



Talk to your documents as PDFs, txts, and even web pages
Last Updated on September 1, 2023 by Editorial Team
Author(s): Damian Gil
Originally published on Towards AI.
Complete guide to creating a web and the intelligence that allows you to ask questions to docs such as PDFs, TXTs, and even web pages using LLMs.
Content Table
· Introduction
· How does it work
· Steps (part 1) U+1F463
· Break: Let’s recap (part 1) U+1F32A️
· Steps (part 2) U+1F463
· Break: Let’s recap (part 2) U+1F32A️
· Web App
· For the impatient one (code)
· Conclusions
· References
Introduction
We all have to read eternal documents to get two sentences containing the value/information we need.
Ever wished you could extract compelling information from a document without getting lost in a sea of words?
Look no further! Welcome to the project “Talking to Documents Using LLM”. It’s like recovering treasures from PDFs, TXT files or web pages without brain fatigue. And don’t worry, you don’t need a tech wizarding degree to have fun. We’ve created a user-friendly interface with Streamlit, so even your non-tech-savvy friends — marketing assistants — can join in.
This article will dive deeper into the theory and code behind application intelligence, shedding light on how web applications work. To give you a quick overview of the technologies we’ll be using, check out the following image that shows the four main tools in action.
And of course, you can find the code in my GitHub repository, or if you want to test the code directly, you can go to the “For the impatient (code)” section.
How does it work
Let’s take a peek through the veil of “Talking to Documents Using LLM”.This project is like an interesting duo: a smart player (back-end) and a user-friendly website (front-end).
- Smart reader: The AI brain reads and understands documents like a super smart friend, excellently handling PDFs, TXTs and web content.
- User-friendly website: User-friendly web interface to configure and interact with the model. It consists of two main pages, each with a specific purpose: Step 1️⃣ Create database and Step 2️⃣ Request documents.
Our project’s outline looks something like this:

Although it may seem complicated, we will simplify every essential step to make it functional. By focusing on the workings of intelligence, we will discover how it works. These steps are supported by the Python TalkDocument class and we will demonstrate each step with the corresponding code to bring it to life.
Steps (part 1) U+1F463
Get ready to explore every step of the way as we discover what makes the magic behind the scenes! U+1F680U+1F50DU+1F3A9
1- Import documents
This step is obvious, right? This is where you decide what type of material you provide. Whether it’s PDF, plain text, web URL or even raw string format, it’s all on the menu.
# Inside the __init__ function, I have commented out the variables
# that we are not interested in at the moment.
def __init__(self, HF_API_TOKEN,
data_source_path=None,
data_text=None,
OPENAI_KEY=None) -> None:
# You can enter the path of the file.
self.data_source_path = data_source_path
# You can enter the file in string format directly
self.data_text = data_text
self.document = None
# self.document_splited = None
# self.embedding_model = None
# self.embedding_type = None
# self.OPENAI_KEY = OPENAI_KEY
# self.HF_API_TOKEN = HF_API_TOKEN
# self.db = None
# self.llm = None
# self.chain = None
# self.repo_id = None
def get_document(self, data_source_type="TXT"):
# DS_TYPE_LIST= ["WEB", "PDF", "TXT"]
data_source_type = data_source_type if data_source_type.upper() in DS_TYPE_LIST else DS_TYPE_LIST[0]
if data_source_type == "TXT":
if self.data_text:
self.document = self.data_text
elif self.data_source_path:
loader = dl.TextLoader(self.data_source_path)
self.document = loader.load()
elif data_source_type == "PDF":
if self.data_text:
self.document = self.data_text
elif self.data_source_path:
loader = dl.PyPDFLoader(self.data_source_path)
self.document = loader.load()
elif data_source_type == "WEB":
loader = dl.WebBaseLoader(self.data_source_path)
self.document = loader.load()
return self.document
Depending on the type of file you upload, the document will be read by different methods. An interesting improvement could involve adding automatic format detection to the mix.
2- Split Type
Now, you may be wondering why the term “type” exists? Well, in the app, you can choose the split method. But before diving into this topic, let’s explain what document splitting is.
Think of it like this: Just as humans need chapters, paragraphs, and sentences to structure information (imagine reading a book with an endless paragraph — yes!), machines need structure too. We need to cut the document into several smaller parts to understand it better. This parsing can be done by character or by token.
# SPLIT_TYPE_LIST = ["CHARACTER", "TOKEN"]
def get_split(self, split_type="character", chunk_size=200, chunk_overlap=10):
split_type = split_type.upper() if split_type.upper()
in SPLIT_TYPE_LIST else SPLIT_TYPE_LIST[0]
if self.document:
if split_type == "CHARACTER":
text_splitter = ts.RecursiveCharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap)
elif split_type == "TOKEN":
text_splitter = ts.TokenTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap)
# If you input a string as a document, we'll perform a split_text.
if self.data_text:
try:
self.document_splited = text_splitter.split_text(text=self.document)
except Exception as error:
print( error)
# If you upload a document, we'll do a split_documents.
elif self.data_source_path:
try:
self.document_splited = text_splitter.split_documents(documents=self.document)
except Exception as error:
print( error)
return self.document_splited
3- Embedding type
We humans can understand words and pictures easily, but machines need a little more guidance. This becomes obvious when:
- We are trying to convert categorical variables in a dataset into numbers
- Image management in neural networks. For example, before an image is fed into a neural network model, it undergoes transformations to become a numerical tensor.
As we can see, mathematical models have the language of numbers. This phenomenon is also seen in the field of NLP, where the concept of word embedding is promoted.
In essence, what we’re doing in this step is converting the splits from the previous stage (document chunks) into numerical vectors.
This conversion or encoding is done using specialized algorithms. It is important to note that this process converts sentences into digital vectors and that this encoding is not random; it follows a structured method.
This code is very simple:
We instantiate the object responsible for the integration. It’s important to note that at this point, we’re just creating an Integration Object. In the next steps, we will do the actual conversion.
def get_embedding(self, embedding_type="HF", OPENAI_KEY=None):
if not self.embedding_model:
embedding_type = embedding_type.upper() if embedding_type.upper() in EMBEDDING_TYPE_LIST else EMBEDDING_TYPE_LIST[0]
# If we choose to use the Hugging Face model for embedding
if embedding_type == "HF":
self.embedding_model = embeddings.HuggingFaceEmbeddings()
# If we opt for the OpenAI model for embedding
elif embedding_type == "OPENAI":
self.OPENAI_KEY = self.OPENAI_KEY if self.OPENAI_KEY else OPENAI_KEY
if self.OPENAI_KEY:
self.embedding_model = embeddings.OpenAIEmbeddings(openai_api_key=OPENAI_KEY)
else:
print("You need to introduce a OPENAI API KEY")
# The object
self.embedding_type = embedding_type
return self.embedding_model
Break: Let’s recap (part 1) U+1F32A️
To grasp the initial three steps, let’s consider the following example:

We start with an input text.
- We do a distribution based on the number of characters (about 50 characters in this example).
- We do integrations, turning text snippets into digital vectors.
How wonderful! U+1F680 Now, let’s start the thrilling journey through the remaining levels. Fasten your seat belts because we’re about to unlock some real tech magic! U+1F525U+1F513
Steps (part 2) U+1F463
We will continue to see the steps to follow.
4- Model VectorerStore Type
Now that we’ve turned our text into code (embedded), we need a place to store them. This is where the concept of “vector store” comes in. It’s like a smart library of these codes, making it easy to find and retrieve similar codes when asking a question.
Think of it as a neat storage space that allows you to quickly get back to what you need!
The creation of this type of database is managed by specialized algorithms designed for this purpose, such as FAISS (Facebook AI Similarity Search). There are other options as well, and currently, this class supports CHROMA and SVM.
This step and the next step share code. In this step, you choose the type of vector repository you want to create, while the next step is where the actual creation takes place.
5. Model VectoreStore (Creation)
This type of database handles two main aspects:
- Vector storage: It stores the vectors generated by the integration.
- Similar calculation: It calculates the similarity between vectors.
But what exactly is the similarity between these vectors and why does it matter?
Well, remember I mentioned that the integration is not random? It is designed so that words or phrases with similar meanings have similar vectors. This way we can calculate the distance between the vectors (like using Euclidean distance) and this gives us a measure of their “similarity”.
To visualize this with an example, imagine we have three sentences.

Two are related to recipes, while the third is related to motorcycles. By representing them as vectors (thanks to integration), we can calculate the distance between these points or sentences. This distance serves as a measure of their similarity.
In terms of code, let’s take a look at the required requirements:
- The split text
- The embedding type
- The vector store model
# VECTORSTORE_TYPE_LIST = ["FAISS", "CHROMA", "SVM"]
def get_storage(self,
vectorstore_type = "FAISS",
embedding_type="HF",
OPENAI_KEY=None):
self.embedding_type = self.embedding_type if self.embedding_type else embedding_type
vectorstore_type = vectorstore_type.upper() if vectorstore_type.upper() in VECTORSTORE_TYPE_LIST else VECTORSTORE_TYPE_LIST[0]
# Here we make the call to the algorithm
# that performed the embedding and create the object
self.get_embedding(embedding_type=self.embedding_type, OPENAI_KEY=OPENAI_KEY)
# Here we choose the type of vector store that we want to use
if vectorstore_type == "FAISS":
model_vectorstore = vs.FAISS
elif vectorstore_type == "CHROMA":
model_vectorstore = vs.Chroma
elif vectorstore_type == "SVM":
model_vectorstore = retrievers.SVMRetriever
# Here we create the vector store. In this case,
# the document comes from raw text.
if self.data_text:
try:
self.db = model_vectorstore.from_texts(self.document_splited,
self.embedding_model)
except Exception as error:
print( error)
# Here we create the vector store. In this case,
# the document comes from a document like pdf txt...
elif self.data_source_path:
try:
self.db = model_vectorstore.from_documents(self.document_splited,
self.embedding_model)
except Exception as error:
print( error)
return self.db
To illustrate what happens in this step, we can visualize the following image. It shows how encoded text fragments are stored in the vector store, allowing us to calculate the distance/similarity between vectors/points.
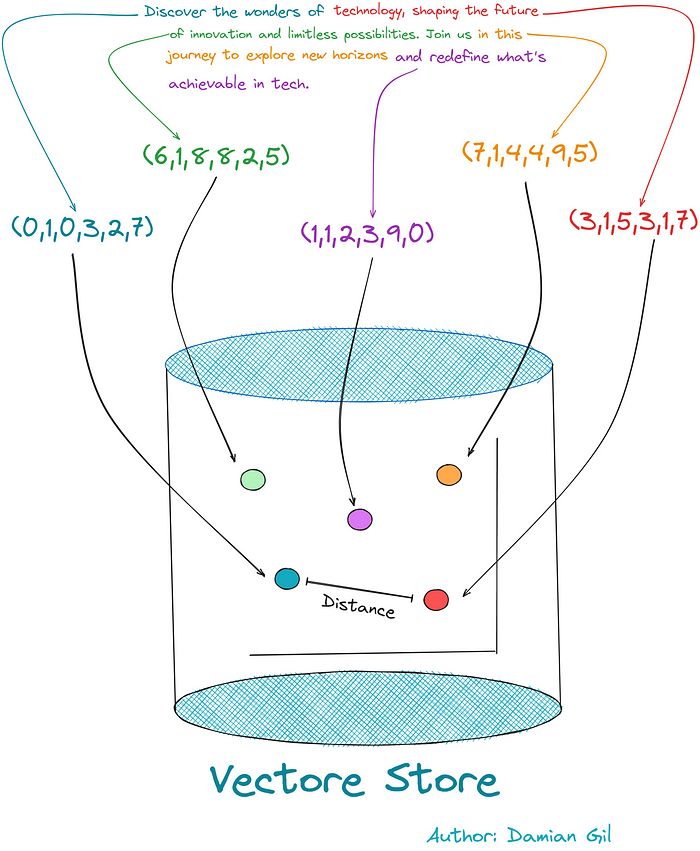
Break: Let’s recap (part 2) U+1F32A️
Great! We now have a database that is capable of storing our documents and calculating the similarity between encrypted text chunks. Imagine a situation in which we want to encode an external sentence and store it in our vector store. This will allow us to calculate the distance between the new vector and the document split. (Note that here the same integration should be used to create the vector store.) We can visualize this through the following image.

Remember the previous picture… we have two questions, and we turn them into numbers using integration. We then measure the distance and find the closest sentences to our question. These sentences are like perfect combinations! It’s like finding the best puzzle piece in an instant! U+1F680U+1F9E9U+1F50D
6- Question
Remember that our goal is to ask a question about a document and get an answer. In this step, we collect the questions as user-supplied input.
7 & 8- Relevant Splits
This is where we insert our question into the vector repository, embedding it to turn the sentence into a digital vector. We then calculate the distance between our question and the parts of the document, determining which parts are closest to our question. The code is:
# Depending on the type of vector store we've built,
# we'll use a specific function. All of them return
# a list of the most relevant splits.
def get_search(self, question, with_score=False):
relevant_docs = None
if self.db and "SVM" not in str(type(self.db)):
if with_score:
relevant_docs = self.db.similarity_search_with_relevance_scores(question)
else:
relevant_docs = self.db.similarity_search(question)
elif self.db:
relevant_docs = self.db.get_relevant_documents(question)
return relevant_docs
Try it with the code below. Learn how to answer as a list of 4 items. And when we look inside, it’s actually separate parts of the document you entered. It’s like the app that presents you with the best 4 puzzle pieces that fit your question like a glove! U+1F9E9U+1F4AC
9- Response (Nature Language)
Great, now we have the most relevant text for our question. But we can’t just hand those parts over to the user and terminate it. We need a concise and precise answer to their question. And that’s where our Language Model (LLM) comes into play! There are many LLM flavors. In the code, we set “flan-alpaca-large” as default. Don’t hesitate to choose the person you are most touched by! U+1F680U+1F389
Here is the plan:
- We restore the most important parts (splits) related to the question.
- We prepare a prompt that includes the question, how we want the answer, and those text elements.
- We pass this prompt to our Intelligent Language Model (LLM). He knows the question and the information contained in these elements and gives us natural answers.️
This last part is shown in the following image: U+1F5BC️

Sure enough, this exact flow is what gets executed in the code. You’ll notice in the code there’s an extra step involved in creating a “prompt”. Indeed, we can come up with a final answer that is a combination of the answers found by the LLM and other choices. For simplicity, let’s do it the simplest way: “stuff”. This means that the answer is the first solution found by the LLM. Here, you don’t get lost in theory! U+1F31F
def do_question(self,
question,
repo_id="declare-lab/flan-alpaca-large",
chain_type="stuff",
relevant_docs=None,
with_score=False,
temperature=0,
max_length=300):
# We get the most relevant splits.
relevant_docs = self.get_search(question, with_score=with_score)
# We define the LLM that we want to use,
# we must introduce the repo id since we are using huggingface.
self.repo_id = self.repo_id if self.repo_id is not None else repo_id
chain_type = chain_type.lower() if chain_type.lower() in CHAIN_TYPE_LIST else CHAIN_TYPE_LIST[0]
# This check is necessary since we can call the function several times,
# but it would not make sense to create an LLM every time the call is made.
# So it checks if an llm already exists inside the class
# or if the repo_id (the type of llm) has changed.
if (self.repo_id != repo_id ) or (self.llm is None):
self.repo_id = repo_id
# We created the LLM.
self.llm = HuggingFaceHub(repo_id=self.repo_id,huggingfacehub_api_token=self.HF_API_TOKEN,
model_kwargs=
{"temperature":temperature,
"max_length": max_length})
# We create the prompt
prompt_template = """Use the following pieces of context to answer the question at the end.
If you don't know the answer, just say that you don't know, don't try to make up an answer.
If the question is similar to [Talk me about the document],
the response should be a summary commenting on the most important points about the document
{context}
Question: {question}
"""
PROMPT = PromptTemplate(
template=prompt_template, input_variables=["context", "question"]
)
# We create the chain, chain_type= "stuff".
self.chain = self.chain if self.chain is not None
else load_qa_chain(self.llm,
chain_type=chain_type,
prompt = PROMPT)
# We make the query to the LLM using the prompt
# We check if there is a chain already defined,
# if it does not exist it is created
response = self.chain({"input_documents": relevant_docs, "question": question}, return_only_outputs=True)
return response
You’ve rocked it, reaching the end of understanding how the brain of our web app works. High-five if you’re here! Now, let’s dive into the final stretch of the article, where we’ll explore the web app’s pages. U+1F389U+1F575️U+2642️
Web App
This interface is designed for people without technical knowledge, so you can get the most out of this technology without any problems. U+1F680U+1F469U+1F4BB
Using the site is extremely simple and powerful. Basically, the user just needs to provide the document. If you are not ready to benefit from additional parameters, in the next step, you may already start asking questions. U+1F31FU+1F916
Let’s see the steps to follow:
- Provide the document or web link. By page Step 1️⃣ Create Data Base.
- Set up the configuration (optional). By page Step 1️⃣ Create Data Base.
- Ask your questions and get answers! U+1F4DAU+1F50DU+1F680 By page Step 2️⃣ Ask to the document.
1. Provide the document or web link.
In this step, you add the document by uploading it to the web. Remember that if you don’t have the Face Hugging API key as an environment variable, the “home” tab will ask you to enter it. U+1F4C2U+1F511
Once you’ve attached the document and set up your preferences, a summary table of your configuration is displayed. The “Create Database” button is then unlocked. When you click the button, the database or vector store will be created, and you’ll be redirected to the question section. U+1F4D1U+1F512U+1F680

2. Set up the configuration (optional).
As I mentioned earlier, we can configure the vector store according to our preferences. There are different methods for splitting documents, embedding, and more. This tab allows you to customize it as you like. It comes with a default configuration for faster setup. U+2699️U+1F6E0️

3. Ask your questions and get answers!
At this point, you can start making all the queries you want. Now it’s time to enjoy and interact with the tool to your heart’s content! U+1F917U+1F50DU+1F4AC

For the impatient one (code)
For those who are eager to dive in, you can directly grab the TalkDocument class and paste it into a Jupyter notebook to start tinkering. You might need to install a few dependencies, but I’m sure it won’t be a challenge for you. Have a great time exploring and experimenting! Happy coding!! U+1F680U+1F4DAU+1F604
Conclusions
Congratulations on making it this far in our exciting journey! We’ve delved into how the intelligence behind this web application works. From uploading documents to obtaining answers, you’ve covered a lot of ground! If you’re feeling inspired, the code is available in my GitHub repository. Feel free to collaborate and reach out to me on LinkedIn for any questions or suggestions! Have fun exploring and experimenting with this powerful tool!
If you want, you can check my GitHub
damiangilgonzalez1995 – Overview
Passionate about data, I transitioned from physics to data science. Worked at Telefonica, HP, and now CTO at…
github.com
References
- Langchain documentation
- Hugging Face Documentation
- Introduction to Facebook AI Similarity Search (Faiss)
- Steamlit Documentation
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

