



Tackle COVID detection with Lightning Flash and IceVision
Last Updated on January 7, 2023 by Editorial Team
Last Updated on October 9, 2021 by Editorial Team
Author(s): イルカ Borovec
Deep Learning
Tackling the Kaggle COVID Detection Challenge with Lightning Flash and IceVision
This post walks through how we approached the Kaggle SIIM-FISABIO-RSNA COVID-19 Detection challenge using Lightning Flash and its new support for IceVision's rich collection of models and backbones.
Object Detection is a Computer Vision task that aims to detect and classify individual objects in a scene or image. There are various model architectures for Object Detection, but the two most common are region proposal (e.g. Fast/Faster RCNN) and one-shot detection (e.g. SSD, YOLO).
The Lightning Flash team recently released a new exciting integration with the IceVision Object Detection library that enables dozens of new state-of-the-art backbones that can be fine-tuned and inference just a few lines of code.
Object Detection – Flash documentation
We participated in the Kaggle: COVID19 detection/classification challenge to showcase the new integration, which presents a realistic and challenging dataset of CT scans from over six thousand patients.
Checkout our Kaggle kernel — COVID detection with Lightning Flash ⚡️
Covid detection with Lightning Flash ⚡️
All code snapshots and visualizations are part of this sample repository and can be installed as pip install https://github.com/Borda/kaggle_COVID-detection/archive/refs/heads/main.zip
COVID Detection Challenge
The recent Kaggle: COVID19 detection/classification aims to facilitate medical screening and eventually assist medical experts/doctors with making diagnoses. The challenge is a hybrid image classification/ object detection task. First, you need to identify whether a given CT scan has one of four abnormalities and then provide a collection of bounding boxes indicating where the abnormalities are present to justify the diagnosis.
While the task is presented as a hybrid Detection and Classification task, it can also be modelled as a traditional object detection problem where the image class is determined by the aggregation of the majority class of the detected abnormalities.
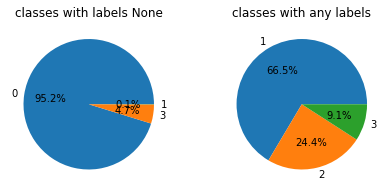
A Study represents a unique anonymized patient with a single Computed Tomography (CT) scan. A single DICOM image should represent each scan. It is important to note that some annotated images were accidentally incompletely labelled. These images and their annotations were later duplicated and fixed, as discussed in this thread. As part of the challenge, incomplete annotations and duplicate images need to be filtered out of the dataset before training.
The annotations are stored in two separate CSV tables. The first table contains a one-hot encoding representing the abnormality class of each image and the second table contains a list of all the bounding boxes, if any, in the images.
Loading DICOM images with annotations
The CT scans are provided in a DICOM file, including a header with some metadata and the compressed image bitmap.
For loading image data, we use the pydicom package, see the following sample code how to do it:
After loading images, we merged the two annotation tables by Study ID. The code above displays a few examples scans from each class and draws bounding boxes if they are available in the metadata:
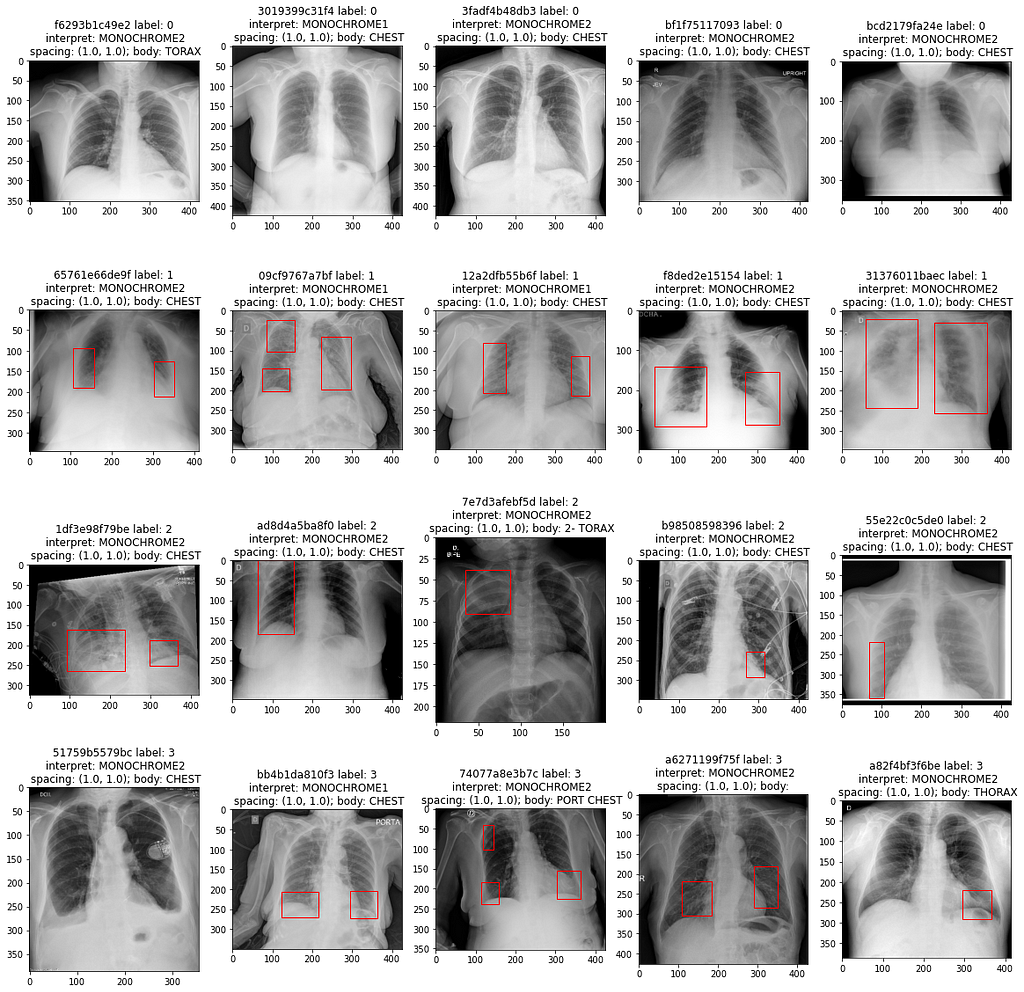
As expected, there are no bounding boxes in negative scans. More interestingly, most of the positive scans contain more than one detection per scan.
Additional observation on a relation between detections and labels
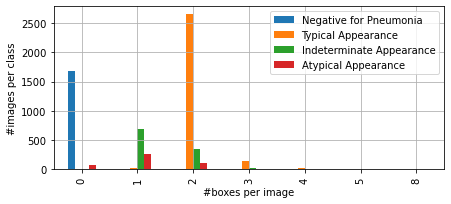
Let's take a look at the dataset from the perspective of counting annotated bounding boxes. As you can see from the samples per class, there are some positive cases without any COVID-19 detections.
The figure below shows how many bounding boxes there are in each image per a given class. Eventually, this observation can be used in the final aggregation heuristic.
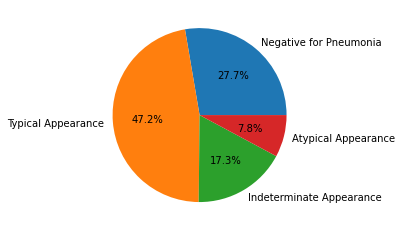
The pie charts below show the distribution of annotated abnormalities across the different studies. As expected, there are no negative studies containing bounding box annotations.
However, 5% of the images containing abnormalities are missing bounding box annotations. This means that while we can estimate a given image class using object detection, these noisy images will make it challenging to model the task perfectly with this approach which explains why many used a hybrid image classification/object detection approach.
Flash Baseline with EfficientDet
Flash is an AI Factory for fast prototyping, baselining, fine-tuning, and deep learning solving business and scientific problems. It is built on top of the powerful Pytorch Lightning library to facilitate training at scale.
In Flash Object Detection, models are initialized with two key arguments Backbone and Head, which comes from the model architecture/composition:
- Backbone — pre-trained classification networks such as ResNet50, EffieientNet are used for feature extraction in object detection models.
- Head — defining the architecture of the Object Detector such as Faster-RCNN, RetinaNet, etc.
Object Detection – Flash documentation
Let's look at the EfficientDet head's schema to understand these arguments better, using an EfficientNet backbone.
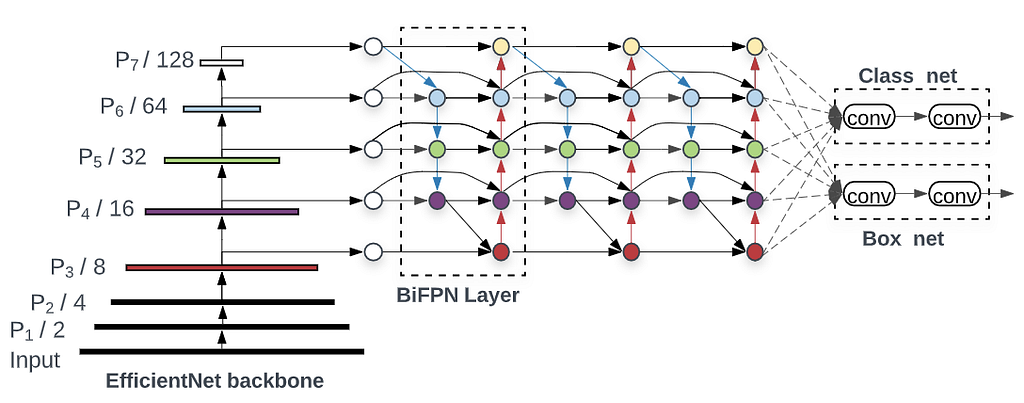
With Flash, we only need a few lines of code to fine-tune state-of-the-art methods like EfficientDet on our competition dataset. All you need to do is converting the Kaggle object detection labels to the COCO format, setting a model and training parameters, and start training…
1. Convert Dataset to COCO format
Working with perfect annotations in practice is quite rare, and often it only occurs in standard/benchmarking datasets. The IceVision and Flash integration currently use the COCO dataset format. The COCO format is comprised of a folder with raw images and a JSON annotation file, which contains the following metadata:
- Relative image paths and sizes for each image in the dataset
- A list of bounding boxes and their class indexes for each image
- A mapping between bounding box class indexes and labels
In COCO, a bounding box comprises the coordinates of the top right corner and the width and height of the bounding box within the image. We need to write a custom script that does this conversion from competition annotation to the COCO format. These steps are described in the provided notebook, and the code can be found in the provided repository.
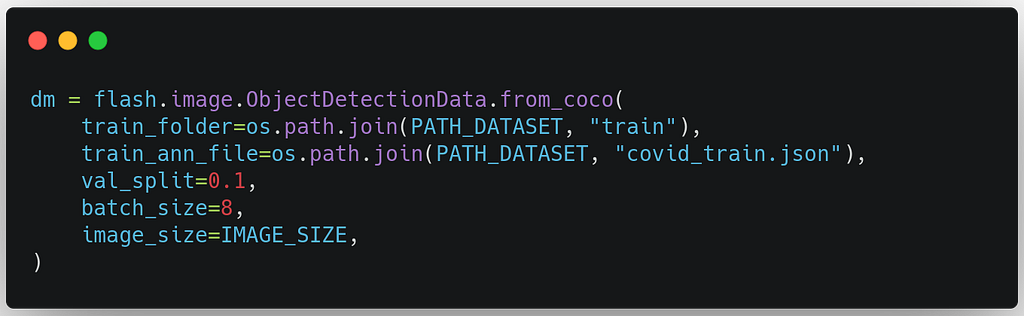
2. Create the DataModule
In Flash, the from_coco the method loads the COCO images and annotation file created in the last step. We can provide abatch_size to fully utilize our GPU and an image_size to resize our images for our model.
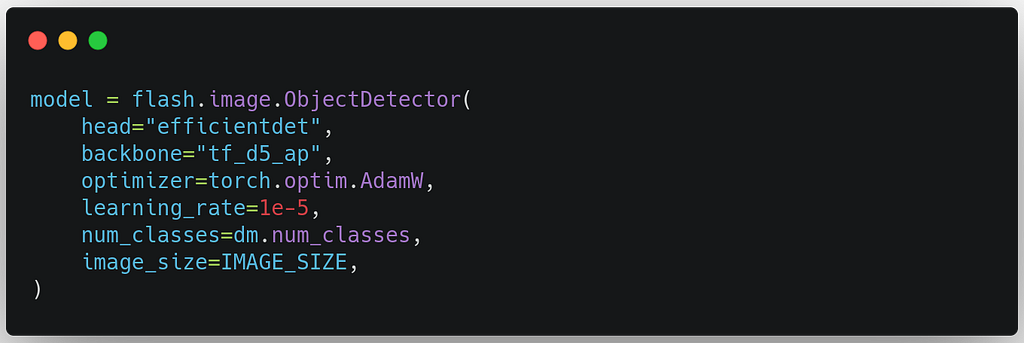
3. Build the Task
To build the Object Detection Task, we select model backbones. In this example, we use a state-of-the-art EfficientDet with an EfficientNet D5 backbone. The learning rate we experimentally set to 1e-5, we can optimize this value using a hyper-parameter search.
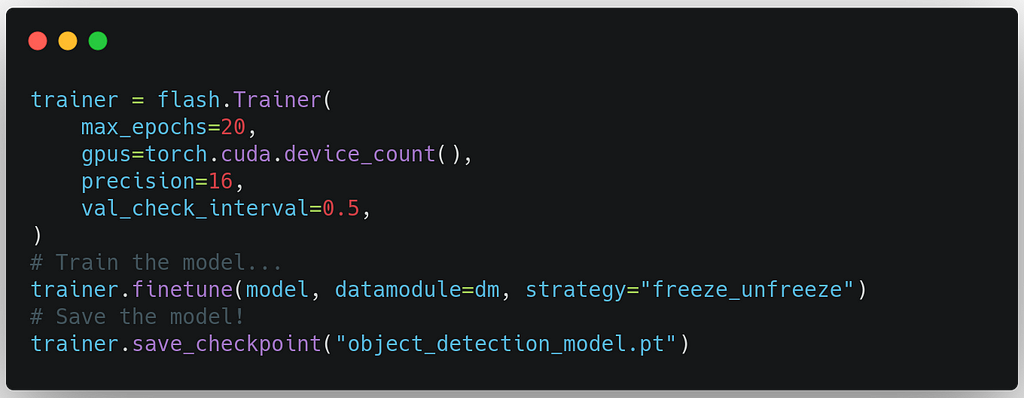
4. Create the Trainer and Fine-tune the model
Flash's Trainer inherits from the Lightning’s Trainer, enabling us to leverage all the trainer flags we know and love efficiently. To train, we use method finetune, which takes an argument strategythat configures the fine-tuning process. For example, thefreeze_unfreeze strategy below freezes the backbone for the first 10 epochs to update only the head and then expands training to the entire model.
Using the built-in Tensorboard logger, we can observe the training process in real-time and see how the training loss decreases.
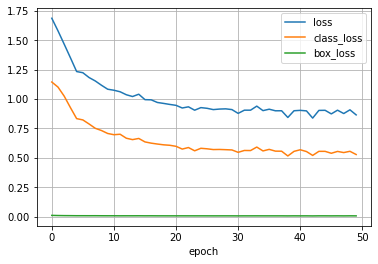
At the end of the training, we save the fine-tuned model so that we can make inferences.
5. Load model and Run predictions
Now we have a trained model. It's time to evaluate our model's performance. The code below shows a simple use-case of how Flash can load pre-trained models from a file and predict on test dataset:
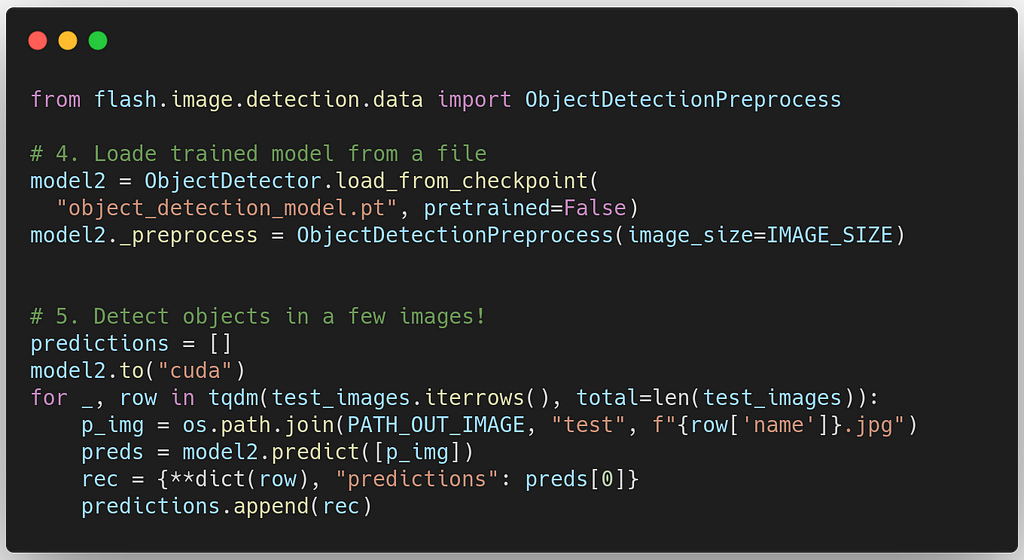
There you have it; in the post, you learned how to
- Perform Exploratory Data Analysis on Object Detection datasets.
- Train end-to-end state-of-the-art Object Detection models with Flash and IceVision.
- Evaluate trained models to generate a Kaggle Submission for the Kaggle: COVID19 detection/classification challenge.
Stay tuned for the following stories With Lightning and Flash!
Flash 0.5 — Your PyTorch AI Factory!
About the Author
Jirka Borovec holds a Ph.D. in Computer Vision from CTU in Prague. He has been working in Machine Learning and Data Science for a few years in several IT startups and companies. He enjoys exploring interesting world problems and solving them with State-of-the-Art techniques, and developing open-source projects.
Tackle COVID detection with Lightning Flash and IceVision was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

