



Test-Driven Application Development with Large Language Models
Last Updated on July 17, 2023 by Editorial Team
Author(s): Prajwal Paudyal
Originally published on Towards AI.
The following are my insights about Test Driven Application Development for Large Language Model powered applications.
I have been working on an application that generates late-night-style TV shows and stand-up comedy videos in an end-to-end automated way. If you haven’t seen it, I have posted a few episodes already on this channel; check it out!
If you find the content helpful, please subscribe. I’ll post details about the application I’m building in subsequent posts.
TLDR;
Developing applications with Large Language Models (LLMs) using Test Driven Development (TDD) presents several challenges and insights.
- Testing generative models like LLMs is difficult given their complexity and the ‘creative’ nature of output — but it is crucial for automation and safety.
- The nature of testing is shifting; it’s easier to discriminate than generate. Therefore using another LLM to test the outputs of the original LLM can be beneficial.
- Not all LLMs are created equally. Thus, the selection is crucial and should be done according to the use case and by following relevant benchmarks as well as privacy, security, and cost. considerations. Robustness is another important consideration and can be done using perturbation testing, ensuring that similar inputs give similar outputs.
- Duck typing in Python is powerful but can cause integration headaches like runtime errors, incorrectness, and difficulties in generating code and documentation. Tools like MyPy and Pydantic are a must for type-checking and output parsing.
- Execution testing involves checking the output of LLMs. Two ways to accomplish this are compile-time property testing (tuning instructions or prompts) and run-time output testing (using another LLM to auto-generate test cases).
- Bug discovery, planning, and iteration require an interactive approach with the LLM, prioritizing recall over precision. Using an LLM to enumerate and iterate on use cases and test cases is suggested, with the added advantage of LLMs being excellent at summarizing and categorizing information.
Types of testing — by Development Stage
First things first, testing generative models is tough due to the ‘creative’ nature, but it is fundamentally essential, especially with instruction-tuned and safety aligned models. One of the frequent failure cases is the model refusing to produce an output and answering with “As a language model ..” .
While developing the LLM application in a TDD way, I have found it helpful to think of the various types of tests needed by the ‘stage’ of development.
Stage One: LLM Selection
The starting point of my process was realizing that not all LLMs are identical. The demands of particular use-cases may necessitate specialized LLMs, taking into account quality and privacy requirements. Here’s what I focused on during selection:
1. Benchmarks
Benchmarks are useful to select LLMs if the intended output task is close enough to a standard benchmark.
GPT-4 has released performance on several benchmarks . Likewise, the Open LLM Leaderboard aims to objectively track, rank, and evaluate the proliferation of large language models (LLMs) and chatbots, sifting through the hype to showcase genuine progress in the field. The models are evaluated on four main benchmarks from Eleuther AI-Language Model Evaluation Harness, ensuring comprehensive assessment across diverse tasks. The leaderboard also enables community members to submit their Transformer models for automated evaluation on the platform’s GPU cluster. Even models with delta-weights for non-commercial licenses are eligible. The selected benchmarks — AI2 Reasoning Challenge, HellaSwag, MMLU, and TruthfulQA — cover a broad spectrum of reasoning and general knowledge, tested in 0-shot and few-shot scenarios.
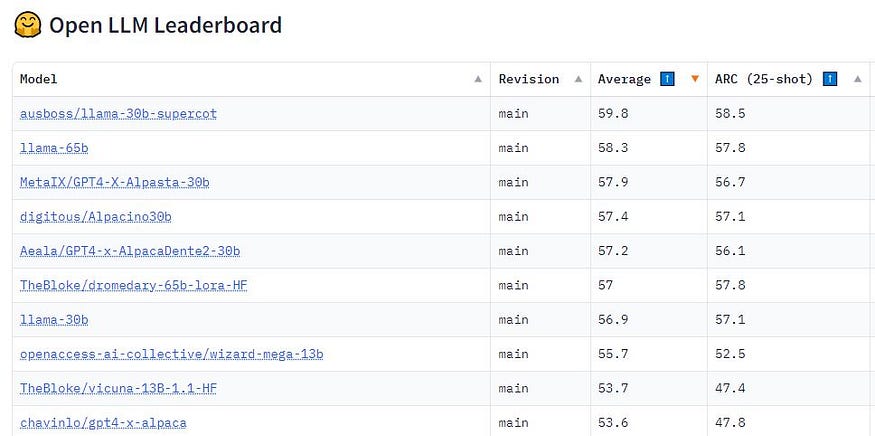
2. Perturbation testing:
LLMs intended to be used with variable prompts, must be locally consistent to inputs that are semantically similar. One way to test this by perturbation testing with an LLM powered test suite.

The general approach is as follows:
- Introduce Perturbations: Utilize another LLM to rephrase the original prompt while retaining its semantic essence. Then, supply the perturbed and original prompts to the LLM under assessment.
- Analyze Generated Outputs: Assess the generated responses for either accuracy (if a standard response is available) or consistency (judged by the similarity of generated outputs if no standard response exists). — The essence of this article
- Iterate: Any errors should lead insights towards better prompts, different models, better instruction tuning, etc.
Read the excellent article and tool by FidderAI on Perturbation testing.
Stage Two: Type checking and Integration Testing
Python, the lingua franca of this domain, provided the flexibility of duck-typing, crucial for quick iterations. However, to develop robust software engineering applications, I found it indispensable to ensure thorough syntactic correctness. I would advise always using type-hints, but handle or fail gracefully instead of enforcing breaking errors during run time. Here are some tools I found useful:
- MyPy: An efficient static type checker for Python.
- Pydantic: It has become my go-to tool for output parsing. It's high extensibility and excellent integration with Langchain are bonus points.
- Langchain: The output parsers in Langchain can be employed to create repeated instructions for output as well as automated tests.
Beyond this, integration testing is not much different for LLM applications than for other software applications, so I won’t go into much detail.
Stage Three: Runtime Output Testing
Testing the outputs of a generative model can be tricky, a.k.a. The ‘test oracle’ problem. Nevertheless, using the principle that discrimination is less complex than generation can be helpful here.
Property-based software testing, such as metamorphic testing, is a useful approach for addressing the test oracle problem as well as for test case generation. In essence, this is done by testing on a known or derivable property.
For example, when testing a response to a query, how many distinct cities are there in a particular state; how do we determine if the results of this are correct and complete? This is a test Oracle problem. Based on a metamorphic relation, we can ask the LLM to tell us how many cities are there in the state that begin with the letters A through M. This should return a subset of the previous results. A violation of this expectation would similarly reveal a failure of the system. In this case, several tests can be determined either during development or live during runtime, as explained below. Property-based testing and MT in general were originally proposed as a software verification technique, the concepts cover verification, validation, software quality assessment.
Pre-composed Property testing:
This is particularly useful for instruction tuning or prompt engineering. For instance, if the LLM is supposed to summarize a webpage while eliminating all hyperlinks and emojis, I would start by writing straightforward procedural test cases or LLM prompts for these tasks.
This approach works well if the types of output expected are known in advance. In these scenarios, the testing isn’t much different than what is possible by using testing frameworks like Robot, Pytest, Unittest, etc. Using semantic similarity with a threshold for fuzziness is useful.
For instance:
- Application to extract and summarize the ‘main’ article in a webpage while ignoring extra links, comments, etc. Then a battery of tests can be designed using existing known web pages. Positive examples: Semantics matches the main page. Negative examples: Unrelated topics
- Application to remove negative sentiments, emojis, etc., and summarize text to less than 3 sentences. Test using procedural or LLM models to test those cases specifically.
This is an important topic, so let’s dive further.
Concept: Discrimination is easier than generation
It is counter-intuitive to think of using another model to test the output of a model. If the second model can ‘grade’ the output, why not use the second model to generate the output in the first place?
For instance, In Generative Adversarial Networks (GANs), two components, the Generator and the Discriminator, interact in a game-theoretic way. The Generator creates new data instances while the Discriminator assesses these instances for authenticity. This structure exemplifies the idea that “discrimination is easier than generation.”
The Generator’s task is to generate new data, such as images, that convincingly mimic real-world examples. This requires learning complex patterns and subtleties, making it a difficult and intricate job.
In contrast, the Discriminator’s role is to classify whether given data instances are real or generated. This task is relatively simpler as it involves identifying distinguishing patterns and features without the need to understand how to create the data instances.
Take the following example. The first image was created using Stable Diffusion (by the author) for the prompt:
A cat holding a water bottle in front of big ben on a rainy day, is a difficult image to create, but it is easier to perceive that there is a cat in the image.

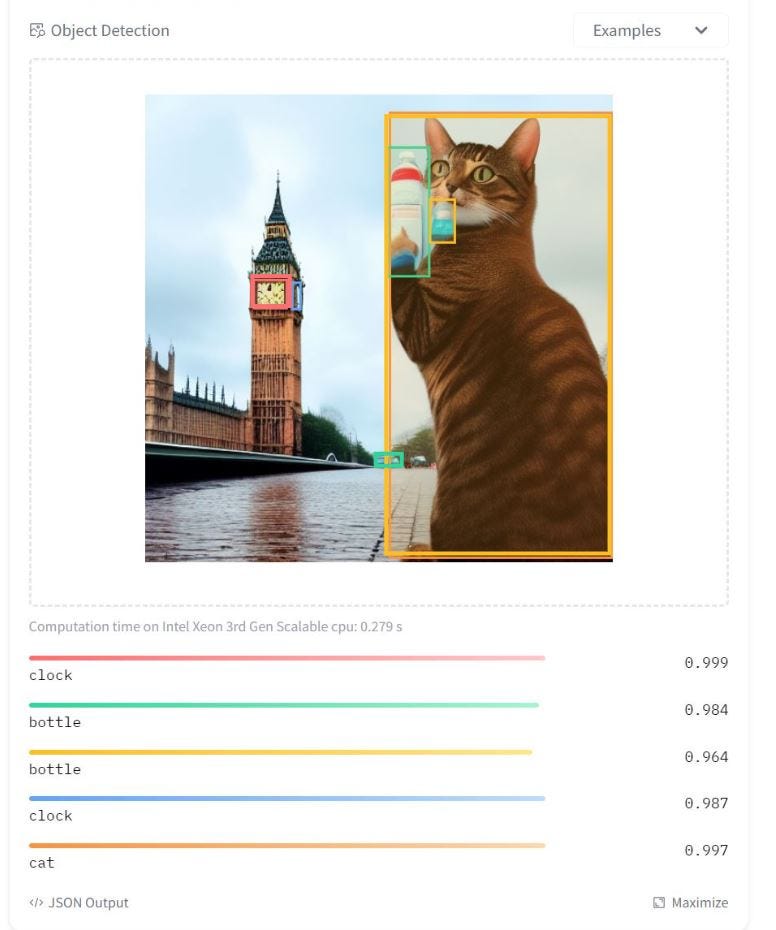
Use an LLM to runtime test an LLM — Use a separate model as a discriminator to verify if the conditions are met
The generative model needs to not only understand what is ‘cat’ is well enough to create it, but also needs to understand what a bottle is, what big Ben is, and what it means to be a rainy day, and compose it all together (it does give the cat a human hand, but oh well!). However, the discriminative model only needs to understand each of these concepts in isolation, as in the figure below.

Thus, even if you use a more powerful model (like gpt-4) to generate a response, it can be tested for correctness — execution test or output test — even by using the same or a lesser model (gpt 3 for instance)
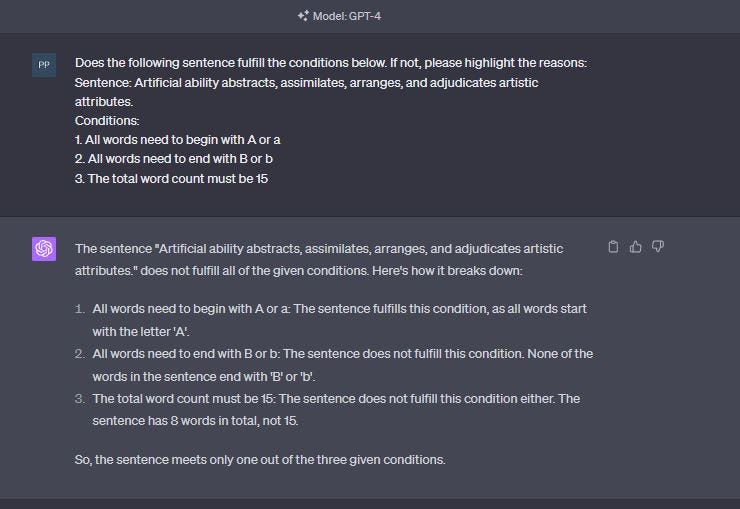
Example: Even a less-powerful model can act as a discriminator
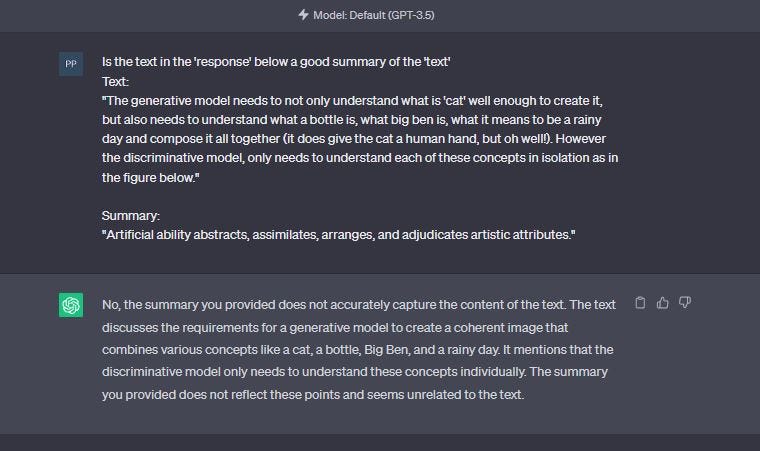
Run time output testing:
These types of tests are useful if the nature of the application or task is not known in advance. For instance, any application that accepts a ‘prompt’ from a user and does work dynamically. — summarize this, convert this to SQL etc.
In these cases, not all is lost. As we can easily use another LLM to design quick correctness tests on the fly. (see below)
This although counterintuitive works well , as discrimination is easier than generation. (details below)

Stage Four: Bug Discovery, Planning, and Iteration
A noteworthy lesson I’ve learned is, “You can test for the presence of a bug but never for the absence of one.” At this stage, it is paramount to interact with the LLM in a more inquisitive and explorative manner. Here, I’ve found it more beneficial to prioritize recall over precision. Here’s how I apply this:
- Use an LLM to generate and test use cases: For each LLM application, I employed an LLM to both produce and test use cases. While these might already be defined in some instances, the creative nature of LLMs can prove advantageous.
- Iterate on test cases: I’ve discovered that LLMs are exceptional partners in summarizing and categorizing information and ideas. This is extremely useful when iterating on the test cases for each use case.
- Repeat or Auto-repeat with a low temperature: Drill down and consistently repeat or automate this process, adjusting with a low-temperature setting for more reliable outputs.
Conclusion
In conclusion, it's still early phases, and things are in flux in the ever-evolving landscape of generative AI and LLMs, but one thing is for sure, the testing process seems to be as vital as development. I hope that these insights from my personal journey are helpful to you in some way.
This article is by far not complete as I haven’t talked about other forms of testing, especially for security around prompt injection, jail breaks, etc. However, that is a different topic.
If you like the article, follow me here and on linkedin and youtube for more. Comment your thoughts.
References
- Open LLM Benchmark (https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
- Langchain Output Parsers
- Pydantic
- Guidance — enables you to control LLM by interleaving generation, prompting, and logical control.
- Metamorphic Testing — property-based software testing framework
- Adaptive Testing and Debugging Language Models
- Auditor by FidderAI
- Metamorphic Testing
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

