



Summertime Sadness ft. PandasAI: Deep-Dive
Last Updated on July 17, 2023 by Editorial Team
Author(s): Soumyadip Mal
Originally published on Towards AI.
PandasAI — a potential game-changer for Data Engineers or just a gimmick? Let’s find out!
Spent the entire day with this nifty little library, dismantled it bit by bit, and, here are my 2 cents on it.
I’m not particularly good at prose-so I’ll just approach my first “tech blog”, the way I know – without any frills. Also, it’s well past 3 am at the time of writing this, so you know. First things first:
1) What Kind of LLMs fuelling it? OpenAI-based models, Huggingface LLM(falcon), Starcoder and the PALM suit of models from Google. Have solely tried with OpenAI for now. For OpenAI, the defaults are:
‘temperature’: 0,
‘max_tokens’: 512,
‘top_p’: 1,
‘frequency_penalty’: 0,
‘presence_penalty’: 0.6,
‘model’: ‘gpt-3.5-turbo’
2)Is it free? The base usage remains free of course, but the conversational flavor with OpenAI LLM would require an API key and hence comes at a cost, the cost of GPT3.5, to be precise.
3)Under the hood — At a very abstract level, it can either work with single dataframes or a single list of DataFrames. Taking the example of a single data frame, it takes into consideration only the head with 5 rows. Internally forms a hardcoded prompt and sends it through the chat completion endpoint to get the Python code representation of the input query/question. And then, it runs the Python code on the entire of the original dataframe to get the desired result. The underlying assumption here being-you don't really need to see the entire dataset to form a general query; the column names are quite enough. Also, this saves on the token usage front. As simple as that.
4)Data Privacy? There’s an option to init call with “enforce_privacy” flag set to False, so that the df.head() doesn’t show up in the prompt. And since it doesn’t upload your entire table anyway, just the headers only, there shouldn’t be any concern related to data privacy.
5)Is the output conversational? Yes, there’s another init argument called “conversational” that defaults to false but can be set to True to give a more conversational type of answer.
6) Middleware? Those coming from Django would be aware of this, something that we used to do with monkey-patching in yesteryears. PandasAI also supports sending in a list of middleware classes as input param.
Diving In:
Working with a single dataframe —
With conversational=True(set the token in line 15 as your API key)
With conversational=False(set the token in line 15 as your API key)

Prompts formed under the hood for the default non-conversational flavor with single df, with enforce_privacy set to False:
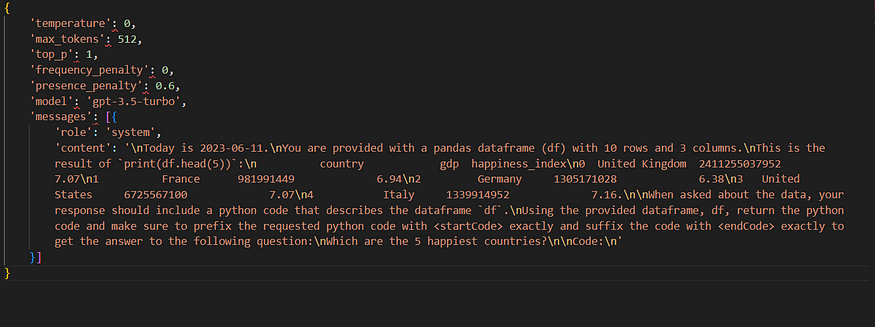
Prompts formed under the hood for the default non-conversational flavor with single df, with enforce_privacy set to True:

As visible, only the col. names are there in the prompt with the privacy turned on, actual data is discarded.
Working with a list of dataframes —
Notice the additional data frame in line 14, which is being passed in a list along with the original df in line 28. Have intentionally removed the happiness index col from the new df and modified the GDP of the United States. Also, the query now says “USA” instead of “United States”. Here in lies the magic of LLMs, it was able to still form the query.
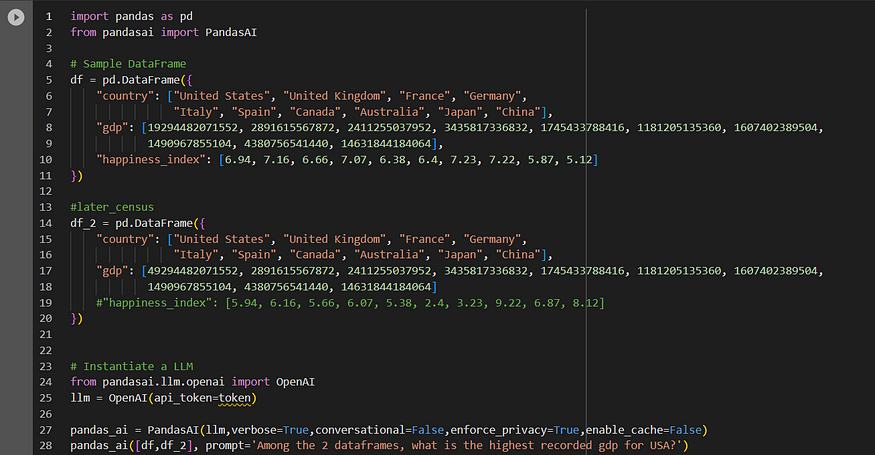
Prompts formed with enforce_privacy set to True:

Prompts formed with enforce_privacy set to False:
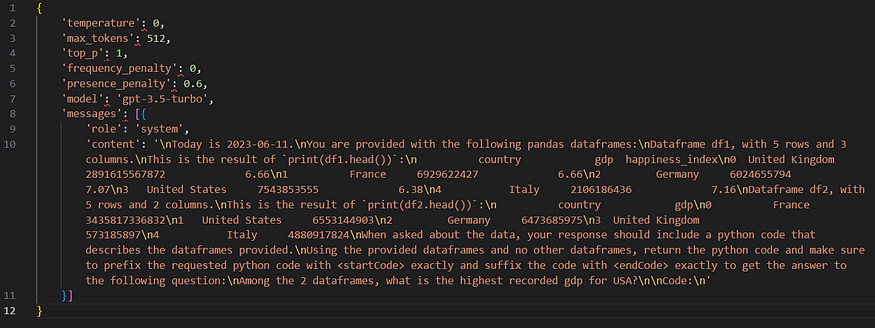
The privacy thing failed for multiple df’s due to a small bug in the code (I have sent a pull request, let’s see).
Optimisation Proposed:
Leaving aside the multiple df case for now. For single df, with privacy enabled, prompts are a little shorter(owing to the lack of example data from the head) and thus less costly, but for the sake of better prompting practice, let’s keep it set to False for now.
pandas_ai = PandasAI(llm,verbose=True,conversational=False,enforce_privacy=False,enable_cache=False)
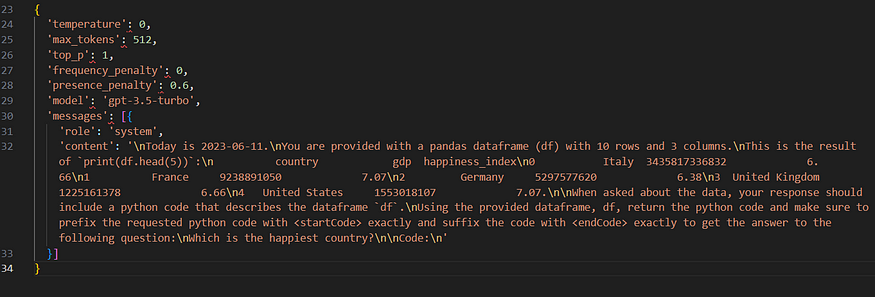
Input df:

Input query: Which is the happiest country?
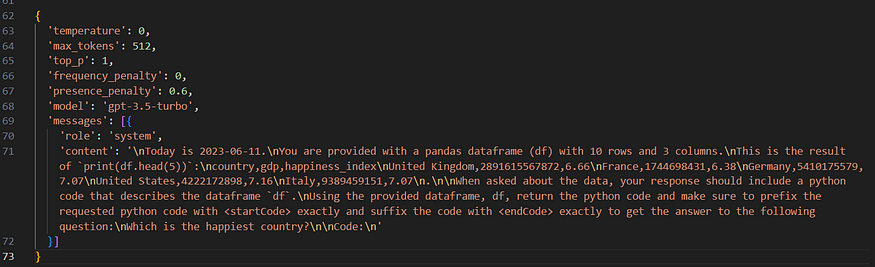
Input request body: (Clearly, has way too many new line characters and other special chars, that contribute to the token-count and essentially, the cost incurred for each api call)
Response

So, 376 total tokens for a df with 10 rows and 3 cols. GPT3.5-Turbo is priced at $0.002 / 1K tokens. So, for 10,000 such hits, we’d get around 3760k tokens and it could cost us 7.52 USD.
However, if we slightly tweak the input prompt to hold the df in the form of a comma-separated format(csv) instead of a string representation of the head(5), here’s what happens:
Input request body:(Notice the comma separated fields)
So much more compact.
Response:

So, a total of 340 tokens. That’s a 9.5% cost reduction overall!
For now, have just made the change for the single data-frame input. Will put in a PR for the multi-df list too.
Well, that was it, folks. Will try to spend some time with Scikit-LLM next. I quite liked the idea here, just send the df skeleton to LLM and get the pandas equivalent code, and then run it on the actual dataset for the result. Text to SQL and vice-versa have been there for a while; this just takes it up a notch — Text to Pandas. This also opens up a lot of other avenues — SQL query optimization, performance tuning of code, etc. Now, pandas query optimization could very well be a thing too! Other Python libs, I imagine, would follow this trend too.
— . — — — — -.. -… -. — . ( Morse for something, idk)
Thanks for reading!
Your feedback and questions are highly appreciated. You can find me on LinkedIn and Instagram or connect with me via Twitter @soumyadip_mal
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts
")



")


