


Stacking and Splitting NumPy Arrays Like a Pro: Part 2
Last Updated on July 17, 2023 by Editorial Team
Author(s): Devansh Sheth
Originally published on Towards AI.
Read this guide and split those NumPy arrays like a Ninja!
NumPy is one of the most important libraries for Data Science and working with numerical data. Mastering how to work with numpy arrays is mandatory for any Data Scientist. This is the second part of 2 part series in which I explain in detail how to stack and split NumPy arrays. You can read the part of this series here:
Stacking and Splitting NumPy arrays like a Pro: Part 1
Understand how to stack NumPy arrays in the first part of this 2 part series.
devsheth09.medium.com
The above article was also published on hackernoon here
This article assumes the basic knowledge of working with NumPy, so I won’t go into much detail about that. If not, I recommend to give the following article a read and then continue with this article.
A comprehensive guide to get you started with NumPy
Learn the basics of NumPy through this guide.
devsheth09.medium.com
Table of Contents
- What is numpy.array_split
- Splitting in 1D
- Splitting row-wise vs column-wise
- Understanding hsplit and vsplit functions
- Conclusion
Before I go ahead with how to split numpy arrays, let me first explain why we need to split the numpy arrays. One of the main reasons could be that we need to split the dataset into feature columns and target column when training our machine learning model. Or we need to remove a specific column from our dataset for feature engineering purposes. We might also need to split our dataset into training and testing datasets.
Alright, now that you have understood the why, it’s time to see how to do this.
What is numpy.array_split?
The numpy.array_split method is used to split the numpy array that we specify into equal-sized or almost equal-sized sub-arrays. If the array does not have enough elements to split into equal sized sub-arrays, then it has the ability to adjust from the end accordingly. We will see this in action in examples given below.
The parameters of numpy.array_split are:
- array (mandatory) — numpy array to be divided into sub-arrays.
- indices or sections (mandatory) — This allows us to pass either an integer value or a 1D array of integers.
- If the value is an integer A, the array is divided into A equal sized or almost equal sized sub-arrays.
- If it is a 1D array, then the sub-arrays are created based on the indices passed here.
- axis (optional) — The axis along which we want to split the array. This value is optional and if nothing is passed then it defaults to 0.
Splitting a 1D array
Let’s understand splitting a numpy array with array_split function. For this we will need to pass the source array that we want to split and the number of sub-arrays we want from it.
>>> import numpy as np
>>> array1 = np.array([1, 2, 3, 4, 5, 6])
# Splitting this array into 3
>>> new_array = np.array_split(array1, 3)
# This returns a list of numpy arrays
>>> new_array
[array([1, 2]), array([3, 4]), array([5, 6])]
Now what happens if the number of elements in the source array is not divisible by the number of sub-arrays we want. In other words, if it is not possible to have equally sized sub-arrays.
In such cases, we will have almost equal sized sub-arrays with elements in sub-arrays adjusted towards the end. Let me explain this better with an example.
>>> array2 = np.array([1, 2, 3, 4, 5, 6, 7])
# We will split the above array into 3
>>> new_array2 = np.array_split(array2, 3)
# Here you can see that it adjusts the elements in the last 2 sub-arrays.
>>> new_array2
[array([1, 2, 3]), array([4, 5]), array([6, 7])]
p# Let's understand this better with another example.
>>> array3 = np.array([1, 2, 3, 4, 5, 6, 7, 8])
>>> new_array3 = np.array_split(array3, 3)
>>> new_array3
[array([1, 2, 3]), array([4, 5, 6]), array([7, 8])]

In the above example, when we divide an array with 8 elements into 3 sub-arrays. It first takes 3 elements for the first 2 sub-arrays. Then for the last one, it adjusts it to have only 2 elements.
This is where numpy.array_split method trumps the numpy.split method. If we had used numpy.split method here for the last 2 examples, it would have thrown error for 8 elements not being divisible into 3 sub-arrays.
Splitting in 2D
After making ourselves familiar with splitting a 1D numpy array, it’s time to understand how we can split a 2D array and also understand how we can split row-wise and column-wise.
So, how do we split a 2D numpy array?
First let’s see the default behavior when we don’t specify the axis parameter.
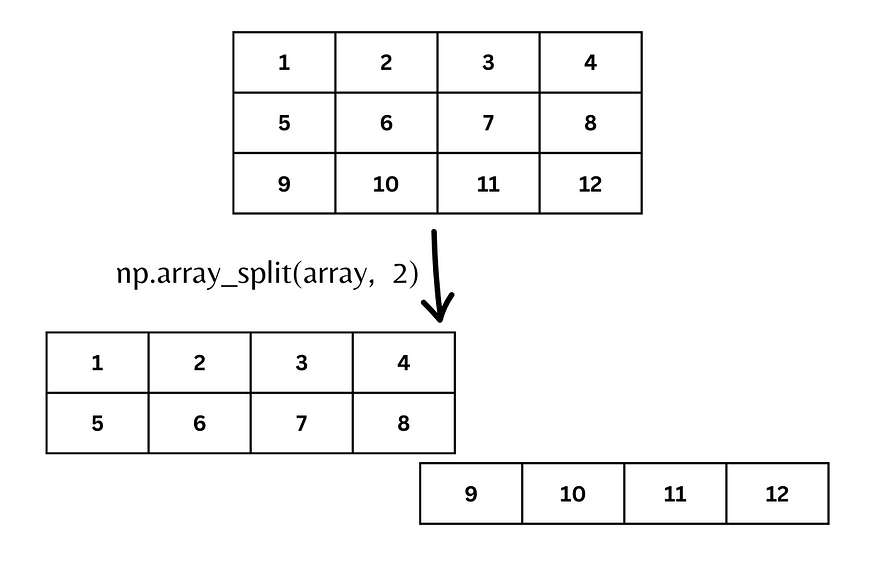
If we don’t specify the axis, it defaults to 0 which means row-wise.
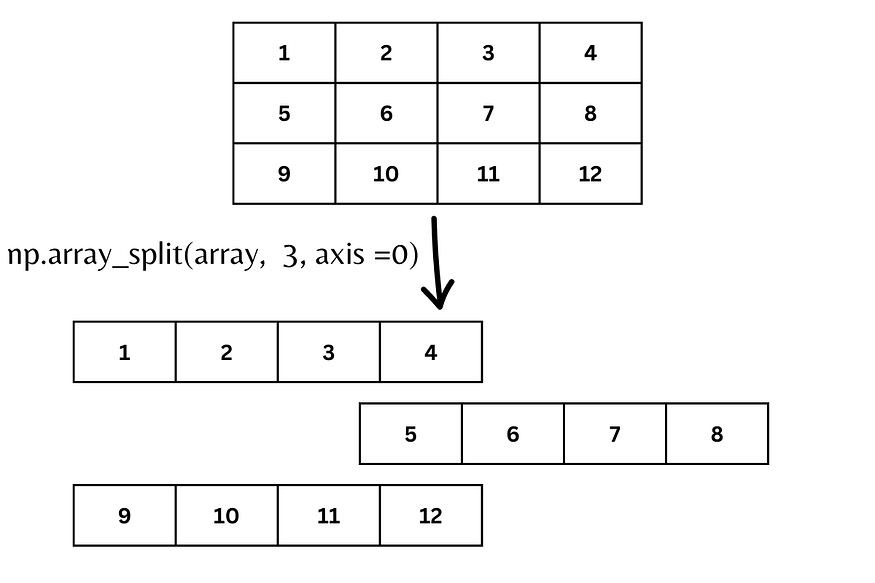
What if we need to split the array into 2 parts in such a way that half of the columns in 1 part and other half into another part.
For that here’s what we need to do.

Even though the axis value defaults to 0, whenever we want to split row-wise, it is advisable to mention axis=0.
numpy.hsplit() and numpy.vsplit()
To help us work with arrays having more than 1 dimension, NumPy also provides hsplit and vsplit functions. Both these functions take 2 arguments, the array that we want to split and the number of sub-arrays we want.
Let us see them in action with an example.
First we will see hsplit. And we will create 2 sub-arrays.
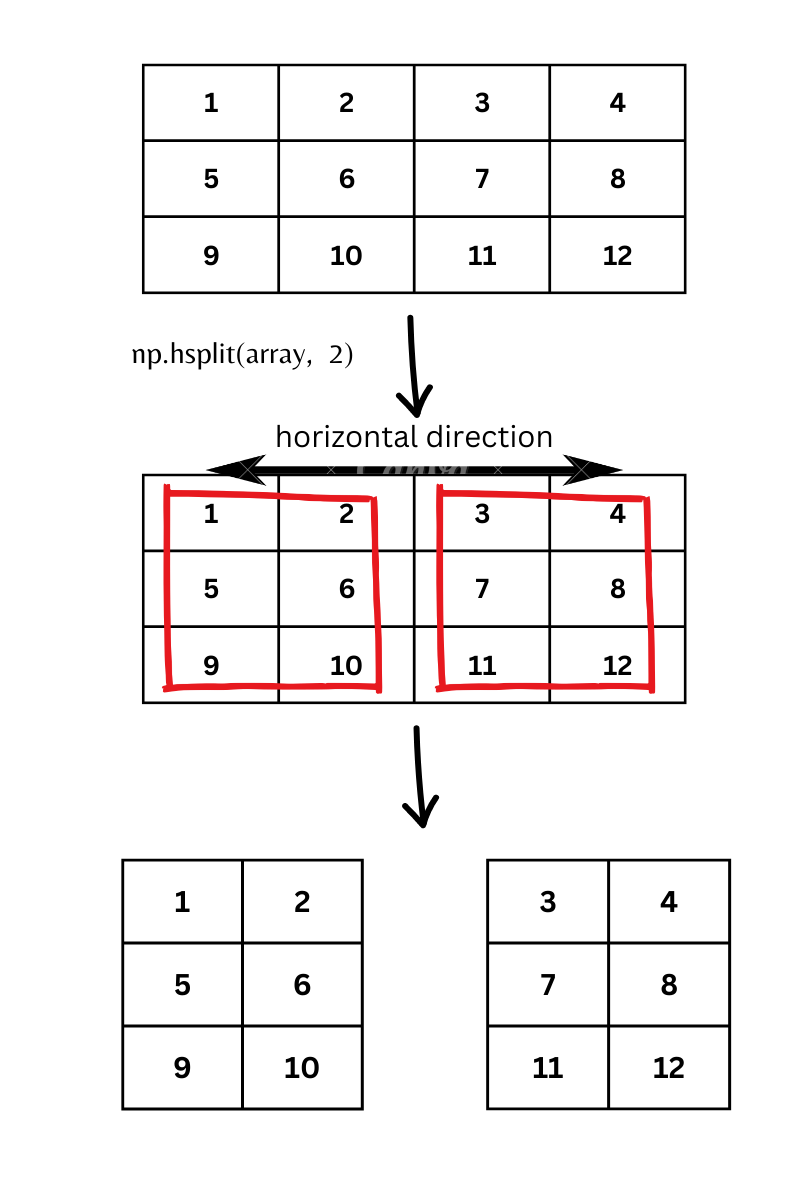
While working with numpy.hsplit we need to be careful that the split results in equal sized sub-arrays. Else it is going to throw an error saying ‘array split does not result in equal division.’
# We will try to split the above array horizontally into 3 sub-arrays.
>>> arr = np.array([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
>>> newarr = np.hsplit(arr, 3)
# The output will return following error.
ValueError: array split does not result in an equal division
Now, we will see vsplit. It look in vertical direction and then splits along that direction.
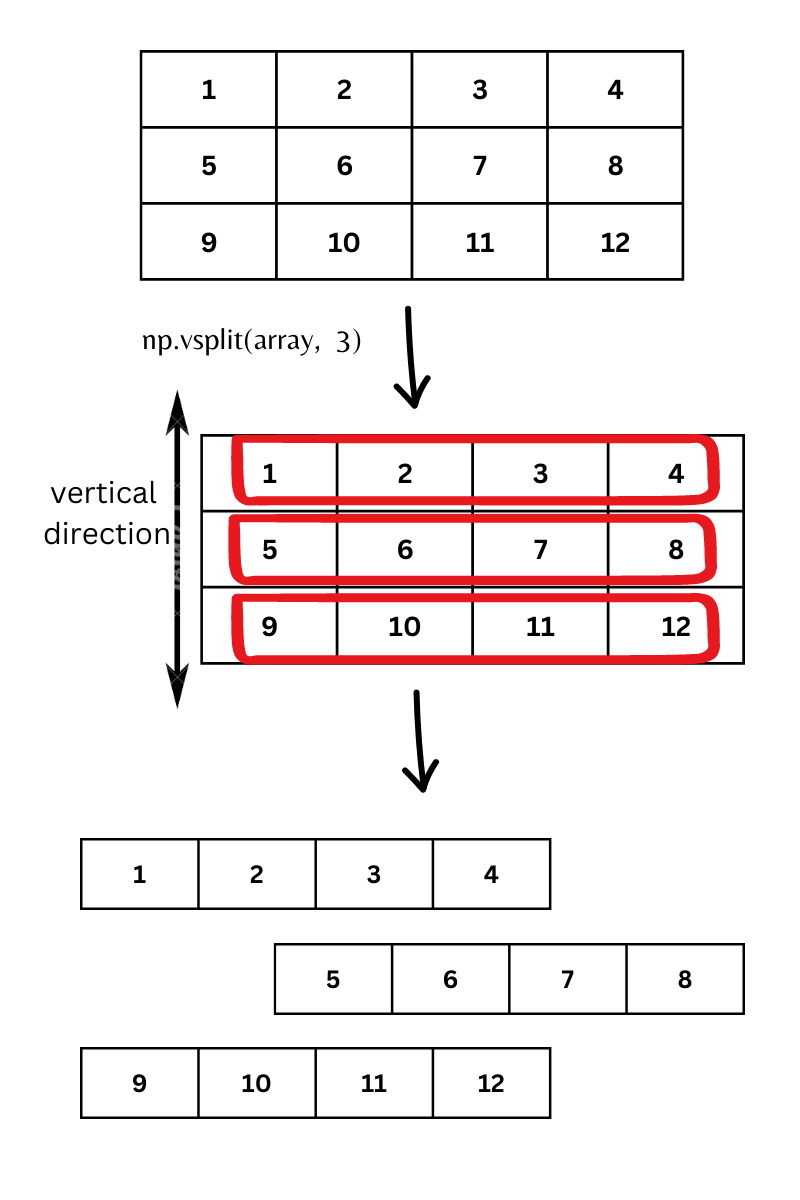
The thing with hsplit and the need to ensure equal sized sub-arrays stays true for vsplit also. So in case we need to split a 2D numpy array where there can be unequal sized sub-arrays, it is better to go with array_split and use axis parameter.
# We will try to do the same operation that we did earlier with hsplit but now
# we will use array_split with axis = 1.
>>> arr = np.array([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
>>> newarr = np.array_split(arr, 3, axis=1)
>>> newarr
[array([[ 1, 2],
[ 5, 6],
[ 9, 10]]),
array([[ 3],
[ 7],
[11]]),
array([[ 4],
[ 8],
[12]])]
This completes the operation without any error and return almost equally sized sub-arrays.
Conclusion
To conclude the article, let’s recap what we covered.
- First we understood what is numpy.array_split.
- Then we split a 1D array.
- After that we split the array in 2D.
- Then we understood how to split an array row-wise and column-wise.
- In the end we covered hsplit and vsplit functions.
And that concludes the 2 part series on Stacking and Splitting a NumPy array.
Thanks for reading! Make sure to follow to read upcoming articles on NumPy, Pandas, SQL and all things related to Data Science.
Connect with me: LinkedIn
Checkout my other projects: Github
Follow me on Medium
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

