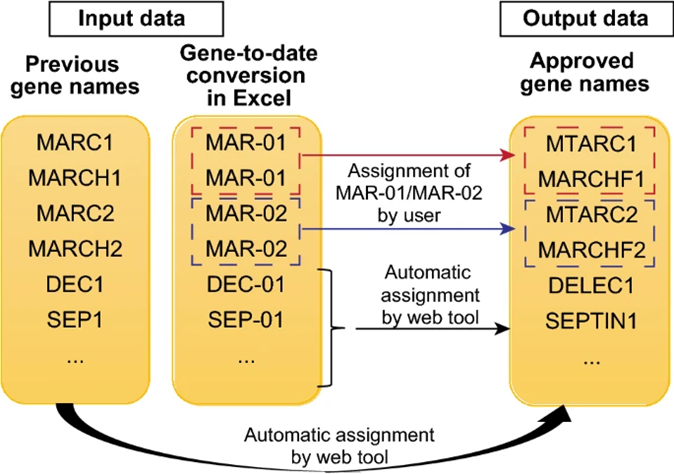
It is still too early to say if these efforts will solve the issue or if Ms-Excel will still haunt the sleep of the researchers.
Conclusions and take-away
“It’s Excel’s world, we just live in it.”
— jgalt212 on HackerNews
HGNC has created guidelines on how to decide on a name for a gene (which generally are directed against human stupidity and avoid dumb or offensive names being chosen). However, they forgot the computer stupidity and how Ms-Excel is widespread. True, scientists could abandon Ms-Excel, but it is installed everywhere, and sometimes you need to be quick.
The beauty of this story is the fact that it only takes an insignificant detail to have large-scale nefarious effects. Potentially simple Ms-Excel errors (hopefully unintentional, or it is already part of the machine's plan to take over the world?) can be dragged on for years. An article in Nature can have dozens if not hundreds of citations and influence researchers around the world. After all, genetic testing is becoming increasingly common, and cancer therapies are increasingly decided on mutational profiling. So extreme caution in analyzing articles or lists of genes would be necessary.
This story also teaches us that data collection and selection are critical, but so is the choice of algorithms and software. Moreover, Ms-Excel is showing strange behaviors with different types of data (for example, numbers or strings) and should be avoided in data science (to avoid deleterious effects). In addition, one should always think about the end user because they could be used in an unimagined way with catastrophic results.
if you have found it interesting:
You can look for my other articles, you can also subscribe to get notified when I publish articles, and you can also connect or reach me on LinkedIn. Thanks for your support!
Here is the link to my Github repository, where I am planning to collect code and many resources related to machine learning, artificial intelligence, and more.
The Curious Case of How MS-excel Was a Nightmare for Bioinformatics was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts






")